Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Для новых пользователей первый месяц бесплатно. Чат-бот для мастеров и специалистов, который упрощает ведение записей: — Сам записывает клиентов и напоминает им о визите;
— Персонализирует скидки, чаевые, кэшбэк и предоплаты;
— Увеличивает доходимость и помогает больше зарабатывать; Начать пользоваться сервисом

Оценка информативности признаков
|
|
Оценка информативности признаков необходима для их отбора при решении задач распознавания. Сама процедура отбора практически не зависит от способа измерения информативности. Важно лишь, чтобы этот способ был одинаков для всех признаков (групп признаков), входящих в исходное их множество и участвующих в процедуре отбора. Поскольку процедуры отбора были рассмотрены в разделе, посвящённом детерминистским методам распознавания, здесь мы на них останавливаться не будем, а обсудим только статистические методы оценки информативности.
При решении задач распознавания решающим критерием является риск потерь и как частный случай – вероятность ошибок распознавания. Для использования этого критерия необходимо для каждого признака (группы признаков) провести обучение и контроль, что является достаточно громоздким процессом, особенно при больших объёмах выборок. Именно это и характерно для статистических методов. Хорошо, если обучение состоит в построении распределений значений признаков для каждого образа 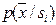 . Тогда, если нам удалось построить
. Тогда, если нам удалось построить 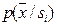 в исходном признаковом пространстве, распределение по какому-либо признаку (группе признаков) получается как проекция на соответствующую ось (в соответствующее подпространство) исходного признакового пространства (маргинальные распределения). В этом случае повторных обучений проводить не нужно, следует лишь оценить вероятность ошибок распознавания. Это можно осуществить различными способами. Рассмотрим некоторые из них.
в исходном признаковом пространстве, распределение по какому-либо признаку (группе признаков) получается как проекция на соответствующую ось (в соответствующее подпространство) исходного признакового пространства (маргинальные распределения). В этом случае повторных обучений проводить не нужно, следует лишь оценить вероятность ошибок распознавания. Это можно осуществить различными способами. Рассмотрим некоторые из них.
Если имеются обучающая и контрольная выборки, то первая из них используется для построения , а вторая – для оценки вероятности ошибок распознавания. Недостатками этого подхода являются громоздкость расчётов, поскольку приходится большое число раз осуществлять распознавание объектов, и необходимость в наличии двух выборок: обучающей и контрольной, к каждой из которых предъявляются жёсткие требования по их объёму. Сформировать на практике выборку большого объёма является, как правило, сложной задачей, а две независимые выборки – тем более.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Можно пойти другим путём, а именно: всю выборку использовать для обучения (построения ), а контрольную выборку генерировать датчиком случайных векторов в соответствии с . Такой подход улучшает точность построения по сравнению с предыдущим вариантом, но обладает другими недостатками. В частности, помимо большого числа актов распознавания требуется сгенерировать соответствующее число требуемых для этого псевдообъектов, что само по себе связано с определёнными затратами вычислительных ресурсов, особенно если распределения имеют сложный вид.
В связи с этим представляют интерес другие меры информативности признаков, вычисляемые с меньшими затратами вычислительных ресурсов, чем оценка вероятности ошибок распознавания. Такие меры могут быть не связаны взаимооднозначно с вероятностями ошибок, но для выбора наиболее информативной подсистемы признаков это не столь существенно, так как в данном случае важно не абсолютное значение риска потерь, а сравнительная ценность различных признаков (групп признаков). Смысл критериев классификационной информативности, как и при детерминистском подходе, состоит в количественной мере " разнесённости" распределений значений признаков различных образов. В частности, в математической статистике используются оценки верхней ошибки классификации Чернова (для двух классов), связанные с ней расстояния Бхатачария, Махаланобиса. Для иллюстрации приведём выражение расстояния Махаланобиса для двух нормальных распределений, отличающихся только векторами средних 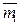 и
и  :
:
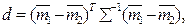
где  – матрица ковариаций,
– матрица ковариаций,
 – транспонирование матрицы,
– транспонирование матрицы,
-1 – обращение матрицы.
В одномерном случае  откуда видно, что
откуда видно, что 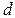 тем больше, чем удалённее друг от друга
тем больше, чем удалённее друг от друга  и
и 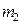 и компактнее распределения (меньше
и компактнее распределения (меньше 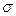 ).
).
Несколько подробнее рассмотрим информационную меру Кульбака применительно к непрерывной шкале значений признаков.
Определим следующим образом среднюю информацию в пространстве  для различения в пользу
для различения в пользу 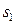 против
против 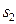 :
:

При этом предполагается, что нет областей, где  а
а 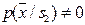 , и наоборот.
, и наоборот.
Аналогично 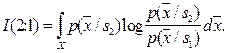
Назовём расхождением величину
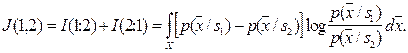
Чем расхождение больше, тем выше классификационная информативность признаков.
Очевидно, что при 
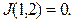 В других случаях
В других случаях 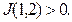 Действительно, если
Действительно, если  , где в области
, где в области 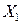 справедливо
справедливо  , а в
, а в  –
– 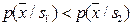 , то
, то 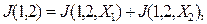 причём
причём 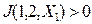 и
и 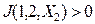 .
.
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
Легко убедиться, что если признаки (признаковые пространства) и  независимы, то
независимы, то 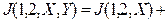

В качестве примера вычислим расхождение двух нормальных одномерных распределений с одинаковыми дисперсиями и различными средними:
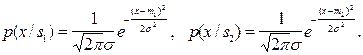
Оказывается, что в этом конкретном случае расхождение равно расстоянию Махаланобиса 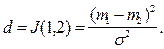
Промежуточные выкладки предлагается сделать самостоятельно.
|
|