Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Для новых пользователей первый месяц бесплатно. Чат-бот для мастеров и специалистов, который упрощает ведение записей: — Сам записывает клиентов и напоминает им о визите;
— Персонализирует скидки, чаевые, кэшбэк и предоплаты;
— Увеличивает доходимость и помогает больше зарабатывать; Начать пользоваться сервисом

Квотний відбір
|
|
Найпоширенішим серед невипадкових методик формування вибіркової сукупності є квотний відбір. Відбір за квотами відрізняється від випадкових методик кількома ознаками. На відміну від імовірнісного (як одного з видів випадкового відбору), він передбачає наявність статистичних даних за низкою суттєвих або корелюючих з ними характеристик генеральної сукупності. Відповідно до складу генеральної сукупності встановлюють квоти для певних суттєвих ознак (переважно соціально-демографічних). У такий спосіб намагаються досягти адекватності вибіркової та генеральної сукупностей. Інтерв'юер, одержуючи завдання опитати заплановану кількість одиниць у квоті, сам здійснює вибір одиниць, що потраплять до вибірки.
При квотному відборі обсяг вибіркової сукупності формується наперед, з урахуванням попередньої інформації про генеральну сукупність. Спільною проблемою ймовірнісного і квотного відбору є труднощі, що виникають при визначенні суттєвих характеристик об'єкта дослідження. Джерело цих труднощів криється в недостатній вивченості останнього з погляду питання, що цікавить соціолога. Щоб уникнути цих ускладнень, у відборах звичайно використовують тісно корелюючі ознаки.
Для квотного відбору репрезентативна вибіркова сукупність створюється теоретично: її структура та обсяг визначаються відповідно до структури та обсягу генеральної сукупності.
Реалізація квотного відбору залежить від правильності організації процесу відбору одиниць дослідження, але на відміну від імовірнісного відбору тут правильність відбору одиниць дослідження залежить не від випадкових обставин, а від свідомої, цілеспрямованої діяльності інтерв'юерів. Міра репрезентативності квотних відборів збільшується прямо пропорційно до міри стійкості характеристик, за якими задаються квоти. Тому до статистичних даних треба ставитися особливо обережно.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Намагаючись удосконалити квотний метод, до квотного відбору включали елементи ймовірнісної вибірки, квотний відбір застосовували також у багатоступеневій вибірці.
У першому випадку мається на увазі, що інтерв'юер втрачає свободу пошуку респондента з потрібним поєднанням ознак. Як і за умови ймовірнісного відбору, він одержує список осіб, з якими має увійти в контакт. Інтерв'ю він проводить тільки з тими респондентами, які виявилися носіями необхідного поєднання параметрів. Іноді інтерв'юер отримує схему відбору респондентів безпосередньо перед опитуванням. Завдяки цим нововведенням переваги квотної вибірки певною мірою поєднуються з перевагами ймовірнісного відбору.
У другому випадку квотна вибірка використовується тільки на останньому ступені відбору. Така стратегія забезпечує так зване самозважування вибірки (пропорційне щодо генеральної сукупності представництво одиниць спостереження) за найважливішими ознаками, використаними при виділенні ступенів, і тому ризик, пов'язаний з квотним відбором, помітно зменшується. Водночас обсяг вибірки скорочується.
Квотна вибірка формується в декількох варіантах. Спочатку створюється модель вибірки на основі багатьох показників як певних пропорцій, які відповідають основним характеристикам генеральної сукупності в цілому. Такими показниками можуть бути стать, вік, освіта, соціальний статус, місце проживання, приналежність до певної конфесії тощо.
Якщо створена модель вибірки відповідає в основному генеральній сукупності за вибраними параметрами, можна допустити, що така вибіркова сукупність відтворить у цілому генеральну сукупність за іншими показниками, які з тієї чи іншої причини не увійшли у вибіркову сукупність.
Використання вибіркової сукупності стає можливим тільки при умові достатнього уявлення про генеральну сукупність (наявність статистичних даних, матеріалів спостереження або офіційна інформація щодо штатного розпису з відділу кадрів — кількість працюючих за статтю, за віком, за освітою, у змінах, цехах, бригадах тощо). Потім відбираються одиниці опитування, які відповідають пропорціям у генеральній сукупності. Наприклад, генеральна сукупність складається з 400 чоловіків та 600 жінок. Якщо взяти 10% вибірку, потрібно опитати відповідно 40 чоловіків та 60 жінок. Опитуванню підлягають інші групи населення, але у відповідності до основних характеристик генеральної сукупності, тобто зберігаються рівні пропорції у вибірковій сукупності (за статтю, віком, освітою, місцем проживання тощо).
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
Безперечно, всі характеристики генеральної сукупності у вибірковій сукупності відтворити не завжди можливо; дослідник змушений опитувати респондентів, які презентують основні соціальні спільноти, групи, галузі, території, виробництва, способи відпочинку, дозвілля тощо.
При формуванні квотної вибірки виникають складнощі пошуку респондентів, що відтворюють певні характеристики генеральної сукупності. Інколи дуже тяжко відтворити певні характеристики вибіркової сукупності, тому в майбутньому виникає потреба підвищити надійність та репрезентативність інформації. У такому випадку дослідник повинен виходити із завдань дослідження, а також використовувати перехресні методи підвищення достовірної соціальної інформації про об'єкту цілому.
При проведенні типологічних досліджень усі одиниці аналізу розбивають по групах на основі певних показників. Потім з кожної групи відбираються типові представники. Передбачається, що представники певної групи мають певні якісні характеристики в середньому для групи, тому вірогідно, що вони можуть мати і наступні характеристики в середньому для групи.
Звідси робимо висновок, що аналіз результатів про окремі групи повинен подати інформацію, яка в основі є характерною (репрезентативною) для всієї генеральної сукупності.
Наведені приклади типологічних досліджень використовуються як попередні, з метою апробації програми та методики, з подальшим проведенням повномасштабних соціологічних досліджень.
37. Способи ремонту вибірки: відсікання, перезважування.
Навіть якщо вибірка є правильно спланованою, та під час практичної
реалізації плану вибірки часто виникають різноманітні
проблеми. Зокрема, " недосяжність" певних потенційних респондентів
може призводити до певних викривлень у структурі вибірки. Досить
часто після завершення етапу збору інформації виконують процедуру
ремонтування вибірки. Метою цієї процедури є відтворення у вибірці
відомих із зовнішніх надійних джерел інформації характеристик
генеральної сукупності. Такими зовнішніми джерелами інформації
часто є або дані державної статистики, або ж дані інших досліджень.
Пакет SPSS дає можливість досліднику ремонтувати вибірку
методом зважування. Ідея методу зважування полягає в тому, що
кожному спостереженню присвоюється певне позитивне число, що
розглядається як ваговий коефіцієнт цього спостереження (або говорять
просто про вагу спостереження) у загальній вибірці. Працюючи
зі зваженою вибіркою, комп'ютерна програма оперує не кількостями
спостережень, а сумами вагових коефіцієнтів цих спостережень.
Зокрема зазначимо, що навіть незважена вибірка може розглядатися
як така, в якій кожне спостереження має вагу 1.
Технічно процес зважування виглядає дуже просто. Потрібно
вказати певну змінну, яка під час подальшого аналізу буде розглядатися
як вагова. Значення цієї змінної для кожного із спостережень
розглядається як ваговий коефіцієнт цього спостереження у загальній
вибірці. Якщо для певного спостереження значенням вагової змінної
є 0 або від'ємне значення, або відсутнє значення, то таке спостереження
в результаті зважування виключається з аналізу.
Процедура зважування спостережень проста. Цей етап виконується
в два кроки:
- визначити ваги даних;
- обчислити змінну, значеннями якої будуть відповідні значення
ваг.
Приклад. Ми продовжуємо працювати із даними дослідження,
проведеного у місті Києві у 1991 р. Нехай, за даними державної
статистики, нам відомі такі пропорції:
• за статтю - 46 % становлять чоловіки і 54 % жінки;
• за освітою у чоловіків - 42, 2 % вища освіта, 29, 6 % середня
спеціальна освіта, 22, 2 % середня загальна освіта, 6, 1 % неза-
кінчена середня освіта;
• за освітою у жінок - 47, 4 % вища освіта, 30, 4 % середня спеціальна
освіта, 18, 1 % середня загальна освіта, 4, 1 % неза-
кінчена середня.
Наша мета полягає в тому, щоб обчислити такі ваги, які б відтворювали
в нашому файлі даних зазначені пропорції за статтю та
освітою.
Для того, щоб з'ясувати реальний розподіл за статтю та освітою у
побудуємо двовимірну таблицю для змінних (стать)
та (освіта). Результат обчислень операції Crosstabs... представлений
нижче у таблиці 8.2.
Всього у файлі даних 431 спостереження. Проте в одному спостереженні
не вказана стать респондента, отже таблиця побудована для
430 спостережень, і після зважування ми будемо мати також 430
спостережень (сума всіх ваг для всіх спостережень має дорівнювати 430).
Спостереження із незазначеною статтю респондента в результаті
зважування буде просто викинуто з аналізу.
У побудованій двовимірній таблиці є 8 клітин. Отже, маємо 8
груп спостережень, і для кожної такої групи треба вказати формулу
для обчислення ваги (всі спостереження з однієї групи будуть мати
однакову вагу). Розглянемо верхню ліву клітину таблиці. Вона
містить дані про чоловіків із вищою освітою. Спостереження, що
потрапили до цієї клітини, можна відібрати умовою (vl65=l and
v167=1). Загальний обсяг вибірки після зважування мас бути 430 і 46 %
мають становити чоловіки. Інакше кажучи, після зважування у вибірці
має бути 430x0.46 чоловіків. Серед них 42, 2 % - чоловіки із
вищою освітою. Отже, після зважування у нас має бути
(430*0, 46)*0, 422 чоловіків із вищою освітою. Саме така сума ваг спостережень, що
стосуються чоловіків із вищою освітою. Проте у нашому файлі даних
є 95 чоловіків із вищою освітою. Отже, кожному зі спостережень, що
стосуються цієї групи (тобто спостережень, що відповідають умові
(vl65=1 and vl67=l)) потрібно присвоїти вагу, що обчислюється за
Формулою 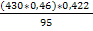
Якщо тепер обчислити за цими формулами значення певної
змінної (категорії цієї змінної матимуть відповідно вісім різних
значень) і вказати цю змінну як вагову, то потрібні нам пропорції за
статтю та освітою будуть відтворені.
Зауваження 1. Якщо ваги є не цілими числами (а, як правило, так
воно завжди і є), то в результаті округлень може виникнути ситуація,
коли сума частот на 1 або 2 об'єкти не збігається із маргінальними
значенням суми у відповідному рядку. Те ж саме і відносно сум
частот у стовпчиках та загальної суми частот у таблиці. Такі розбіжності
не впливають на значення статистичних коефіцієнтів та на
висновки аналізу, але можуть справляти неприємне враження на тих,
хто не знайомий зі специфікою зважування нецілими значеннями.
Зауваження 2. Значення вагової змінної не повинні бути дуже
великими. Ті групи спостережень, для яких обчислене значення ваги
є більшим ніж 1, у зваженій вибірці будуть " штучно збільшені". Ті ж
групи, для яких ваговий коефіцієнт буде менше 1, після зважування
зменшуватимуться. Занадто велике штучне, шляхом зважування,
збільшення певної групи є небажаним. Не потрібно компенсувати
зважуванням невдале планування вибірки або ж її погану реалізацію.
Бажано, щоб значення ваг не перевищували
38. Статистичний висновок.
Спеціальні математичні процедури називають приводних ремнем емпіричного дослідження. В їх основі лежить теорія ймовірностей, що визначає технологію складання вибіркової сукупності та електронної обробки даних. До неї тісно примикає процедура емпіричного узагальнення, звана ще статистичними висновком. У його основі лежить індукція - умовивід від фактів до деякої гіпотези (загальним твердженням).
Статистичний висновок - це індуктивно узагальнення, побудоване на основі математичної обробки і додавання деякого безлічі одиниць дослідження. Ми опитали 1500 виборців і з'ясували, що понад 60% людей похилого віку (старше 60 років) на останніх виборах голосували за комуністів. У даному випадку вивчалася статистична зв'язок двох змінних: вік і електоральне поводження. Звідси можна зробити статистичний висновок: чим більше вік респондента, тим вища ймовірність того, що він проголосує за комуністів. І навпаки.
Статистичний висновок ми отримали після обробки анкет та аналізу первинних даних. Це кількісний висновок. На відміну від нього два інших, розглянутих раніше типу виводу - логічний та теоретико-гіпотетичний - є якісними. Зв'язок між ними наступна. При складанні програми дослідження вчений теоретично постулірует (будує теоретичну гіпотезу) можливість зв'язку між двома змінними - віком та електоральним поведінкою. Пізніше, коли він склав анкети та провів дослідження, при математичної обробки даних будується статистичний висновок. Це дві сторони однієї медалі, перший (вік) служить пробні проектом, теоретичним макетом можливої зв'язку двох змінних, а другий (електоральне поведінка) - його емпіричним підтвердженням.
Статистичний висновок - область імовірнісного знання. Ймовірність - числова характеристика ступеня можливості появи будь-якої випадкової події за тих чи інших певних, які можуть повторюватися необмежену кількість разів умовах. Вона вивчається в теорії ймовірностей - розділ математики, в якому поданим ймовірність одних випадкових подій знаходять ймовірності інших подій, пов'язаних яким-небудь чином з першими. Математична статистика - наука про математичних методах систематизації та використання статистичних даних. Спираючись на теорію ймовірностей, вона дозволяє оцінити, зокрема, необхідний обсяг вибірки для отримання результатів необхідної точності при вибіркових обстежень. Одна з основних задач теорії ймовірностей полягає у з'ясуванні закономірностей, що виникають при взаємодії великого числа випадкових факторів.
|
|