Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

Багатокаскадна декомпозиція даних
|
|
Алгоритмічна складність класичного ієрархічного алгоритму згортання – побудови дерева кластерів не дозволяє кластеризувати великі вибірки даних, в тому числі пікселів образів практичних розмірів. Тому запропоновано багатоступенева декомпозиція множин об’єктів і кластерів, яку назвемо каскадною кластеризацією.
Розбиваємо вхідну множину об’єктів Q (Q 1, Q 2, Q 3, … QN)на p підмножин O 1(Q 1, Q 2, Q 3, … Qz), O 2(Qz+ 1, Q z +2, Q z +3, … Qt), …, Op (Qt +1, Q t +2, Qt+ 3, … QN). До кожної з підмножин (назвемо їх множинами нульового каскаду), застосуємо алгоритм кластеризації, утворивши множини відповідних кластерів K 1(k 1, k 2, k 3, …), K 2(ks, ks +1, ks +2, …), …, Kp (kr, kr +1, kr +2, …), де k 1, k 2, …, ki,... – кластери, об’єкти в яких відносяться до відповідних підмножин O 1, O 2, …, Op. Утворимо множину кластерів 1-го каскаду кластеризації K об’єднанням:
K = K 1(k 1, k 2, k 3, …)  K 2(ks, ks +1, ks +2, …) … Kp (kr, kr +1, kr +2, …). (2.20)
K 2(ks, ks +1, ks +2, …) … Kp (kr, kr +1, kr +2, …). (2.20)
Застосуємо до цієї множини алгоритм кластеризації, розглядаючи кожен з кластерів k 1, k 2, …, ki,... як базовий, тобто листок деревазгортання. При цьому вони (кластери 1-го каскаду) перемішуються, тобто виступають як незалежні. Утворену множину кластерів 1-го каскаду поділимо на підмножини O 1, O 2, …, Op, даліздійснюєтьсякластеризація в межах підмножин до отримання множини кластерів 2-го каскаду. При отриманні кореня дерева згортання на 2-му каскаді матимемо двокаскадну декомпозицію, на третьому каскаді – трикаскадну і т.д. Кількість каскадів визначається кількістю рівнів ієрархічного дерева згортання, на яких здійснюється поділ кластерів на множини (без рівня об’єктів). Схема поділу та згортання є рекурсивною (рис. 2.4).
Запишемо алгоритм каскадної кластеризації:
Крок 1. Вхідну множину точок С поділити на p підмножин Сp.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Крок 2. Для кожної Сp застосувати алгоритм кластеризації.
Крок 3. Отримані вихідні кластери Сpres перенести в єдину множину Сres.
Крок 4. Якщо можна поділити множину Сres на p підмножин, то перехід на крок 1, інакше перехід на крок 2.
Після зупинки алгоритму множина Сres міститиме результат кластеризації.
|
|
|
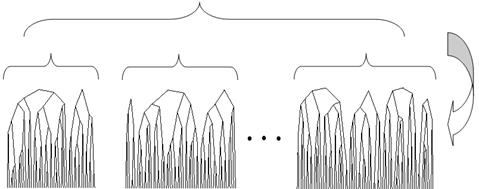
Рис. 2.4. Каскадне дерево формування кластерів
Таким чином, отримуємо зменшення розмірності та складності алгоритму, що дозволяє застосовувати підхід до даних великої розмірності.
На кількість каскадів вказують коефіцієнти поділу: наприклад, 20000 об’єктів розбивається на 100 груп по 200 об’єктів з виходом на 2-ий каскад по 20 кластерів з групи. Тоді на 2-гому каскаді є 100∙ 20=2000 кластерів, які ділимо ще на 10 груп по 200 елементів з виходом на вищий каскад 20 кластерів з групи. Кількість каскадів визначається автоматично в залежності від кількості кластерів, до яких застосовується повний перебір. Питання вибору потужностей множин O 1, O 2, …, Op в межах каскадів і, відповідно, їх кількостізалишається відкритим для дослідження.
При дослідженні алгоритму 10000 об’єктів генерувались за рівномірним та нормальним законами розподілу з різними центрами координат та однаковими дисперсіями. Тестування проведені для різної кількості множин (відповідно, їх потужностей) для 0-го каскаду кластеризації. Як і очікувалось, результати, отримані на кінцевому каскаді можна охарактеризувати так:
1) Якісні та кількісні показники кластерів є тим кращими, чим більша кількість кінцевих кластерів виходить з групи. Менша кількість груп дає кращі результати;
2) Часові показники програми зворотні, тобто вони менші для меншої кількості елементів в кожній групі, а кількість груп є максимально можлива.
При каскадній декомпозиції важливим питанням є вибір потужностей множин O 1, O 2, …, Op в межах каскадів і, відповідно, їх кількості. Вагомим також є попередня обробка даних у межах множин O 1, O 2, …, Op, що якісно впливає на результат кластеризації.
Можливі два способи розбиття вхідної множини на підмножини O 1, …, Op:
1) Поділ на підмножини без попередньої обробки, наприклад, розбиття випадковим чином. Через перемішування і об’єднання значень, що реально розташовані на далеких відстанях, даний підхід має тільки теоретичне значення. В ньому результати кластеризації в порівнянні з іншими правилами розбиття є найгіршими. Складність алгоритму в даному підході визначається кількістю значень ni в підмножині Oi та кількістю самих підмножин розбиття, а саме: O (p ∙ ni 3);
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
2) Поділ на підмножини згідно кількості та розташування. Розташування контролюється сортуванням вхідної вибірки за однією пріоритетною координатою (ознакою). Далі за цією ж координатою здійснюється поділ на підмножини за значенням кожної з потужностей. До підмножин застосовується алгоритм каскадної кластеризації.
Вибір пріоритетної координати покладається на користувача програми. Складність алгоритму збільшується на одне сортування повної вибірки, тобто стає рівною: O (p ∙ ni 3) + O (N 2).
Алгоритм розроблено для ілюстрації впливу цілеспрямованого поділу вхідної вибірки даних, яка не може бути кластеризована класичним алгоритмом через великий об’єм.
Розглянемо алгоритми розбиття вхідної множини n -вимірних даних на підмножини.
Поділ на підмножини випадковим чином. Нехай потрібно поділити множину С, що складається із s точок на p підмножин. Алгоритм розбиття на підмножини:
Крок 1. Утворити p порожніх підмножин, i = 0, count = [ s / p ].
Крок 2. Якщо С ≠ 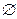 , отримати точку st за допомогою функції random (s), яка повертає індекс точки у межах від 0 до s у вихідній множині. Інакше перехід на крок 4.
, отримати точку st за допомогою функції random (s), яка повертає індекс точки у межах від 0 до s у вихідній множині. Інакше перехід на крок 4.
Крок 3. Якщо кількість точок у підмножині pi є більша за count то i = i +1.
Крок 4. Перенести точку st у підмножину pi. Перехід на крок 1.
Крок 5. Перенести всі точки із С у підмножину pi.
Результуючі підмножини pi (i = 1, 2, …, count -1) міститимуть однакову кількість точок. Підмножина pcount міститиме на { s / p } точок більше.
Поділ на підмножини сортуванням по одній вимірності. Вхідну множину сортуємо за однією вимірністю точки. Далі застосовуємо алгоритм поділу на підмножини, що базується на попередньому алгоритмі, де замість функції random (s) беремо першу точку множини С. Далі застосовуємо алгоритм кластеризації. Для сортування використовуємо алгоритм QuickSort.
Результати досліджень зведено у табл. 2.1. В таблиці приведено часовий виграш по відношенню до декомпозиції без каскадів та груп (в %). Результати таблиці дозволяють вибрати оптимальне співвідношення між кількістю груп, кількістю кластерів в групі, якісних оцінок результатів кластеризації та часових затрат на декомпозицію множини ключів образів.
На рис. 2.5 продемонстровано характер зміни функції критерію об’єднання вершин дерева (кластерів) при збільшенні рівня ієрархії дерева. На рис. 2, а зображено декомпозицію без групування та каскадів, на рис. 2, б –декомпозицію із групуванням та одним каскадом, на рис. 2, в – декомпозицію із групуванням та двома каскадами. Графіки дозволяють знайти оптимальне розбиття ключів за такими оцінками: 1) за кількістю кластерів 2) за кількістю ключів в кластерах, 3) за якісними характеристиками розбиття вцілому, та окремими кластерами (питомі густина, об’єм, дисперсія тощо).
|

а

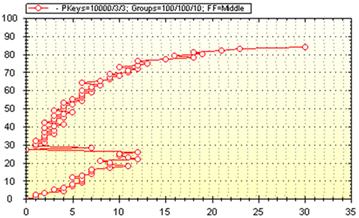
б


в
Рис. 2.5. Графіки функцій критерію об’єднання
Рис. 2.6. Питомі об’єм та густина за рівнями дерева згортання


а б
Рис. 2.7. Функція відстані та питомої дисперсії за рівнями дерева згортання
із каскадною декомпозицією
Рис. 2.8 ілюструє залежність характеристики питомого об’єму (a) та зміну питомої густини (б) під час процесу згортання із каскадною декомпозицією.
Рис. 2.9 ілюструє залежність характеристики питомого об’єму (a) за кількістю кластерів на рівні дерева згортання та зміну функції на ділянці 0÷ 60 кластерів на рівні (б) під час процесу згортання.
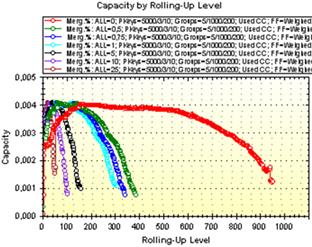
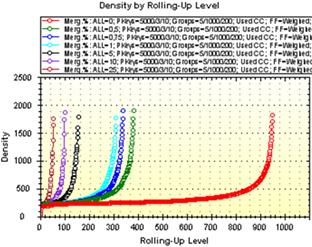
а б
Рис. 2.8. Питомі об’єм та густина за рівнями дерева згортання
із каскадною декомпозицією

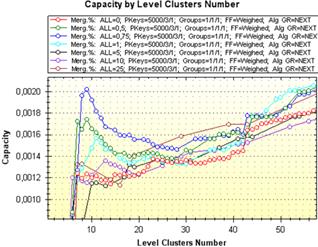
а б
Рис. 2.9. Питомий об’єм за кількістю кластерів на рівні
та ділянка 0-60 кластерів на рівні
Табл. 2.2 демонструє зміну часової залежності (алгоритмічну складність) від коефіцієнту швидкості (0, 1%, 5%, 10%) та алгоритму згортання без та з використанням каскадної декомпозиції.
Таблиця 2.2.
Часові залежності алгоритму
| Кількість точок | Коефіцієнт швидкості, % | Час без каскадів, с | Час з каскадами, с | Параметри декомпозиції |
| 43, 281 | 11, 0625 | 5 груп по 1000 елементів, 200 результуючих з групи, використано 1 каскад | ||
| 11, 312 | 3, 64 | |||
| 6, 765 | 2, 3125 |
|
|