Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

Введение в настройку SQL-выражений
|
|
Настройка SQL-выражений – наименее ресурсозатратный способ повышения производительности системы в целом. Здесь не требуется вкладывать финансовые средства в обновление аппаратуры, нет необходимости нанимать дополнительных сотрудников, изменять бизнес-логику приложения. Правильно же настроенные SQL-выражения даже в режимах высокой нагрузки смогут обеспечить приемлемую скорость обработки данных.
Как обрабатываются SQL-выражения
Любое SQL-выражение, перед тем, как быть выполненным, проходит некоторые стадии.
- Разбор (parsing) – синтаксический (правильность написания операторов) и семантический (состояние объектов БД, участвующих в выражении, наличие привилегий на работу с объектами) анализ выражения;
- Получение оптимального метода возвращения результата SQL-выражения с помощью оптимизатора (optimizer).
- Получение окончательного плана выполнения SQL-выражения. Подготовка древообразного набора источников строк, составящих результирующий набор строк.
- Выполнение SQL-выражения. Отработка ранее созданного плана выполнения. Получение результирующего набора строк.
Первые три этапа – компиляция SQL-выражения перед выполнением. Наиболее важным из них является этап работы оптимизатора. Каждое SQL-выражение может быть выполнено различными способами: с использованием тех или иных индексов, различным порядком доступа к таблицам и др. Задача оптимизатора – выбрать наиболее оптимальный вариант получения результата SQL-выражения.
Оптимизатор
В СУБД Oracle 10gсуществуют 2 типа оптимизаторов:
- Оптимизатор по правилам (Rule Based Optimizer - RBO);
- Стоимостной оптимизатор (Cost Based Optimizer - CBO).
Поддержка оптимизатора по правилам оставлена для обратной совместимости. Для настройки SQL-выражений рекомендуемым оптимизатором является стоимостной.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
CBO – это математический процессор. Он использует формулы для вычисления стоимости (cost) оператора SQL. Стоимость, по сути, приводится к числу физических операций ввода/вывода, то есть к числу логических операций ввода/вывода, которые привели к запросам подстистемы ввода/вывода вместо полной обработки оператора SQL в буферном кэше в Oracle SGA.
Подсчет операций логического чтения намного проще, и это как раз то, что делает CBO. Стоимостной оптимизатор учитывает информацию в словаре данных о размере таблиц и индексов, количестве строк в таблицах, количестве различных (distinct) ключей в индексах, числе уровней в B*-Tree индексе, среднем числе блоков таблицы на отдельное значение, среднем числе листьевых (leaf) узлов на отдельное значение. Он также знает, как работают методы соединения (join) таблиц, знает информацию о селективности (selectivity) данных в столбцах (или ее отсутствии) из гистограмм в словаре данных, знает различия в работе B*-Tree и Bitmap индексов.
Учитывая все эти вещи, формулы, встроенные в CBO (которые Oracle не разглашает), могут быстро и аккуратно определить, как много операций логического чтения можно ожидать для каждого из нескольких, десятков, сотен или тысяч возможных планов исполнения для любого заданного оператора SQL. CBO будет подсчитывать количество логических операций чтения для всех возможных планов исполнения, пытаться преобразовать их к числу физических операций чтения (стоимости) и выбрать наименьшее результирующее значение.
Получение плана выполнения в SQL*Plus
В SQL*Plus существует возможность получать план-отчет выполнения SQL-выражения (SELECT, INSERT, UPDATE, DELETE), построенного оптимизатором вместе со статистикой выполнения. Отчет генерируется после отработки SQL DML выражения. Данные отчета могут быть весьма полезными для настройки этих выражений.
Выдача отчета регулируется с помощью опции AUTOTRACE SQL*Plus. Варианты включения AUTOTRACE:
| Вариант | Результат |
| SET AUTOTRACE OFF | Генерация отчета не производится. По умолчанию. |
| SET AUTOTRACE ON EXPLAIN | Выдача отчета только с выводом плана выполнения |
| SET AUTOTRACE ON STATISTICS | Выдача отчета только с выводом статистики выполнения. |
| SET AUTOTRACE ON | Выдача отчета с планом выполнения и статистикой. |
| SET AUTOTRACE TRACEONLY | То же, что и SET AUTOTRACE ON, но без вывода результирующих строк запроса. |
Чтобы AUTOTRACE корректно работала, необходимо выполнить ряд дополнительных действий.
1. В БД должна быть создана таблица (как правило, называемая PLAN_TABLE) для хранения плана выполнения. Для создания такой таблицы можно воспользоваться сценарием? \rdbms\admin\utlxplan.sql. Можно создавать ее в схеме пользователя SYS, а потом предоставить к ней доступ остальным пользователям (часто с созданием синонима), а можно создавать такие таблицы для каждой схемы пользователя.
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
2. Дать привилегии на полный доступ к таблице PLAN_TABLE тем пользователям, которые будут использовать AUTOTRACE. Например, для всех пользователей в БД:
create public synonym plan_table for sys.plan_table;
GRANT ALL ON PLAN_TABLE TO PUBLIC;
3. Создать роль PLUSTRACE, воспользовавшись сценарием? \sqlplus\admin\plustrce.sql.
4. Дать привилегии на использование этой роли пользователям, которые будут использовать AUTOTRACE.
GRANT PLUSTRACE TO PUBLIC;
Теперь пользователи могут получать план выполнения и статистику выполнения SQL-выражений с помощью AUTOTRACE.
Пример (в демо-схеме HR):
SET AUTOTRACE ON
SELECT E.LAST_NAME, E.SALARY, J.JOB_TITLE
FROM EMPLOYEES E, JOBS J
WHERE E.JOB_ID=J.JOB_ID AND E.SALARY> 12000;
/
The output is similar to the following:
LAST_NAME SALARY JOB_TITLE
------------------------- ---------- -----------------------------------
King 24000 President
Kochhar 17000 Administration Vice President
De Haan 17000 Administration Vice President
Russell 14000 Sales Manager
Partners 13500 Sales Manager
Hartstein 13000 Marketing Manager
6 rows selected.
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE
1 0 TABLE ACCESS (BY INDEX ROWID) OF 'EMPLOYEES'
2 1 NESTED LOOPS
3 2 TABLE ACCESS (FULL) OF 'JOBS'
4 2 INDEX (RANGE SCAN) OF 'EMP_JOB_IX' (NON-UNIQUE)
Statistics
----------------------------------------------------------
0 recursive calls
2 db block gets
34 consistent gets
0 physical reads
0 redo size
848 bytes sent via SQL*Net to client
503 bytes received via SQL*Net from client
4 SQL*Net roundtrips to/from client
0 sorts (memory)
0 sorts (disk)
6 rows processed
Помимо получения плана выполнения SQL-выражения, сервером регистрируется дополнительная информация (статистика выполнения).
| Название статистики | Описание |
| Рекурсивные вызовы (recursive calls) | Число рекурсивных вызовов, инициируемых как клиентом, так и сервером. Нарпример, внутренние операции в словаре данных. |
| Число попаданий в КД (db block gets) | Количество успешных заNumber of times a CURRENT block was requested. |
| consistent gets | Количество согласованных чтений Number of times a consistent read was requested for a block. |
| Чтение с диска (physical reads) | Общее число блоков, считанных с диска. Это число равно величине " physical reads direct" плюс все чтения в КД. |
| Размер данных повтора (redo size) | Общее число данных повтора (в байтах), сгенерированных в течение выполнения выражения. |
| Количество байт, переданных через сеть клиенту | Общее число байт, переданных клиенту фоновыми процессами. |
| Количество байт, переданных клиентом через сеть | Общее число байт, переданных клиентом через сеть. |
| Общее объем сетевых сообщений | Общее количество сообщений Oracle Net переданных клиенту и полученных от клиента. |
| Сортировки в памяти | Число сортировок, выполненных в памяти |
| Дисковые сортировки | Число сортировок, вызвавших хотя бы одно дисковое чтение. |
| Возвращено строк | Число строк, возвращенных выражением. |
Способы доступа к данным
· Full Table Scans (FTS) – полное табличное сканирование.
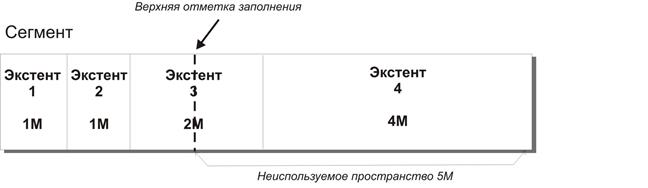
Полное сканирование таблицы подразумевает просмотр всех блоков таблицы до уровня верхней отметки заполнения. Это самый простой и всегда доступный способ доступа к таблицам. Отметка заполнения (High Water Mark) – граница между используемым и неиспользуемым пространством в сегменте. На рисунке ниже представлен сегмент, состоящий из 4-х экстентов, где первых два экстента (каждый размером в 1М) полностью заполнены. Точнее сказать, все блоки данных, составляющие эти экстенты, считаются занятыми. Часть блоков экстента 3 и экстента 4 не содержат пока блоков с полезными данными. Другими словами, эти блоки находятся выше отметки заполнения. Блоки, находящиеся выше отметки заполнения (на рисунке это блоки, находящиеся справа), не рассматриваются сервером БД при операциях доступа к данным внутри данного сегмента.
Во время выполнения полного табличного сканирования таблицы просматриваются все блоки таблицы до уровня отметки заполнения. Блоки, расположенные выше ее, не затрагиваются.
FTS используется оптимизатором в следующих случаях:
· Когда у оптимизатора нет других способов доступа к данным;
· В условии фильтрации строк используются функции, а индексов по этим функциям нет.
· Извлечение большого количества строк из больших таблиц. В этом случае часто FTS будет более эффективным, чем доступ по индексу.
· Если таблица содержит меньше блокоа, чем значение DB_FILE_MULTIBLOCK_READ_COUNT, то вся таблица может быть считана с диска за одну дисковую операцию. В этом случае FTS будет более дешевым вариантом доступа к данным.
· Если статистика оптимизатора по таблице устарела или вообще отсутствует.
· Высокое значение степени распараллеливания разбираемого SQL-выражения;
select * from regions
/
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=4 Bytes=48)
1 0 TABLE ACCESS (FULL) OF 'REGIONS' (Cost=2 Card=4 Bytes=48)
· Sample Table Scans – сканирование выборочных блоков.
В этом режиме из таблиц возвращается случайный набор строк. Этот способ доступа используется только в предложениях SELECT... FROM с фразой SAMPLE (указывается выбираем процент строк) или SAMPLE BLOCK (указывается выбираемый процент блоков). Этот способ распознается только CBO.
SELECT * FROM employees SAMPLE BLOCK (1); Execution Plan---------------------------------------------------------- 0 SELECT STATEMENT Optimizer=CHOOSE (Cost=2 Card=1 Bytes=62) 1 0 TABLE ACCESS (SAMPLE) OF 'EMPLOYEES' (Cost=2 Card=1 Bytes= 62)
· Rowid Scans – доступ по идентификатору строки (ROWID).
Каждая строка любой таблицы в БД Oracle уникально идентифицируется с помощью ROWID – псевдостолбца специального типа, содержащего уникальный адрес любой строки внутри БД. Доступ к отдельной строке по ROWID – самый быстрый среди всех видов доступа в СУБД Oracle 10g. Когда осуществляется подобная операция, то сначала определяются ROWID искомых строк (например, с помощью индексного сканирования), а затем по полученным идентификаторам строк извлекаются необходимые строки из таблиц.
· Index Scans – индексное сканирование.
Когда в SQL-выражении (например, во фразе WHERE команды SELECT) указывается условие фильтрации по некоторым столбцам, оптимизатор анализирует существующие для обрабатываемой таблицы индексы для того, чтобы, по возможности и необходимости, ускорить получение данных из таблицы.
В нижеследующем примере видно, что, при фильтрации строк во фразе WHERE по столбцу EMAIL, в плане выполнения было выбрано индексное сканирование по индексу EMP_EMAIL_UK. Наличие индекса по запрашиваемому полю позволило ускорить процесс доступа к строкам таблицы. Но, если бы индекс по столбцу EMAIL не существовал, было бы выбрано полное табличное сканирование.
select email from employees
where email > 'T'
/
Execution Plan
----------------------------------------------------------
0 SELECT STATEMENT Optimizer=CHOOSE (Cost=1 Card=16 Bytes=112)
1 0 INDEX (RANGE SCAN) OF 'EMP_EMAIL_UK' (UNIQUE) (Cost=1 Card
=16 Bytes=112)
Поэтому важно знать, какие индексы существуют для таблиц, и строить их в зависимости от того, какие срезы доступа к данным действительно необходимы.
При индексном сканировании Oracle сканирует индекс по столбцам, указанным в SQL-выражении. Если происходит обращение только с столбцам, которые присутствуют в некотором индексе, то данные столбца берутся напрямую из индекса, не обращаясь к таблице.
Строка индекса, помимо значения для поиска, содержит еще и ROWID строки таблицы, которой она соответствует. Когда в SQL-выражении затрагиваются и не индексные столбцы, то сканирование по индексу возвращает список ROWID нужных строк, и далее выполняется дополнительное сканирование в таблице.
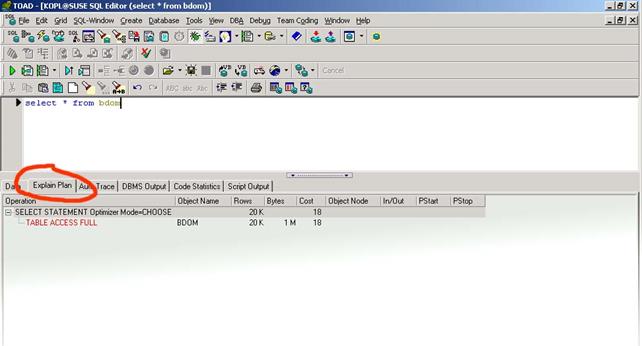
Получение плана выполнения при помощи утилиты TOAD
Утилита TOAD использует свою собственную таблицу для хранения плана выполнения SQL-выражения. В остальном используется тот же приницип формирования плана выполнения.
Для того, чтобы настроить получение плана выполнения SQL-выражений в TOAD, необходимо запустить Tools-> Server Side Object Wizard.

Если в вашей БД не существует схемы пользователя TOAD, мастер предложит ее создать с правами привилегированного пользователя (DBA). Это необходимо для включения возможности получения плана выполнения.

Далее необходимо указать объекты схемы TOAD, которые вы хотите установить. В данном случае на интересуют Explain Plan Tables. Выбираем соответствующий пункт.

Далее необходимо указать привилегии, предоставляемые пользователю TOAD (если он создается), а также пароль и табличные пространства по умолчанию и для временных операций.
Также нужно указать табличные пространства для хранения таблиц и индексов, используемых TOAD для получения плана выполнения.

После этого осталось только выполнить сценарий, либо сохранить его на диске.
После того, как сценарий успешно отработает, в окне SQL-редактора станет доступной закладка Explain Plan, в которой и содержится план выполнения текущего SQL-выражения.
|
|