Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

ІІІ. Наступне вдосконалення моделі
|
|
Тепер почнемо не зовсім просту розмову про спосіб підрахунку кількості Х повторних знавців.
Навіть, якщо у наступному сеансі виключити можливість повернення інформації від щойно спеченого знавця чутки до його безпосереднього інформатора, все одно інформація може повернутися до цього самого передавача від кого-небудь з інших знавців. Це означає, що виключення згаданої можливості не є принциповим, тобто вже у наступному сеансі чутка може повернутися до того, хто поширював її у попередньому сеансі.
Крім того, повторні знавці можуть з’явитися й при самому першому передаванні, якщо N 0 > 1 (дехто з початкових знавців може стати слухачем іншого початкового знавця). Отже, підрахунок кількості Х повторних знавців можна починати від самого першого сеансу передавання.
Пригадаймо знайому ситуацію: на перерві зібралася невелика група учнів, які слухають новину від свого товариша. Всі, крім одного, зацікавлені. А цьому байдуже – поширювана чутка йому вже відома. Він, як і будь-який інший знавець, і сам при нагоді завжди готовий передати її будь-кому: адже згідно Припущення 2 кожен (!) знавець розповсюджує інформацію протягом усього часу моделювання. Скільки ж нових знавців з’являється внаслідок розглянутого передавання? Зрозуміло, що на одного менше, ніж було слухачів у групі.
Таким чином, відмовляючись від Припущення 3, ми опиняємося перед необхідністю не зараховувати до числа нових знавців тих осіб, для яких чутка не є новою, тобто тих, хто отримує її повторно. І не тому, що в житті здебільшого інтерес являють лише нові відомості, а саме тому, що повторні знавці не збільшують нової загальної кількості володарів новини. Для врахування кількості таких людей можна скористатися різними ідеями. Розглянемо одну з можливих.
Будемо вважати, що на самому початку розповсюдження чутка є новою для всіх S мешканців населеного пункту. Після першого передавання загальна кількість знавців (для кого вона є новою разом з тими, кому вона вже відома – N 0) збільшиться на Δ n (для приросту лише нових знавців ми, як і раніше, залишимо позначення Δ N). Зауважимо, що повторні знавці можуть знаходитися тільки серед приросту Δ n, який будемо обчислювати за формулою (3) або (3*) з попередньої версії моделі.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Вираз Δ n/S має зміст тієї долі від усього населення, в межах якої доцільно шукати повторних знавців, а Q = Х/Δ n – доля повторних знавців у черговому прирості (Q £ 1).
Шукатимемо Х у два кроки.
1. Спочатку приймемо
Припущення 6. Доля Q осіб, котрі під час чергового передавання одержують інформацію повторно, пропорційна Δ n/S:
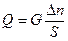 , (5)
, (5)
де G – коефіцієнт, що підбирається шляхом експериментування.
2. Далі обчислимо абсолютну кількість Х осіб, котрі одержують інформацію повторно,
Х = Q· Δ n. (6)
Тоді фактичний приріст Δ N кількості осіб, котрим новина надходить вперше, становитиме
Δ N = Δ n – Х. (7)
Діючи згідно (5) – (7) при кожному наступному передаванні, ми й надалі будемо знаходити приріст Δ N лише тих осіб, які одержуватимуть новину вперше. Обчислюючи далі
Nj = Nj– 1 + Δ N,
ми матимемо загальну кількість саме тих знавців, котрі будуть її поширювати в наступних передаваннях.
Тепер залишається внести відповідні зміни до алгоритму.
Алгоритм роботи з удосконаленою моделлю
– пп. 1, 2: вхідні дані перенести у стовпець Н; до вхідних даних додатково ввести змінні S та G (комірки Н2 та Н8, решту параметрів розташувати у Н3–Н7 в зазначеному раніше порядку) і створити три нових стовпці для спостереження за поведінкою змінних Δ n, X та Q (D, E та F відповідно).
– п. 4.2:
Z = 1 – M – B – доля звичайних передавачів;
Δ n = Nj– 1 · (B·kб + Z·kзв) – як і у попередній версії моделі, але тут Δ n – тимчасове значення змінної Δ N;
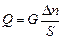 – доля осіб, які одержують чутку повторно;
– доля осіб, які одержують чутку повторно;
G ‑ коефіцієнт, що добирається шляхом експериментування;
Х = Q· Δ n – кількість осіб, котрі під час чергового передавання одержують чутку повторно;
Δ N = Δ n – Х – остаточний приріст кількості нових знавців (лише тих, котрим чутка надходить вперше).
Відповідні комірки таблиці мають такий уміст:
| комірка | формули / числа |
| A3 | = A2 + 1 |
| B3 | = D3-E3 |
| D3 | = C2*($H$4*$H$5 + (1-$H$3-$H$4)*$H$6) |
| E3 | = F3*D3 |
| F3 | = $H$8*D3/$H$2 |
– п. 4.3 залишити без змін:
Nj = Nj– 1 + Δ N
Тут Nj – остаточна кількість знавців новини, здатних до її поширення після передавання з номером j.
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
У таблиці, як і для попередньої версії моделі, це матиме таке відображення:
| комірка | формули / числа |
| C3 | = C2 + B3 |
– так само без змін залишити п. 5:
– формули з комірок A3, B3, C3, D3, E3 та F3 копіювати у решту комірок стовпців A, B, C, D, E та F відповідно.
Обчислювальний експеримент
1. Нехай S = 10000; M = 0, 6; B = 0, 05; kб = 4; kзв = 2; N 0 = 1; G = 1, 5 (рис. 3.4)
| A | B | C | D | E | F | G | H | |
| j | D N | N | D n | X | Q | Дано: | ||
| 0, 000000 | S = | |||||||
| 0, 000135 | M = | 0, 6 | ||||||
| 0, 000256 | B = | 0, 05 | ||||||
| 0, 000487 | kб= | |||||||
| 0, 000926 | kзв= | |||||||
| 0, 001758 | N 0 = | |||||||
| ... | ... | ... | ... | ... | ... | ... | G = | 1, 5 |
| 1, 000000 | ||||||||
| 1, 000000 |
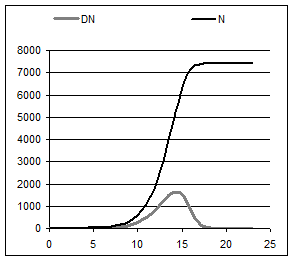
Рис. 3.4.
Розглядаючи утворену таблицю, звертаємо увагу на таке:
1.1. На початку процесу ймовірність появи повторних знавців (її характеризує Q) дуже мала, але поступово вона зростає до 1 (100%), тобто всі нові знавці з часом стають повторними.
1.2.Приріст Δ N дорівнює зміні числа знавців за одне передавання, тому Δ N характеризує швидкість поширення новини. З таблиці видно, що на початку процесу ця швидкість також дуже мала. У міру перебігу процесу його швидкість повільно зростає до максимуму, а далі швидко спадає до нуля і залишається такою на всю решту часу моделювання. Разом з цим перестає змінюватися (зростати) загальна чисельність Nj знавців новини.
1.3. Виведемо на екран графіки залежностей Δ N = Δ N (j) та N = N (j) і переконаймося у сказаному вище.
1.4. Звертає на себе увагу принципово новий і в певній мірі несподіваний факт:
Nj max < S.
Це означає, що за прийнятих вхідних даних частина населення може так і залишитись не інформованою.
2. Проаналізуйте розміри цієї не інформованої частини S – Nj max в залежності від різних чинників.
2.1. З’ясуйте, насамперед, залежність Nj max від коефіцієнта пропорційності G у виразі (5), про який було сказано, що його значення добирається експериментально. Візьміть, для прикладу, G = 1 (а далі G = 0, 5), залишаючи решту даних із попередніми значеннями.
Вправа
1. Чому Nj max зростає (спадає)?
2. Підберіть таке значення G, яке б забезпечувало інформованість усього населення.
3. При якому значенні G новина взагалі не буде поширюватись?
4. Яку, на ваш погляд, роль відіграє коефіцієнт В у даній версії моделі?
5. Якщо відновити дані згідно п. 1 і змінити М – долю мовчунів, наприклад, зменшити її на 5%, то:
а) як це позначиться на розмірах не інформованої частини населення?
б) як така заміна взагалі впливає на перебіг процесу?
2.2. Повторіть п. 2.1 почергово для решти вхідних даних (B, Z, kб, kзв, N 0). Кожного разу намагайтеся пояснити причини спостережуваних подій.
2.3. Наступне дослідження заслуговує на особливу увагу.
Знов поверніться до п. 2.2 у тій його частині, де пропонується експериментування з параметрами kб і kзв. Надайте їм таких значень: kб = 7, kзв = 5. Таблиця набуває незвичного і незрозумілого вигляду:
– у послідовних сусідніх комірках стовпця для Δ N з’являються додатні й від’ємні значення з великою різницею, які весь час чергуються;
– у рядках, що відповідають від’ємним числам, Q > 1;
– взагалі в цій частині таблиці спостерігаються коливання значень всіх змінних.
Можливо, при виконанні попередніх експериментів перед вами вже виникали подібні ситуації. У чому ж причина?
Будь-які спроби знайти тут логічне обґрунтування (у межах розглядуваної моделі) заздалегідь приречені на невдачу.
У моделюванні подібні ситуації добре відомі. У переважній більшості випадків, і зокрема, коли сама модель за своєю внутрішньою логікою не передбачає коливних процесів, причина спостережуваних значних коливань змінних (до того ж і зі зміною знаків) завжди однакова: за певних значень вхідних даних модель втрачає стійкість. Це одна з важливих особливостей всякої більш-менш складної моделі. Що ж до вмісту самої таблиці, то тепер значення змінних у ній – це усього лише результати обчислень, які аж ніяк не відбивають реальний перебіг процесу. Більш докладно про стійкість моделі йтиметься у наступній главі.
Висновки
1. Самою суттєвою якістю розглянутої версії моделі є те, що у ній, нарешті, з’являється таке довго очікуване обмеження кількості знавців новини. Причому, принциповим тут є той факт, що це обмеження випливає із самої моделі, а не внаслідок додаткових штучних заходів, як це мало місце у двох попередніх версіях.
2. Обчислювальний експеримент у завданні 4 із Вправ дозволяє дійти висновку, що коефіцієнт пропорційності В має зміст своєрідного регулятора швидкості процесу поширення чуток.
3. Важливе значення має результат, одержаний у п. 2.3, а саме уявлення про стійкість моделі Він вартий того, щоб його повторити: За певних значень вхідних даних модель може втратити стійкість. Значення змінних при цьому являють собою усього лише результати обчислень і ніяк не відбивають реальний перебіг процесу.
Найпершими ознаками (мовою медиків – симптомами) втрати моделлю стійкості є коливання з великою амплітудою та зміною знаків значень змінних у сусідніх комірках певних стовпців. Проте, у подібних випадках треба бути впевненим у тому, що спостережувані коливання не є наслідком внутрішніх законів самої моделі, тобто не випливають із природи явища, яке моделюється.
|
|