Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

Таксономия
|
|
Статистических методов решения задач таксономии существует достаточно много. Мы из-за ограниченности времени, выделенного на курс распознавания образов (классификации), остановимся только на одном, не умаляя значения или эффективности других методов.
Он непосредственно связан с аппроксимационным методом распознавания. Действительно, восстановление неизвестного распределения по выборке в виде смеси базовых распределений является, по существу, решением задачи таксономии с определёнными требованиями (ограничениями), предъявляемыми к описанию каждого из таксонов.

Рис. 25. Объединение компонент смеси в таксоны
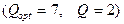
Эти требования состоят в том, что значения признаков объектов, входящих в один таксон, имеют распределения вероятностей заданного вида. В рассматриваемом нами случае это нормальные или биномиальные распределения. В ряде случаев это ограничение можно обойти. В частности, если задано число таксонов  , а
, а  , то некоторые таксоны следует объединить в один, который будет иметь уже отличающееся от нормального или биномиального распределение значений признаков (рис. 25).
, то некоторые таксоны следует объединить в один, который будет иметь уже отличающееся от нормального или биномиального распределение значений признаков (рис. 25).
Естественно, объединять в один таксон следует те компоненты смеси, которые наименее разнесены в признаковом пространстве. Мерой разнесённости компонент может служить, например, мера Кульбака
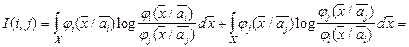

Следует отметить, что эта мера применима лишь в том случае, если подмножество значений  , на котором
, на котором 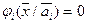 , а
, а 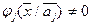 и наоборот, пусто. В частности, это требование выполняется для нормально распределённых значений признаков компонент смеси.
и наоборот, пусто. В частности, это требование выполняется для нормально распределённых значений признаков компонент смеси.
Если говорить о связи изложенного статистического подхода к таксономии с ранее рассмотренными детерминистскими методами, то можно заметить следующее.
Алгоритм ФОРЭЛЬ близок по своей сути к аппроксимации распределения смесью нормальных плотностей вероятностей значений признаков, причём матрицы ковариаций компонент смеси диагональны, элементы этих матриц равны между собой, распределения компонент отличаются друг от друга только векторами средних значений. Однако на одинаковый результат таксономии даже в этом случае можно рассчитывать лишь при большой разнесённости компонент смеси. Объединение нескольких смесей в один таксон по методике близко к эмпирическому алгоритму KRAB 2. Эти два подхода взаимно дополняют друг друга. Когда выборка мала и статистические методы неприменимы или малоэффективны, целесообразно использовать алгоритм KRAB, FOREL, KRAB 2. При большом объёме выборки эффективнее становятся статистические методы, в том числе объединение компонент смеси в таксоны.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
|
|