Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Охарактеризуем каждую разновидность.
|
|
Лекция 6. Методы конструирования выборочных совокупностей
План лекции:
1. Классификация выборочных совокупностей.
2. Краткая характеристика методов конструирования выборочных совокупностей.
В зависимости от характера организации отбора единиц из генеральной совокупности различается много разновидностей выборок, которые можно классифицировать по трем критериям:
- по способу отбора единиц, образующих выборочную совокупность;
- по числу ступеней отбора;
- по степени преобразования генеральной совокупности.
В научной литературе существует множество различных классификаций выборочных обследований.
Чаще всего в практике социологических исследований используются следующие виды выборочных совокупностей:
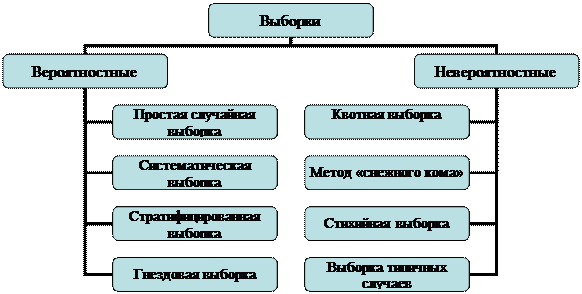
Охарактеризуем каждую разновидность.
Простая случайная выборка –вероятностный метод выборки, согласно которому каждый элемент генеральной совокупности имеет известную и равную вероятность отбора. Каждый элемент выбирается независимо от каждого другого элемента, и выборка формируется произвольным отбором элементов из основы выборки. Этот метод похож на розыгрыш лотереи, когда таблички с именами участников помещаются в барабан, который встряхивается, и из него произвольным образом извлекают отдельные таблички, в результате объективно определяются имена победителей.
При простой случайной выборке исследователь сначала формирует основу выборочного наблюдения, в которой каждому элементу присваивается уникальный идентификационный номер. Затем генерируются случайные числа, чтобы определить номера элементов, которые будут включены в выборку. Эти случайные числа могут генерироваться компьютерной программой.
Простая случайная выборка имеет очевидные преимущества. Этот метод крайне прост для понимания. Результаты исследования можно распространять на изучаемую совокупность. Большинство подходов к получению статистических выводов предусматривают сбор информации с помощью простой случайной выборки. Однако метод простой случайной выборки имеет как минимум четыре существенных ограничения:
1.Сложно создать основу выборочногo наблюдения, которая позволила бы провести простую случайную выборку.
2.Результатом применения простой случайной выборки может стать большая совокупность, либо совокупность, распределенная по большой географической территории, что значительно увеличивает время и стоимость сбора данных.
3.Результаты применения простой случайной выборки часто характеризуются низкой точностью и большей стандартной ошибкой, чем результаты применения других вероятностных методов.
4. В результате применения простой случайной выборки может сформироваться нерепрезентативная выборка. Хотя выборки, полученные простым случайным отбором, в среднем адекватно представляют генеральную совокупность, некоторые из них крайне некорректно представляют изучаемую совокупность. Вероятность этого особенно велика при небольшом объеме выборки.
Систематическая выборка – вероятностный метод выборки, в соответствии с которым сначала задают произвольную отправную точку, а затем из основы выборочного наблюдения последовательно выбирают каждый i-й элемент.
Обшей чертой систематической выборки и простой случайной выборки является то, что каждый элемент генеральной совокупности имеет известную и равную вероятность выбора.
При систематической выборке исследователь предполагает, что элементы совокупности расположены в определенном порядке. В некоторых случаях принцип сортировки (например, алфавитный перечень в телефонной книге) не имеет отношения к исследуемой характеристике. В других случаях сортировка непосредственно связана с исследуемой характеристикой. Например, имена владельцев кредитных карточек приводятся с учетом суммы их баланса, а названия фирм определенной отрасли располагаются согласно годовому объему их продаж. Если элементы совокупности расположены по принципу, не связанному с исследуемой характеристикой, результаты систематической выборки аналогичны результатам простой случайной выборки.
С другой стороны, если принцип расположения элементов связан с исследуемой характеристикой, систематический отбор увеличивает репрезентативность выборки. Если фирмы какой-либо отрасли расположены по принципу увеличения годового объема продаж, систематическая выборка будет включать как мелкие, так и крупные фирмы. Простая случайная выборка в данном случае может быть нерепрезентативной, включая, например, только мелкие фирмы или непропорциональное число мелких фирм. Если расположение элементов выборки носит циклический характер, систематическим методом можно уменьшать представительность выборки. В качестве примера рассмотрим применение систематического отбора для формирования выборки ежемесячных объемов продаж универмага из основы, содержащей ежемесячные объемы продаж за последние 60 лет. Если задать выборочный интервал, равный 12, то конечная выборка не будет отражать ежемесячные изменения в объемах продаж.
Систематическая выборка дешевле и проще, чем простая случайная, поскольку случайный отбор осуществляется только один раз. Кроме того, случайные числа не должны соответствовать определенным элементам, как в простой случайной выборке. Учитывая, что некоторые перечни содержат миллионы элементов, использование этого метода значительно экономит время, что, в свою очередь, способствует снижению затрат, связанных с исследованием. Если совокупность обладает информацией об исследуемой характеристике, систематический отбор дает возможность получить более репрезентативную и достоверную (с меньшей ошибкой выборки) выборку, чем метод простой случайной выборки. Еще одно важное преимущество: систематический отбор можно применять даже не зная структуру основы выборочного наблюдения. Например, можно опросить каждого i-го человека, покидающего универмаг или торговый центр. Поэтому систематический отбор часто применяется при проведении почтовых и телефонных опросов, а также «интервью-перехватов» в торговых центрах.
Стратифицированная выборка – двухэтапный метод вероятностной выборки, согласно которому генеральная совокупность сначала делится на подгруппы или слои (страты). Затем элементы случайным образом выбираются из каждого слоя.
Переменные, используемые для деления совокупности на слои, называются стратификационными переменными. Критерии для их выбора: однородность, неоднородность, взаимосвязанность и стоимость. Элементы, относящиеся к одному слою, должны быть как можно более однородными, а относящиеся к разным слоям – наоборот, как можно более разнородными.
Как правило, для стратификации используют демографические характеристики.
Для стратификации можно использовать несколько переменных, однако больше двух применяют редко, поскольку это непрактично и экономически неоправданно. Несмотря на то, что количество слоев в расслоенной выборке остается предметом спора, опыт показывает, что использовать нужно не больше шести. При использовании больше шести слоев любое повышение точности сводится на нет увеличением стоимости расслоения и отбора.
Другое важное решение связано с использованием пропорциональной или непропорциональной выборки. При пропорциональном стратификационном отборе объем выборки, полученной из каждого слоя, пропорционален доле этого слоя в объеме генеральной совокупности. При непропорциональном стратификационном отборе объем выборки, полученной из каждого слоя, пропорционален доле этого слоя в объеме генеральной совокупности и среднеквадратичному отклонению распределения исследуемой характеристики среди всех элементов этого слоя. Логика непропорциональной выборки проста. Во-первых, слои относительно большего размера больше влияют на определение средней для генеральной совокупности. Следовательно, эти слои больше влияют на формирование результатов выборочного наблюдения. Таким образом, слои должны быть представлены большим количеством элементов. Во-вторых, для повышения точности оценки следует отбирать больше элементов из слоев с большим среднеквадратичным отклонением, и меньше элементов – из слоев с меньшим среднеквадратичным отклонением. Если все элементы слоя идентичны, выборка, состоящая из одного элемента, обеспечит получение полной информации. Обратите внимание, что эти методы идентичны при условии, что исследуемая характеристика имеет одно и то же среднеквадратичное отклонение в каждом слое.
При применении непропорционального отбора необходимо рассчитать среднеквадратичное отклонение распределения исследуемой характеристики среди элементов слоя. Поскольку эта информация не всегда доступна, исследователю часто приходится полагаться на интуицию и логику, определяя объем выборки для каждого слоя. Например, в крупных розничных магазинах можно ожидать большего отклонения в объемах продаж некоторых продуктов, чем в небольших магазинах. Поэтому крупные магазины представлены в выборке непропорционально большим количеством элементов. Когда исследователя в первую очередь интересует выявление различий между слоями, обычно создают одинаковые по объему выборки из каждого слоя.
Стратификационный метод обеспечивает наличие в выборке всех важных подгрупп. Это особенно важно, если исследуемая характеристика неравномерно распределена среди элементов генеральной совокупности. Например, распределение дохода семей неравномерно, так как годовой доход большинства семей составляет меньше 50 тысяч долларов, и лишь немногие семьи имеют годовой доход, равный 125 тысяч долларов и выше. Если применить простую случайную выборку, семьи с доходом 125 тысяч долларов и выше могут не быть адекватно представлены. Стратифицированная выборка позволяет обеспечить соответствующее количество таких семей в выборке. Она сочетает в себе простоту метода простой случайной выборки с возможностью повышения точности. Поэтому данный метод формирования выборки весьма популярен.
Гнездовая выборка – сначала изучаемая совокупность делится на взаимоисключающие и взаимодополняющие подгруппы, называемые гнездами (кластерами). Затем с помощью вероятностного метода выборки, такого как простая случайная выборка, отбираются гнезда (кластеры). В выборку включаются либо все элементы отобранного гнезда (кластера), либо проводится их отбор вероятностным методом.
Основное различие между гнездовой и стратифицированной выборкой состоит в том, что в первом случае используются только отобранные подгруппы (гнезда), в то время как в стратифицированной выборке все подгруппы (слои) используются для дальнейшего отбора. Эти методы преследуют разные цели.
Цель гнездовой выборки – увеличить эффективность выборки, уменьшив затраты на ее проведение. Цель стратифицированной выборки – увеличение точности. По однородности и неоднородности критерии формирования кластеров прямо противоположны критериям формирования слоев. Элементы кластера должны быть максимально разнородны, а сами кластеры – как можно более однородными. В идеале каждый кластер должен представлять собой небольшую модель генеральной совокупности. При кластерной выборке основа выборочного наблюдения необходима только для кластеров, которые вошли в выборку.
Распространенная форма гнездовой выборки – территориальная выборка, в которой гнезда состоят из географических территорий, таких как округа, жилые районы или кварталы. Если отбор основных элементов проводится в один этап (например, исследователь выбирает некоторые кварталы, а затем все семьи, живущие в этих кварталах, включаются в выборку), такой выборочный метод называется одноступенчатой территориальной выборкой. Если отбор основных элементов проводится в два (или больше) этапа (исследователь выбирает кварталы, а затем в каждом таком квартале отбирает семьи, которые будут включены в выборку), такой метод называется двухступенчатой (или многоступенчатой) территориальной выборкой. Отличительная черта одноступенчатой территориальной выборки заключается в том, что все семьи из выбранных кварталов (или географических регионов) включаются в выборку.
Квотная выборка – микромодель объекта социологического исследования, формируемая на основе статистических сведений (параметров квот) преимущественного о социально-демографических характеристиках элементов генеральной совокупности.
Принцип выборки квотной, или же принцип отбора единиц наблюдения по методу квот (англ. quota), восходит к представлению о подобии объектов в случае пропорциональности их структурных элементов. Идея о правомерности экстраполяции результатов модели на моделируемый объект в случае подобия их структур была общепринята в статистической практике задолго до построения теории вероятностной выборки. В частности, применение подобного метода выборки для прогноза урожайности сельскохозяйственных культур предписывалось еще Петром I в «Регламенте или Уставе конюшенном».
Квотный метод выборки отличается от вероятностного тем, что предполагает предварительное наличие статистических сведений по ряду существенных либо коррелирующих с ними характеристик генеральной совокупности. Однако эти сведения не используются для определения объема выборки, т.к. в последующем отбор респондентов осуществляется не случайно, а целенаправленно, при помощи интервьюеров. Поэтому в случае применения квотной выборки ее величина определяется на основании сложившегося десятилетиями опыта и составляет от 1000 до 2500 единиц наблюдения, в зависимости от сложности структуры исследуемого объекта.
Общей проблемой, как вероятностной выборки, так и квотной выборки являются затруднения, возникающие при выделении существенных характеристик объекта исследования. До начала исследования статистические данные о них, как правило, отсутствуют, поэтому в качестве параметров квот приходится выбирать числовые значения, тесно коррелирующие с существенными (исследуемыми) контрольными признаками.
Число характеристик, данные о которых выбираются в качестве квот, как правило, не превышает четырех. При большем числе фиксированных признаков отбор респондентов становится чрезмерно трудоемким.
Квоты могут быть заданы как по независимым, так и по взаимосвязанным параметрам. Квота с независимыми параметрами есть не что иное, как статистические данные о значениях контрольных признаков, взятых каждый в отдельности.
Квоты со взаимосвязанными параметрами являются статистическими данными, полученными в результате группировки первичной информации по двум или нескольким признакам.
Параметры квот в процентном выражении в точности воспроизводят структуру генеральной совокупности по контрольным признакам.
Число подлежащих опросу респондентов в соответствии с заданными квотами вычисляется путем умножения параметров квот на коэффициент k = n/100, где n – объем выборочной совокупности.
Слишком большое число параметров квот затрудняет работу интервьюеров, ведет к увеличению систематической ошибки. Поэтому в модели квотной выборки, как правило, опускают признаки, которые тесно коррелируют с какой-либо другой характеристикой, параметры которой также используются в качестве квот.
Степень репрезентативности квотной выборки повышается прямо пропорционально степени устойчивости значений характеристик, по которым задаются квоты, в связи с чем признаки, изменяющие свои значения слишком быстро, в модели выборки квотной применяются весьма редко.
Проверка эффективности выборки квотной обычно осуществляется при помощи ее сравнения с вероятностной выборкой. Из одной и той же генеральной совокупности извлекают две выборочные совокупности с тождественными объемами. Одна из выборочных совокупностей формируется вероятностным, другая квотным методом. Опрос проводится по обеим выборочным совокупностям, а результаты сравниваются между собой.
Метод квот позволяет существенно сократить время, затрачиваемое на опросы: интервьюер в случае задания ему параметров квот может осуществить интервью вдвое быстрее, чем при вероятностной выборке.
Выборка методом снежного кома – это разновидность типовой выборки, применяемой в случае необходимости контакта с небольшой специфической группой. Например, если необходимо собрать экспертную информацию о новой технологии, методом снежного кома можно сформировать выборку преподавателей технических вузов. При использовании выборки методом снежного кома каждого респондента после интервью просят порекомендовать одного или нескольких аналогичных специалистов.
Проблема выборки методом снежного кома состоит в том, что ведущие более активный образ жизни имеют больше шансов попасть в выборку.
Стихийная выборка. Исследователь при применении данного метода в некоторой степени контролирует выборку (например, публикуя анкету в журнале, он обращается только к читателям этого журнала), но решение о включении в выборку принимает сам респондент. То есть, её размер заранее часто не известен, а определяется конкретным условием – активностью респондентов. Значит, нельзя и заранее определить структуру массива респондентов, которые заполнят и вернут анкеты. Поэтому этот метод не претендует на репрезентативность выборки, а выводы исследования очень часто распространяются только на опрошенную совокупность.
Сферы применения стихийной выборки:
1. анкеты, публикуемые в газетах и журналах;
2. почтовые опросы;
3. опросы покупателей в залах супермаркетов;
4. опрос пассажиров на остановках и в общественном транспорте;
Выборка типичных случаев. При использовании данного метода отбираются единицы генеральной совокупности, обладающие средним (или типичным) значением признака в статистическом отношении. Однако в таком случае встает проблема выбора признака и определения его типичного значения. Субъективный характер оценки вполне может привести к систематической ошибке. Данный метод целесообразно применять для изучения таких объектов, о которых мы уже обладаем некоторой информацией, например, территориальных общностей, предприятий, учреждений и т.п. То есть, он осуществляется на основе анализа демографических данных и предварительных социологических исследований.
Цель такого типа выборки сводится к иллюстрированию, иначе говоря, она предполагает качественное описание типичного социального феномена с использованием соответствующих методов. Так, например, изучение типичных негосударственных школ позволит выяснить проблемы негосударственного допрофессионального образования[1].
Рекомендуемая литература:
1. Девятко И.Ф. Методы социологического исследования. 3-е изд. М.: КДУ, 2003. 296 с.
2. Зборовский Г.Е., Шуклина Е.А. Прикладная социология: Учебное пособие. М.: Гардарики, 2004. 176 с.
|
|