Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

Информационный диагностический тест, близкий к минимальному (метод Синдееева)
|
|
Этот метод реализует безусловный алгоритм диагностики. Основой этого алгоритма является ТФН, у которой столбцы соответствуют всем возможным состояниям, а строки – всем возможным проверкам (проверка π i означает контроль выхода zi). Предполагаем, что все n состояний системы, состоящей из n блоков, равновероятны и сумма вероятностей состояний их отказа равна 1, т.е. проверки, как случайные события, образуют полную группу событий:
P1=P2=…=Pn=  . (8)
. (8)
Тогда с точки зрения теории информации неопределённость (энтропия) Н, создаваемая такой схемой для пользователя, в общем случае определяется с помощью формулы Шеннона:
 ,
,
где Pi – вероятность i – го события (вероятность отказа i – го блока
системы).
Для рассматриваемого случая из (8) получим формулу Хартли:
 , (9)
, (9)
Для определения состояния схемы необходимо провести эксперимент, состоящий в последовательном выборе не более m наиболее информативных проверок (m< n).
Каждая k – ая проверка π k несет некоторое количество информации I относительно начального состояния (начальной энтропии Н0) рассматриваемой схемы (системы).
I=H0-H(π k)=∆ H, (10)
где H(π k) – средняя условная энтропия состояния схемы после проведения проверки π k, k=  .
.
Т.к. при проведении проверки π k имеется только два возможных исхода (положительный π k и отрицательный  ), т.е. π k=1 или =0 с вероятностями соответственно Р(π k) и P(), то средняя условная энтропия Н(π k) равна
), т.е. π k=1 или =0 с вероятностями соответственно Р(π k) и P(), то средняя условная энтропия Н(π k) равна
H(π k)= Р(π k)H(π k)+P()H(), (11)
где Н() и Н(π k) – энтропия состояний схемы после выполнения проверки π k соответственно для отрицательного и положительного её исходов.
Р(π k)=  , (12)
, (12)
Р()=  , k=1…n, (13)
, k=1…n, (13)
где  - число единиц в рассматриваемой k ой строке ТФН.
- число единиц в рассматриваемой k ой строке ТФН.
Тогда подставляя формулы (12) и (13) в формулу (11), а затем (11) в (10) получим с учетом (9):
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
 . (14)
. (14)
Информация по формуле (14) вычисляется для каждой строки ТФН. Первой для теста выбирается проверка π k, которая приносит максимум информации. Если таких проверок несколько, то выбирается любая из них, что возможно, когда информация вычисляется для равновероятных событий (отказов блоков системы) по формуле Хартли.
Если вероятности состояний P(Sj) блоков устройства не одинаковы, то энтропия (неопределенность) в оценке состояния объекта диагностики (ОД) вычисляется по формуле Шеннона (1). В этом случае вероятность отказа P(Sj) j – го блока системы можно оценить по формуле
Pj= P(Sj)=  ,
,
где  - интенсивность отказов j – го блока, час-1;
- интенсивность отказов j – го блока, час-1;
 - интенсивность отказов системы, равное сумме интенсивностей отказов составляющих её блоков.
- интенсивность отказов системы, равное сумме интенсивностей отказов составляющих её блоков.
Строка ТФН, соответствующая лучшей по условию (3) проверке, перемещается на место первой строки ТФН и делит последнюю на две, в общем случае, неравные части, в одну из которых входят столбцы состояний Sj, которым соответствуют “0” в выбранной (лучшей на первом шаге) строке, а в другую – столбцы состояний, которым соответствуют “1” в выбранной строке. Выбранная на первом шаге лучшая по информативности строка больше не участвует в отборах на втором и последующих шагах формирования тестовых проверок.
Успешной (положительной) считается проверка, при которой выход контролируемого блока системы соответствует техническим условиям (ТУ) предприятия-изготовителя. Результаты успешной проверки обозначаются как диагностическая 1. В противном случае проверка считается неуспешной (отрицательной) и обозначается как диагностический 0 в ТФН и других документах.
Выбор второй наиболее информативной проверки проводится одновременно по двум полученным подТФН.
Второй выбирается проверка π i, которая обладает наибольшей условной информацией I(π k/π i) относительно состояния, характеризуемого энтропией H(π k) после первой выбранной проверки.
I(π k/π i)=H(π k) - H(π k/π i) → max (15)
Средняя условная энтропия схемы после 2 ой проверки.
Н(π i/π k)= Р(π i/π k)H(π i/π k)+P( /π k)H( /π k)+
/π k)H( /π k)+
+Р(π k/  )Н (π i/ )+P( / )H( / ), (16)
)Н (π i/ )+P( / )H( / ), (16)
где Р(π i/π k)=  - вероятность второй успешной проверки после
- вероятность второй успешной проверки после
успешной первой. (17)
P( /π k)=  - вероятность второй неуспешной проверки
- вероятность второй неуспешной проверки
после успешной первой. (18)
P(π i/ )=  - вероятность успешной второй после неуспешной первой проверки. (19)
- вероятность успешной второй после неуспешной первой проверки. (19)
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
P( / )=  - вероятность неуспешной второй проверки после неуспешной первой. (20)
- вероятность неуспешной второй проверки после неуспешной первой. (20)
l1 и l2 – число единиц в i-ой строке подТФН №2.1 и подТФН №2.2 соответственно, первая из которых соответствует l-единицам, а вторая – (n-l) – нулям в k ой – строке исходной ТФН. Из формулы (9) следует
H(π i/π k)=  , H( /π k)=
, H( /π k)=  , H(π k/ )=
, H(π k/ )=  ,
,
H( / )=  .
.
Тогда средняя условная энтропия после 2 го шага
 (π i/π k)=
(π i/π k)= 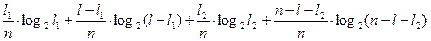 . (21)
. (21)
Информация после 2 го шага для i-той строки будет равна разности выражения в квадратных скобках в уравнении (14) и выражения (21).
Вторая лучшая проверка π i из группы наиболее информативных проверок, записывается второй в исходной ТФН и не участвует в отборе на третьем и последних шагах и т.д.
Выбор проверок продолжается до тех пор, пока средняя угловая энтропия после проверки на каком-то шаге не станет равной нулю. Эта проверка и будет последней в последовательности наиболее информативных, вошедших в тест.
Если отбор проверок для теста заканчивается на m-ом шаге (m< n), то m строк, переставленные вверх по указанным выше правилам в исходной ТФН, автоматически формируют таблицу кодов неисправностей. Причем m – разрядный двоичный код каждой одиночной неисправности читается сверху вниз в каждом столбце ТФН с переставленными вверх наиболее информативными строками (проверками), образующими тестовый набор проверок.
На практике выполняются проверки состояний выходов блоков, вошедших в тестовый набор, в той последовательности, в какой они указаны в тесте. Результат каждой проверки фиксируется в виде диагностической 1 или 0. Комбинация результатов проверок, образующая двоичный код, сравнивается с таблицей кодов неисправностей, которая, как указано выше, автоматически получается из исходной ТФН и состоит из m наиболее информативных строк.
Пример реализации комбинационного метода поиска диагностики неисправностей, реализующего безусловный алгоритм диагностики по методу Синдеева.
Найти информационный тест и таблицу кодов неисправностей для схемы рис.1, в которой имеет место одиночный отказ.
1. Диагностические оценки входных и выходных сигналов:
Z5=0 – const, x1=1 – const, x2=1 – const.

Рис.15
2. Найдем информацию, которую может принести каждая проверка на
первом шаге. В этом случае
I(π k)=H0 - log2n,
где H0 – исходная энтропия.
H0=log25=lg5/lg2=3.332 lg5=2.329бит.
ТФН, соответствующая ФДМ на рис.15 представлена табл. 2.
Таблица 2
ТФН для информационного теста
| Si π i | S1 | S2 | S3 | S4 | S5 | I(π k), бит | I(π i/π k) |
| П1 П2 | 0.729 0.975 | 0.554 - | |||||
| П3 П4 | 0.729 0.975 | 0.55 0.954 |


ТФН 2.1 ТФН 2.2
Определим среднюю условную энтропию Н(π 2) схемы, которую получим в результате проведения проверки π 2. Согласно (4) и (7)
H(π k)=  .
.
Для второй проверки
Н(π 2)=  бит
бит
Тогда информация I(π 2), полученная в результате проведения проверки π 2, составит:
I(π 2)=H0-H(π 2)
I(π 2)=2.329-1.354=0.975 бит.
I(π 1)=  бит,
бит,
I(π 3)=  бит,
бит,
I(π 4)=  бит.
бит.
Столбец с вычисленными количествами информации поместим 6-ым в таблицу 1 функций неисправностей (ТФН), соответствующую функционально-диагностической модели (ФДМ) устройства на рис.1. На пересечении j-го столбца и i-й строки π i в таблице 1 ставится “1”, если при возникновении одиночной неисправности в j-ом блоке устройства сигнал на выходе i-го блока остается соответствующим техническим условиям (ТУ) его эксплуатации и ставится “0” в противном случае.
Первой в тест выбираем проверку π 2 (контроль выхода блока 2), т.к. она приносит максимум информации и “удачно” делит исходную ТФН на две неравные части ТФН 2.1 и ТФН 2.2, первой из которых соответствуют нули в выбранной строке π 2, а второй - “1”.
3. На втором шаге определим среднюю условную энтропию после второй проверки, которая включает оставшиеся проверки π 1, π 3, π 4. Например,
H(π 1/π 2)=  бит.
бит.
Тогда I(π 1/π 2)= 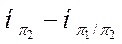 =1.354-0.8=0.554 бит.
=1.354-0.8=0.554 бит.
Аналогично H(π 3/π 2)  =0.4+0.4=0.8 бит.
=0.4+0.4=0.8 бит.
I(π 3/π 2)=1.354-0.8=0.554 бит.
Затем H(π 4/π 2)=  =0.4 бит,
=0.4 бит,
Следовательно I(π 4/π 2)=1.354-0.4=0.954 бит.
Вычисленные количественные оценки информации на втором шаге I(π i/π k) поместим в 7-ом столбце табл. 2.
Анализируя содержимое этого столбца, на втором шаге выбираем 4 ую проверку π 4 т.к. она несет наибольшее количество информации относительно энтропии, оставшейся после 1 ой, выбранной нами проверки π 2.
4. Перед выбором третьей информативной проверки перенесем на вторую строку исходной ТФН содержимое строки π 4, соответствующей выбранной проверке. Указанная ситуация отображена в табл. 3, где место первой строки занимает информация строки (проверки) π 2, выбранной на первом шаге. Тогда остаются две альтернативные проверки π 1 и π 3. Содержимое строк π 1 и π 3 распределяется в таблице 2 по четырем подТФН, причем ТФН 3.1 и ТФН 3.2 строятся на базе ТФН 2.1, а ТФН 3.3 и ТФН 3.4 - на базе ТФН 2.2.
Таблица 3.
ТФН для выбора 3-ей проверки теста
| Si π i | S1 | S2 | S3 | S4 | S5 | I(π f/π 4/π 2) |
| П2 П4 | - - | |||||
| П1 П3 | 0.4 |




ТФН 3.1 ТФН 3.2 ТФН 3.3 ТФН 3.4
 |
ТФН 2.1 ТФН 2.2
ТФН 3.2, 3.3 и 3.4 вырождаются в столбцы, что облегчает выбор проверок и указывает на быстрое завершение формирования теста.
Информация, доставляемая третьей проверкой I(π n/π m/π k) определяется по формуле:
I(π n/π m/π k)=H(π m/π k)-H(π n/π m/π k).
Например, если третьей будет проверка π 1, то
H(π 1/π 4/π 2)= 
т.е. I(π 3/π 4/π 2)= 0.4-0 = 0.4 бит.
Если третьей будет π 3, то
H(π 3/π 4/π 2)=
 бит.
бит.
Следовательно, I(π 3/π 4/π 2)=0.4-0.4=0 бит, т.е. проверки надо прекратить!
Располагая проверки π 2, π 4, π 1 последовательно друг за другом, получим таблицу кодов неисправностей с трёхразрядными двоичными кодами одиночных неисправностей, которые могут иметь место в устройстве на рис.15. Такое расположение проверок сформировано в табл. 2. Код неисправности 1-го блока (состояние устройства S1) составляет 010, код состояния S2 – 011, код состояния S3 – 001, код состояния S4 – 101 и код состояния S5 –111.
Выполняя на практике последовательно проверки π 2, π 4, π 1 (проверяя выходы Z2, Z4, Z1) и фиксируя результаты проверок в виде диагностических “0” или “1”, получают трёхразрядную двоичную комбинацию и идентифицируют неисправность в устройстве, сравнивая полученную комбинацию с таблицей кодов неисправностей.
1.10. Метод критерия различимости – комбинационный метод, реализующий безусловный алгоритм диагностики
1) Постановка задачи
Проблема заключается в том, что разработать набор тестов, который будет иметь дело со всеми неисправностями цифровой системы. Однако, одни методы генерирования тестов вырабатывают их лишь для однократной специфической неисправности, не пригодны в столь больших схемах. Очевидное решение – применить некоторый метод многократно до полной обработки неисправностей. А затем полученные тесты объединить. Однако набор тестов, полученных таким способом неприемлем из-за емкости потребляемой памяти и времени обработки. Отсюда возникает задача сокращение объема набора теста.
2) Таблица неисправностей – используется для представления результатов генерирования тестов, является двух мерным массивом, имеющем по одной строке на каждую неисправность и по одному столбцу на каждый тест. Для элемента таблицы  :
:
=1, если  -я неисправность обнаруживается
-я неисправность обнаруживается  -м тестом и
-м тестом и
=0 – в противном случае.
Строка называется отображениями неисправности и является вектор–строками,  - отображение -й неисправности. Два отображения неисправности
- отображение -й неисправности. Два отображения неисправности  и
и  различимы
различимы  , если
, если  для некоторого
для некоторого  , где - номер теста. Таким образом задача трансформируется в задачу нахождения минимального набора столбцов таблицы так, чтобы каждая строка, соответствующей подтаблицы имела бы по крайней мере одну «1». Чтобы различать все неисправности необходим минимальный набор столбцов, соответствующий вышеизложенным требованиям и имеющий все различимые строки.
, где - номер теста. Таким образом задача трансформируется в задачу нахождения минимального набора столбцов таблицы так, чтобы каждая строка, соответствующей подтаблицы имела бы по крайней мере одну «1». Чтобы различать все неисправности необходим минимальный набор столбцов, соответствующий вышеизложенным требованиям и имеющий все различимые строки.
3) Метод критерия различимости.
Основная идея – в приписывании весов отдельным тестам. Веса отражают относительную способность тестов различать неисправности.
На основе весов отбираются тесты для получения эффективного набора тестов.
Вес  теста
теста  определяется как и число пар неисправностей, которые он различает:
определяется как и число пар неисправностей, которые он различает:
 ,
,
где  и
и  - число соответственно «0» и «1» в -м столбце таблицы
- число соответственно «0» и «1» в -м столбце таблицы
Метод строится на последовательности итераций. Вычисляются для всех . Затем в качестве первого выбирается тест с max , так как он различает наибольшее число пар неисправностей. Этот тест делит неисправности на обнаруживаемые и необнаруживаемые. В общем случае, когда выбран  -й тест, неисправности будут разделены на
-й тест, неисправности будут разделены на  непересекающихся блоков
непересекающихся блоков  . Это означает, что последующие тесты должны выбираться более сложным путем.
. Это означает, что последующие тесты должны выбираться более сложным путем.
Пусть кандидат на ( ) элемент набора и пусть
) элемент набора и пусть  и
и  - число «0» и «1» в -м столбце блока
- число «0» и «1» в -м столбце блока  . Тогда после -го шага вес для будет равен:
. Тогда после -го шага вес для будет равен:

Тест, для которого  -max, выбирается как
-max, выбирается как  элемент набора тестов. Отбор тестов продолжается до тех пор, пока разделение неисправностей перестанет приносить дальнейшее улучшение, т.е. до тех пор, пока веса всех неиспользованных «тестов» не станет равное «0» (не станет «0» или «1» )
элемент набора тестов. Отбор тестов продолжается до тех пор, пока разделение неисправностей перестанет приносить дальнейшее улучшение, т.е. до тех пор, пока веса всех неиспользованных «тестов» не станет равное «0» (не станет «0» или «1» )
|
|