Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

Генерирования исходных параметров функций принадлежности для ANFIS-обучения
|
|
Синтаксис:
mf_param = genparam(data, mf_n, mf_type)
Описание:
Функция genparam генерирует параметры функций принадлежности таким образом, чтобы центры функций принадлежностей располагались через равные промежутки внутри интервалов изменения данных.
Функция genparam может имеет три входных аргумента, первый из которых обязательный:
1. data – матрица данных “входы – выход”. Каждая строка данных содержит одну пару “входы – выход”. Последний столбец матрицы содержит значения выходной переменной, а остальные – значения входных переменных;
2. mf_n – вектор, задающий количество термов, которыми оценивается каждая входная переменная. Если аргумент задан скалярным значением, то количество термов принимается одинаковым для всех входных переменных. Значение по умолчанию – 2;
3. mf_type – матрица строк, определяющая тип функций принадлежности для каждой входной переменной. Если аргумент задан одной строкой, тогда все функции принадлежности будут иметь один и тот же тип. Значение по умолчанию - 'gbellmf' (обобщенная колоколообразная функция принадлежности). Функция genparam не поддерживает следующие типы функции принадлежностей: 'sigmf', 'smf' и 'zmf'.
Функция genparam возвращает матрицу mf_param, каждая строчка которой содержит параметры одной функций принадлежности. Первая строка матрицы соответствует параметрам первой функции принадлежности первой входной переменной, вторая - второй функции принадлежности первой входной переменной, …, последняя - последней функции принадлежности последней входной переменной.
Пример:
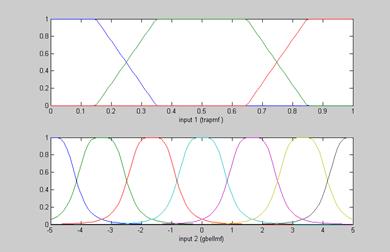
NumData = 1000;
data = [rand(NumData, 1) 10*rand(NumData, 1)-5 rand(NumData, 1)];
NumMf = [3 7];
MfType = str2mat('trapmf', 'gbellmf');
MfParams = genparam(data, NumMf, MfType);
set(gcf, 'Name', 'genparam', 'NumberTitle', 'off');
NumInput = size(data, 2) - 1;
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
range = [min(data)' max(data)'];
FirstIndex = [0 cumsum(NumMf)];
for i = 1: NumInput;
subplot(NumInput, 1, i);
x = linspace(range(i, 1), range(i, 2), 100);
index = FirstIndex(i)+1: FirstIndex(i)+NumMf(i);
mf = evalmmf(x, MfParams(index,:), MfType(i,:));
plot(x, mf');
xlabel(['input ' num2str(i) ' (' MfType(i,:) ')']);
end
Генерирование трех треугольных и семи колоколообразных функций принадлежностей из 1000 пар случайно полученных данных “входы-выход”.
Настройка систем нечеткого логического вывода типа Сугено
Синтаксис:
[fis, error] = anfis(trndata)
[fis, error] = anfis(trndata, initfis)
[fis, error, stepsize] = anfis(trndata, initfis, trnopt, dispopt, [], optmethod)
[fis, error, stepsize, chkfis, chkerror] = anfis(trndata, initfis, trnopt, dispopt, chkdata)
Описание:
Это основная функция настройки систем нечеткого логического вывода типа Сугено. Настройка представляет собой итерационную процедуру нахождения таких параметров системы нечеткого логического вывода, в частности параметров функций принадлежности, которые минимизируют расхождения между результатами логического вывода и экспериментальными данными, т. е. между действительным и желаемым поведениями системы. Экспериментальные данные, по которым настраивается функции принадлежности, представляются в виде обучающей выборки.
Функция anfis может имеет шесть входных аргументов:
1. trndata – обучающая выборка. Этот входной аргумент является обязательным. Обучающая выборка представляет собой матрицу, каждая строчка которой является парой “входы-выход”. Последний столбец матрицы соответствует вектору значений выхода, а все остальные столбцы – входным данным;
2. initfis – идентификатор исходной системы нечеткого логического вывода, функции принадлежности которой будут настроены с помощью anfis. Исходная система нечеткого логического вывода должна быть системой типа Сугено нулевого или первого порядка. Еще одним ограничением anfis является недопустимым использования типов функций принадлежностей и методов дефаззификации, определяемых пользователем. При отсутствии аргумента initfis функция anfis вызовет функцию genfis1, которая генерирует типовую систему нечеткого логического вывода. Эта типовая система будет использовать по две функции принадлежности гауссовского типа для каждой входной переменной. В случае, когда пользователь хочет получить систему с иным количеством функций принадлежности, необходимо задать в виде аргумента initfis количество функций принадлежности для оценки каждой входной переменной. Если количество функций принадлежности одинаково для всех входов, тогда достаточно указать только одно значение.
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
3. trnopt – вектор параметров настройки:
trnopt(1) – количество итераций (значение по умолчанию – 10);
trnopt(2) – допустимая ошибка обучения (значение по умолчанию – 0);
trnopt(3) – исходная длина шага (значение по умолчанию – 0.01);
trnopt(4) – коэффициент уменьшения длины шага (значение по умолчанию – 0.9);
trnopt(5) – коэффициент увеличения длины шага (значение по умолчанию – 1.1);
4. dispopt – вектор, указывающий какие промежуточные результаты обучения выводить в командное окно MatLab во время настройки. Для вывода информации на экран необходимо установить соответствующую координату вектора в 1. Вектор dispopt имеет четыре координаты:
dispopt(1) – ANFIS-информация: количество функций принадлежности входных и выходной переменных и т.п.;
dispopt(2) – ошибка обучения;
dispopt(3) – длина шага, (выводится в случае его изменения);
dispopt(4) – окончательный результат.
По умолчанию значения всех координат равны 1;
5. chkdata – идентификатор тестирующей выборки. Тестирующая выборка используется для исследования свойства обобщения системы нечеткого логического вывода, т. е. способности системы выдавать правильные результаты для данных, отсутствующих в обучающей выборке. Формат тестирующей выборки такой же как и обучающей. Обычно элементы тестирующей выборки несколько отличаются от элементов обучающей выборки. Тестирующая выборка особенно важна для задач обучения с большим количеством входов и (или) для задач с зашумленными данными. При формировании обучающей и тестирующей выборок необходимо стремится к обеспечению свойств представительности выборок;
6. optmethod – метод оптимизации, используемый для настройки. Допустимые значения: 1 – гибридный алгоритм и 0 – метод обратного распространения ошибки. По умолчанию применяется гибридный алгоритм, который использует метод обратного распространения ошибки (метод наискорейшего спуска) для настройки функций принадлежности входных переменных и метод наименьших квадратов для настройки функций принадлежности выхода. Точнее говоря, метод наименьших квадратов используется для нахождения коэффициентов линейных функций, связывающих входы и выход в каждом правиле. Метод по умолчанию используется всегда, за исключением случая, когда значение аргумента optmethod равно 0.
Функция anfis может иметь пять выходных аргументов:
1. fis – система нечеткого логического вывода, параметры которой настроены таким образом, что минимизируют расхождения между результатами логического вывода и экспериментальными данными из обучающей выборки;
2. error – вектор, содержащий значения ошибки обучения на каждой итерации. Ошибка обучения рассчитывается как среднее квадратическое отклонение между результатами нечеткого логического вывода и значениями выходной переменной из обучающей выборки;
3. stepsize – вектор, содержащий значения длины шага алгоритма оптимизации на каждой итерации;
4. chkfis – система нечеткого логического вывода, параметры которой настроены таким образом, что минимизируют расхождения между результатами логического вывода и экспериментальными данными из тестирующей выборки. Для получения такой системы необходимо задать пятый входной аргумент функции anfis – тестирующую выборку;
5. chkerror - вектор, содержащий значения ошибки тестирования на каждой итерации. Ошибка тестирования рассчитывается как средне- квадратичное отклонение между результатами нечеткого логического вывода и значениями выходной переменной из тестирующей выборки. Для расчета ошибки тестирования необходимо задать пятый входной аргумент функции anfis – тестирующую выборку.
Процесс настройки прекращается по достижению требуемой ошибки обучения настройки или после выполнения указанного количества итераций.
Функция anfis может быть вызвана с одним входным аргументом – обучающей выборкой и одним выходным аргументом – системой нечеткого логического вывода, параметры которой настроены по обучающей выборке. При вызове функции anfis значения неинициализированых аргументов принимаются равными по умолчанию. При инициализации только части аргументов, например, первого и шестого – обучающей и тестирующей выборок, значения остальных аргументов (для нашего примера - второго, третьего, четвертого и пятого) необходимо задать как []. Значение [] указывает, что соответствующий аргумент принимает значения, установленные по умолчанию.
Пример.
Синтезируется и настраивается система нечеткого логического вывода fis, моделирующая зависимость y=sin(x) в диапазоне [0, 1].
x=(0: 0.04: 1)’;
y=sin(x);
trndata=[x y];
[fis, error, stepsize]=anfis(trndata)
| Замена правил нечеткой базы знаний |
Синтаксис:
outfis = parsrule (infis, inrulelist, ruleformat, lang)
[outfis, outrulelist, errorstr] = parsrule (infis, inrulelist, ruleformat, lang)
Описание:
Функция parsrule предназначена для ввода правил в нечеткую базу знаний. При этом удаляются ранее существующие в базе знаний правила. Функция parsrule может иметь до четырех входных аргументов, первые два из которых обязательные:
1. infis - идентификатор исходной системы нечеткого логического вывода;
2. inrulelist - список правил " если - то". Правила можно задавать в виде предложений на английском, немецком и французских языках. При задании правил на естественном языке необходимо использовать следующие ключевые слова:
- для английского языка - " if", " and", " or", " then", " is", " not";
- для французского языка - " si", " et", " ou", " alors", " est ", " n''est_pas";
- для немецкого языка - " senn", " und", " oder", " dann", " ist", " nicht",
которые эквиваленты русским словам " если", " и", " или", " то", " есть", " не", соответственно. Весовой коэффициент можно указать в конце правила. По умолчанию значение весового коэффициента равно 1. Список правил задается в виде матрицы, каждая строчка которой определяет одно правило;
3. ruleformat - формат правил. Допустимые значения:
'verbose' - словесный;
'symbolic' - символьный;
'indexed' - индексный.
Значение по умолчанию - 'verbose'. В формате 'verbose' невозможно в качестве значений переменной использовать терм 'none'. Для задания " коротких" правил необходимо из правила исключить наименования соответствующих переменных;
4. lang - язык представления правил в формате 'verbose'. Допустимые значения:
'english' - английский;
'francais' - французский;
'deutsch' - немецкий.
По умолчанию установлен английский язык.
Функция parsrule может иметь до трех выходных аргументов:
1. outfis - идентификатор системы нечеткого логического вывода с новыми правилами;
2. outrulelist - список правил системы outfis. Список представляет собой матрицу целых положительных чисел, соответствующих правилам, заданных матрицей inrulelist. Для преобразования чисел в символы необходимо использовать функцию char. Вошедшие в outfis корректно заданные правила в этом списке имеют порядковый номер. Наличие символа '#' указывает на то, что соответствующее правило является некорректным.
3. errorstr - список ошибок задания правил.
Пример:
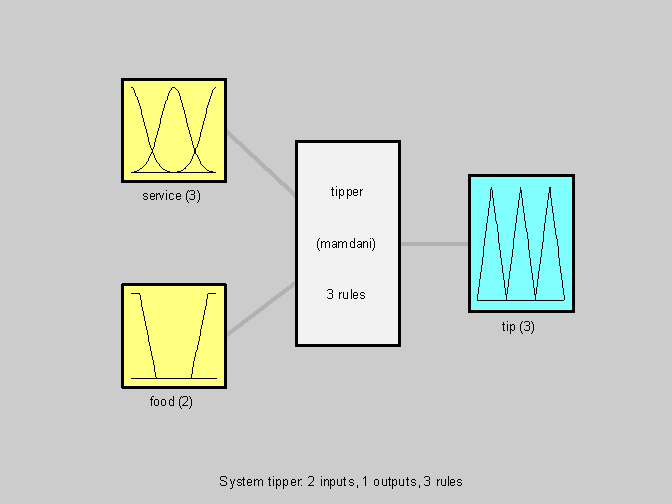
infis=readfis('tipper');
r1='if service is good then tip is average ';
r2='if service is poor and food is rancid then tip is cheap ';
r3='if service is excellent and food is delicious then tip is generous';
inrulelist=[r1; r2; r3]; outfis=parsrule(infis, inrulelist)
Загружается в рабочую область демонстрационная система нечеткого логического вывода " Tipper", задающая зависимость размера чаевых от качества пищи и уровня сервиса в ресторане. Затем формируется новая база знаний, содержащая следующие правила:
" if service is good then tip is average";
" if service is poor and food is rancid then tip is cheap";
" if service is excellent and food is delicious then tip is generous'".
Синтаксис: plotfis (fis) Описание: Функция plotfis выводит в графическом окне структуру системы нечеткого логического вывода fis. Входные переменные системы изображаются в левой части графического окна, выходные переменные – в правой части, в центре – база знаний. В графическом окне выводится наименование и тип системы нечеткого логического вывода, количество термов для каждой переменной и количество правил. Также изображаются графики функций принадлежности всех термов. Пример: a=readfis(‘tipper’); Вывод структуры демонстрационной системы нечеткого логического вывода “Tipper”.
|

|
|