Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

⚡️ Для новых пользователей первый месяц бесплатно. А далее 290 руб/мес, это в 3 раза дешевле аналогов. За эту цену доступен весь функционал: напоминание о визитах, чаевые, предоплаты, общение с клиентами, переносы записей и так далее.
✅ Уйма гибких настроек, которые помогут вам зарабатывать больше и забыть про чувство «что-то мне нужно было сделать».
Сомневаетесь? нажмите на текст, запустите чат-бота и убедитесь во всем сами!
Массив процессоров и его контроллер
|
|
Контроллер массива процессоров выполняет последовательный программный код, реализует команды ветвления программы, транслирует команды и сигналы управления в процессорные элементы. Одну из возможных реализаций КМП, принятую в устройстве управления системы PASM, иллюстрирует рис. 8.2.

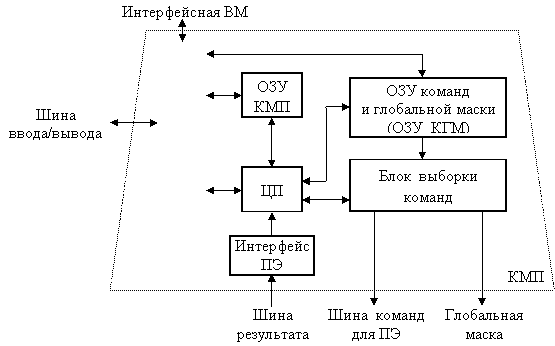
Рис. 8.2. Модель контроллера массива процессоров
При загрузке из ИВМ программа через интерфейс ввода/вывода заносится в оперативное запоминающее устройство КМП (ОЗУ КМП). Команды для процессорных элементов и глобальная маска, формируемая на этапе компиляции, также загружаются через интерфейс ввода/вывода в ОЗУ команд и глобальной маски (ОЗУ КГМ). Затем КМП начинает выполнять программу, извлекая либо одну скалярную команду из ОЗУ КМП, либо множественные команды из ОЗУ КГМ. Скалярные команды (команды, осуществляющие операции над хранящимися в КМП скалярными данными), выполняются центральным процессором (ЦП) контроллера массива процессоров. В свою очередь команды, оперирующие параллельными переменными, хранящимися в каждом ПЭ, преобразуются в блоке выборки команд в более простые единицы выполнения – нанокоманды. Нанокоманды совместно с маской пересылаются через шину команд для ПЭ на исполнение в массив процессоров. Например, команда сложения 32-разрядных слов в КМП системы МРР преобразуется в 32 нанокоманды одноразрядного сложения, которые каждым ПЭ обрабатываются последовательно.
В большинстве алгоритмов дальнейший порядок вычислений зависит от результатов и флагов условий предшествующих операций. Для обеспечения та-кого режима в матричных системах статусная информация, хранящаяся в процессорных элементах, должна быть собрана в единое слово и передана в КМП для выработки решения о ветвлении программы. Например, в предложении IF ALL (условие А) THEN DO B оператор B будет выполнен, если условие А справедливо во всех ПЭ. Для корректного включения/отключения процессорных элементов КМП должен знать результат проверки условия А во всех ПЭ. Такая информация передается в КМП по однонаправленной шине результата. В системе СМ-2 эта шина называется GLOBAL. В системе МРР для той же цели организована структура, называемая деревом SUM-OR. Каждый ПЭ помещает содержимое своего одноразрядного регистра признака на входы дерева, которое с помощью операции логического сложения комбинирует эту ин-формацию и формирует слово результата, используемое в КМП для принятия решения.
В матричных SIMD-системах получили распространение два основных типа архитектурной организации массива процессорных элементов (рис. 8.3).
В первом варианте, известном как архитектура типа «процессорный элемент-процессорный элемент» (ПЭ-ПЭ), N процессорных элементов (ПЭ) связаны между собой сетью соединений (рис. 8.3, а). Каждый ПЭ – это процессор с локальной памятью. Процессорные элементы выполняют команды, получаемые из КМП по шине широковещательной рассылки, и обрабатывают данные как хранящиеся в их локальной памяти, так и поступающие из КМП. Обмен данными между процессорными элементами производится по сети соединений, в то время как шина ввода-вывода служит для обмена информацией между ПЭ и устройствами ввода-вывода. Для трансляции результатов из отдельных ПЭ в контроллер массива процессоров служит шина результата. Благодаря использованию локальной памяти аппаратные средства ВС рассматриваемого типа могут быть построены весьма эффективно. Во многих алгоритмах действия по пересылке информации локальны, то есть происходят между ближайшими соседями. По этой причине архитектура, где каждый ПЭ связан толь- ко с соседними, очень популярна. Примерами вычислительных систем с рассматриваемой архитектурой являются MasPar MP-1, Connection Machine CM-2, GF-11, DAP, MPP, STARAN, PEPE, ILLIAC IV.
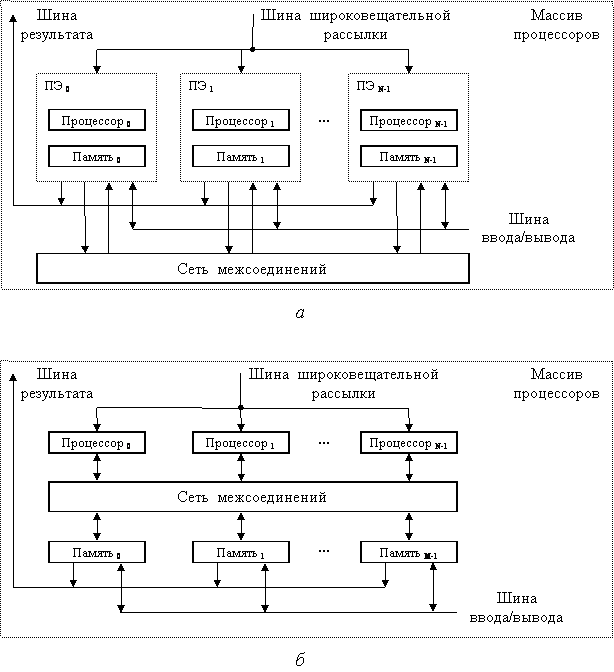
Рис. 8.3. Модели массивов процессоров: а – «процессорный элемент-процессорный элемент»; б – «процессор-память»
Второй вид архитектуры – «процессор-память» показан на рис. 8.3, б. В такой конфигурации двунаправленная сеть соединений связывает N процессоров c М модулями памяти. Процессоры управляются КМП через широковещательную шину. Обмен данными между процессорами осуществляется как через сеть, так и через модули памяти. Пересылка данных между модулями памяти и устройствами ввода/вывода обеспечивается шиной ввода/вывода. Для передачи данных из конкретного модуля памяти в КМП служит шина результата. Примерами ВС с рассмотренной архитектурой служат Burroughs Scientific Processor (BSP) и Texas Reconfigurable Array Computer TRAC.
|
|