Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

⚡️ Для новых пользователей первый месяц бесплатно. А далее 290 руб/мес, это в 3 раза дешевле аналогов. За эту цену доступен весь функционал: напоминание о визитах, чаевые, предоплаты, общение с клиентами, переносы записей и так далее.
✅ Уйма гибких настроек, которые помогут вам зарабатывать больше и забыть про чувство «что-то мне нужно было сделать».
Сомневаетесь? нажмите на текст, запустите чат-бота и убедитесь во всем сами!
Лекция 16. Статистический анализ социологических данных
|
|
План лекции:
1. Сводка и группировка первичной социологической информации.
2. Процедуры статистического анализа социологических данных.
В ходе исследований социологи собирают большие объемы информации. Чтобы сделать на их основе определенные выводы, необходимо всю информацию сжать, представить в виде небольшого числа обобщающих (статистических) показателей, удобных для дальнейшего анализа. Для решения этой задачи применяются методы математической статистики и компьютерные программы обработки социологической информации.
Сводка и группировка первичной социологической информации представляют собой первый этап работы с ней.
К основным методам математической статистики, получившим распространение в социологии, относятся:
1. Статистическая группировка.
2. Статистические таблицы.
3. Подсчет средних арифметической и геометрической, моды, медианы, среднего квадратичного (стандартного) отклонения и дисперсии.
4. Определение взаимосвязей двух и более признаков при помощи управлений регрессии, корреляционного, дисперсионного, факторного и других методов.
5. Определение статистических ошибок.
6. Проверка статистических гипотез.
7. Графические методы.
Самым начальным этапом является статистическая группировка, которая позволяет распределить единицы изучаемого объекта на однородные группы по существенным для него признакам. Выбор группировочного признака зависит от целей исследования. Ряды распределения (вариационные ряды) представляют собой результат группировки единиц наблюдения по одному признаку.
Когда данные сгруппированы, можно посмотреть, какова абсолютная частота, то есть число наблюдений в данной выборке, попадающих в интересующую нас категорию, и относительная частота (процент). Доли процентов не существенны для интерпретации полученных результатов. Поэтому в представлении данных обычно используют процедуру округления. Определив необходимую степень точности, исследователь может округлить все полученные числовые значения до десятых долей или до целых процентов. В результате процедуры округления исследователь фактически устанавливает границы классов, объединяющих значения переменной в заданном интервале, и середины (центры) классов, то есть усреднённые значения для каждого интервала. Независимо от того, какие статистические методы и модели собирается использовать исследователь, первым шагом в анализе данных всегда является построение частотных распределений для каждой изучавшейся переменной. Полученные результаты принято представлять в виде таблицы частотного распределения для каждой существенной переменной. Примером табличного представления может служить приведённая ниже таблица.
Частотное распределение профиля образования в вузе
| Профиль образования в вузе | Абсолютная частота, чел. | Относительная частота, % |
| Технический | ||
| Социально-экономический | ||
| Гуманитарный | ||
| Естественнонаучный | ||
| Всего: |
Иногда в таблице распределения указывают лишь относительные частоты, опуская абсолютные.
Помимо табличного представления частотных распределений обычно используют и методы графического представления. Самый распространённый метод графического представления одномерных распределений – это гистограмма, или столбиковая диаграмма. Каждый столбик соответствует интервалу значений переменной, причём его середина совмещается с серединой данного интервала. Высота столбика отражает частоту (абсолютную или относительную) попадания наблюдавшихся значений переменной в определённый интервал. Масштаб шкалы обычно выбирают так, чтобы общая высота гистограммы составляла приблизительно 40-60% её ширины.
Желание выпускников участвовать во встречах с преподавателями кафедры
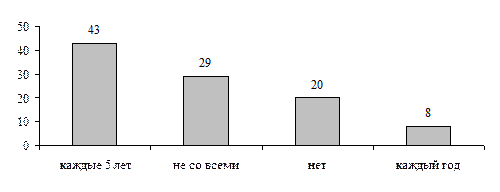
Часто в социологических исследованиях используют динамические ряды (временные ряды, ряды динамики), представляющие собой изменения значения признака по годам (месяцам). Например:
| Год | ||||||
| Количество кинопосещений |
Хотя результаты одномерного анализа данных часто имеют самостоятельное значение, большинство исследователей уделяют основное внимание анализу связей между переменными. Статистические таблицы представляют собой группировку и распределение респондентов по двум или более признакам.Самым простым и типичным является случай анализа взаимосвязи (сопряжённости) двух переменных. Устойчивый интерес социологов к двумерному и многомерному анализу данных объясняется желанием проверить гипотезы о причинной зависимости двух и более переменных. Так как возможности социологов проверять причинные гипотезы с помощью эксперимента ограниченны, основной альтернативой является статистический анализ неэкспериментальных данных.
В общем случае для демонстрации причинно-следственного отношения между двумя переменными необходимо выполнить следующие требования:
1. показать, что существует эмпирическая взаимосвязь между переменными;
2. исключить возможность обратного влияния переменных.
3. Убедиться, что взаимосвязь между переменными не может быть объяснена зависимостью этих переменных от какой-то дополнительной переменной (или переменных).
Первым шагом к анализу взаимоотношений двух переменных является построение таблицы сопряжённости. Эта таблица содержит информацию о совместном распределении переменных.
Допустим, в результате одномерного анализа данных мы установили, что студенты сильно различаются по уровню наличия свободного времени: некоторые говорят о его полном отсутствии, другие – о своей полной свободе. Мы предполагаем, что причина этих различий – какая-то другая переменная, например успеваемость.
Мы располагаем данными о наличии свободного времени и успеваемости для выборки студентов. Для простоты предположим, что обе переменные имеют два уровня – высокий и низкий. Для свободного времени воспользуемся двумя категориями – «нет свободного времени», «много свободного времени»; для успеваемости – «хорошая успеваемость», «плохая успеваемость». Таблица показывает, как могло бы выглядеть совместное распределение этих двух переменных.
Взаимосвязь между наличием свободного времени и успеваемостью студентов
| Наличие свободного времени | Успеваемость | Всего | |
| хорошая успеваемость | плохая успеваемость | ||
| Нет свободного времени | |||
| Много свободного времени | |||
| Всего |
В таблице два столбца (для успеваемости) и две строки (для свободного времени), следовательно, размерность таблицы 2 х 2, кроме того, имеются дополнительный крайний столбец (справа) и нижняя строка (маргиналы таблицы), указывающее общее количество наблюдений в данной строке или в столбце. В правом нижнем углу указана общая сумма, то есть общее число наблюдений в выборке. Существует неписаное правило: для той переменной, которую полагают независимой, отводится верхняя строка (горизонталь), а зависимую располагают «сбоку», по вертикали.
Так как вывод о наличии взаимосвязи между переменными требует демонстрации различий между подгруппами по уровню зависимой переменной, при анализе таблицы сопряжённости можно руководствоваться простыми правилами.
- Нужно определить независимую переменную и пересчитать абсолютные частоты в проценты. Для этого нужно разделить их на маргинальные частоты и умножить на 100. Если независимая переменная расположена по горизонтали таблицы, считаются проценты по столбцу; если независимая переменная расположена по вертикали, проценты берутся от сумм по строке.
- Далее сравниваются процентные показатели, полученные для подгрупп с разным уровнем независимой переменной, каждый раз внутри одной категории зависимой переменной (например, внутри категории имеющих много свободного времени). Обнаруженные различия свидетельствуют о существовании взаимосвязи между двумя переменными.
Элементарная таблица сопряжённости размерности 2 х 2 – это минимальное необходимое условие для вывода о наличии взаимосвязи двух переменных. Знаний о распределении зависимой переменной недостаточно. Варьировать должна не только зависимая, но и независимая переменная.
Наиболее широко применяются в социологических исследованиях средние арифметические величины.
Ряды распределения и подсчитанные на их основе средние арифметические величины, а также ряды динамики позволяют описать социальное явление, событие, процесс, но не дают возможности выяснить причины. А вот на основе статистических таблиц можно составить некоторое представление о причинно-следственных связях, поскольку таблица показывает, как с изменением одного признака изменяется другой.
Ответ на вопрос о причинно-следственных связях дают такие методы математической статистики, как корреляционный, дисперсионный, факторный анализ и др.
Корреляционный метод анализа заключается в подсчете коэффициента корреляции, который характеризует плотность связи между двумя признаками. Достоинства коэффициентов корреляции заключаются в том, что они позволяют представить информацию в компактном виде. Один коэффициент заменяет таблицу, в которой может быть 20-30 цифр.
Затем наступает этап анализа информации. Качественный анализ информации заключается в сопоставлении ранее установленных фактов, в выявлении связей или закономерностей и описании их с указанием условий и ситуаций, при которых они имеют место.
С содержательной точки зрения анализ социологических данных – это процедура проверки исходных гипотез, выдвижение и верификация новых предположений в случае неподтверждения исходных, а также процесс интерпретации и объяснения эмпирических данных посредством их включения в определенный социальный контекст.
Этот анализ включает в себя 3 стадии: описание полученных данных, их интерпретация и прогноз возможных объяснений. Каждая стадия предполагает использование соответствующих процедур анализа:
| Стадии | Процедуры анализа |
| Описание данных | Группировка и типологизация |
| Интерпретация данных | Логико-аналитические процедуры |
| Прогноз возможных изменений | Экстраполяция, моделирование, экспертиза |
Описание данных – последовательное, полное и логически связанное фиксирование элементного состава, свойств и связей изучаемого объекта (явления, процесса), т.е. его структуры, на основе полученной эмпирической информации.
Описание осуществляется в несколько этапов:
1. группировка – упорядочение данных по отдельным признакам, изучение простых распределений.
2. обобщение информации, выявление типических групп, подлежащих дальнейшему анализу. Это приводит к сокращению переменных и создает возможность сравнивать сгруппированные данные с данными других исследований, между собой, с другими родственными внешними признаками.
В основе эмпирической типологизации лежат формирование типологических групп по нескольким одновременно заданным критериям и установление устойчивых сочетаний свойств социальных объектов (явлений), которые рассматриваются в многомерном социальном пространстве.
Для установление константных сочетаний свойств социальных объектов используется кластерный анализ – метод, позволяющий провести классификацию сразу по многим признакам. Кластерный анализ позволяет разделить совокупность данных на однородные группы таким образом, что различия между объектами одной группы оказываются значительно меньшими, чем между объектами разных групп. Критерием различия (сходства) для количественных признаков чаще всего выступают меры расстояния в евклидовом пространстве, для качественных – меры связи или подобия (хи-квадрат, коэффициент Юла и др.).
Выявлению структурных взаимосвязей явлений способствует факторный анализ. Его задача – нахождение методов перехода от некоторого числа относительно легко измеряемых признаков изучаемого явления к некоторому числу стоящих за ними внешне незамечаемых факторов, наличие которых можно лишь предполагать. Наименование, которые даются выделенным факторам, условны и подбираются по ассоциации с теми признаками, которые наиболее тесно связаны с данным фактором, т.е. имеют наибольшую факторную нагрузку. Под факторной нагрузкой понимается значимость того или иного признака в выделившейся группе переменных. Таким образом, факторный анализ позволяет взвесить значимость каждого из элементов изучаемого явления (процесса) в общей структуре последнего.
Интерпретация данных – это совокупность значений, смыслов, которые придаются исследователем полученной эмпирической информации.
Для того, чтобы интерпретация оказалась относительно правильной, она должна быть тесно связана с конкретным содержанием той сферы социальной жизни, к которой она относится.
Именно на основе сформированной интерпретативной схемы проводится проверка исходных гипотез, их дополнение и уточнение.
Процедура прогноза – это вероятностное суждение о развитии изучаемого объекта в будущем.
Необходимо отметить, что прогнозирование возможно только при наличии результатов серии повторных исследований, позволяющих раскрыть устойчивую тенденцию изменения социального объекта во времени.
Использованная литература:
1. Аверин Ю.П. Теоретическое построение количественного социологического исследования: учебное пособие. М.: КДУ, 2009. 440 с.
2. Елисеева И.И., Рукавишников В.О. Логика прикладного статистического анализа. М., 1982.
3. Миркин Б.Г. Анализ качественных признаков и структур. М., 1980.
4. Смехнова Г.П. Основы прикладной социологии. М.: Вузовский учебник, 2012. 252 с.
5. Татарова Г.Г. Методология анализа данных в социологии. М., 1998.
6. Татарова Г.Г. Основы типологического анализа в социологических исследованиях. Учебное пособие. М.: Издательской Дом «Высшее Образование и Наука», 2007. 236 с.
7. Толстова Ю.Н. Анализ социологических данных: методология, дескриптивная статистика; изучение связей между номинальными признаками. М., 2000.
8. Толстова Ю.Н. Логика математического анализа социологических данных. М., 1991.
9. Тюрин Ю.Н. Статистический анализ данных на компьютере / Ю.Н. Тюрин, А.А. Макаров. М., 1998.
10. Фелингер А.Ф. Статистические алгоритмы в социологических исследованиях. М., 1985.