Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

Сжатое и индексное хранение линейных списков
|
|
При хранении больших объемов информации в форме линейных списков нежелательно хранить элементы с одинаковым значением, поэтому используют различные методы сжатия списков.
Сжатое хранение. Пусть в списке B= несколько элементов имеют одинаковое значение V, а список B'= получается из B заменой каждого элемента Ki на пару Ki'=(i, Ki). Пусть далее B" = - подсписок B', получающийся вычеркиванием всех пар Ki=(i, V). Сжатым хранением В является метод хранения В", в котором элементы со значением V умалчиваются. Различают последовательное сжатое хранение и связанное сжатое хранение. Например, для списка B=, содержащего несколько узлов со значением Х, последовательное сжатое и связанное сжатое хранения, с умалчиванием элементов со значением Х, представлены на рис.9, 10.
| 1, C | 3, Y | 6, S | 7, H | 9, T |
| Рис.9. Последовательное сжатое хранение списка. |
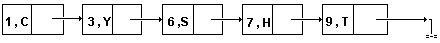
Рис.10. Связное сжатое хранение списка.
Достоинство сжатого хранения списка при большом числе элементов со значением V заключается в возможности уменьшения объема памяти для его хранения.
Поиск i-го элемента в связанном сжатом хранении осуществляется методом полного просмотра, при последовательном хранении - методом бинарного поиска.
Преимущества и недостатки последовательного сжатого и связанного сжатого хранений аналогичны преимуществам и недостаткам последовательного и связанного хранений.
Рассмотрим следующую задачу. На входе заданы две последовательности целых чисел M=, N=, причем 92% элементов последовательности М равны нулю. Составить программу для вычисления суммы произведений Mi * Ni, i=1, 2,..., 10000.
Предположим, что список М хранится последовательно сжато в массиве структур m с объявлением:
struct { int nm; float val; } m[10000];
Для определения конца списка добавим еще один элемент с порядковым номером m[j].nm=10001, который называется стоппером (stopper) и располагается за последним элементом сжатого хранения списка в массиве m.
— Регулярная проверка качества ссылок по более чем 100 показателям и ежедневный пересчет показателей качества проекта.
— Все известные форматы ссылок: арендные ссылки, вечные ссылки, публикации (упоминания, мнения, отзывы, статьи, пресс-релизы).
— SeoHammer покажет, где рост или падение, а также запросы, на которые нужно обратить внимание.
SeoHammer еще предоставляет технологию Буст, она ускоряет продвижение в десятки раз, а первые результаты появляются уже в течение первых 7 дней. Зарегистрироваться и Начать продвижение
Программа для нахождения искомой суммы имеет вид:
Индексное хранение используется для уменьшения времени поиска нужного элемента в списке и заключается в следующем. Исходный список B = разбивается на несколько подсписков В1, В2,..., Вm таким образом, что каждый элемент списка В попадает только в один из подсписков, и дополнительно используется индексный список с М элементами, указывающими на начало списков В1, В2,..., Вm.
Считается, что список хранится индексно с помощью подсписков B1, B2,..., Bm и индексного спискa X =, где ADGj - адрес начала подсписка Bj, j=1, M.
При индексном хранении элемент К подсписка Bj имеет индекс j. Для получения индексного хранения исходный список В часто преобразуется в список В' путем включения в каждый узел еще и его порядкового номера в исходном списке В, а в j-ый элемент индексного списка Х, кроме ADGj, может включаться некоторая дополнительная информация о подсписке Bj. Разбиение списка В на подсписки осуществляется так, чтобы все элементы В, обладающие определенным свойством Рj, попадали в один подсписок Bj.
Достоинством индексного хранения является то, что для нахождения элемента К с заданным свойством Pj достаточно просмотреть только элементы подсписка Bj; его начало находится по индексному списку Х, так как для любого К, принадлежащего Bi, при i не равном j свойство Pj не выполняется.
В разбиении В часто используется индексная функция G(K), вычисляющая по элементу К его индекс j, т.е. G(K)=j. Функция G обычно зависит от позиции К, обозначаемой поз.K, в подсписке В или от значения определенной части компоненты К - ее ключа.
Рассмотрим список B= с элементами
К1=(17, Y), K2=(23, H), K3=(60, I), K4=(90, S), K5=(66, T), K6=(77, T), K7=(50, U), K8=(88, W), K9=(30, S).Если для разбиения этого списка на подсписки в качестве индексной функции взять Ga(K)=1+(поз.K-1)/3, то список разделится на три подсписка:
B1a=< (17, Y), (23, H), (60, I)>, B2a=< (90, S), (66, T), (77, T)>, B3a=< (50, U), (88, W), (30, S)>.Добавляя всюду еще и начальную позицию элемента в списке, получаем:
B1a'=< (1, 17, Y), (2, 23, H), (3, 60, I)>, B2a'=< (4, 90, S), (5, 66, T), (6, 77, T)>, B3a'=< (7, 50, U), (8, 88, W), (9, 30, S)>.Если в качестве индексной функции выбрать другую функцию Gb(K)=1+(поз.K-1)%3, то получим списки:
Теперь для нахождения узла K6 достаточно просмотреть только одну из трех последовательностей (списков). При использовании функции Ga(K) это список B2a', а при функции Gb(K) список B3b".
Для индексной функции Gc(K)=1+K1/100, где K1 - первая компонента элемента К, находим:
B1=< (17, Y), (23, H), (60, I), (90, S)>, B2=< (66, T), (77, T)>, B3=< (50, U), (88, W)>, B4=< (30, S)>.Чтобы найти здесь узел К с первым компонентом-ключом К1=77, достаточно просмотреть список B2.
При реализации индексного хранения применяется методика А для хранения индексного списка Х (функция Ga(X)) и методика C для хранения подсписков B1, B2,..., Bm (функция Gc(Bi)), т.е. используется, так называемое, A-C индексное хранение.
— Разгрузит мастера, специалиста или компанию;
— Позволит гибко управлять расписанием и загрузкой;
— Разошлет оповещения о новых услугах или акциях;
— Позволит принять оплату на карту/кошелек/счет;
— Позволит записываться на групповые и персональные посещения;
— Поможет получить от клиента отзывы о визите к вам;
— Включает в себя сервис чаевых.
Для новых пользователей первый месяц бесплатно. Зарегистрироваться в сервисе
В практике часто используется последовательно-связанное индексное хранение. Так как обычно длина списка индексов известна, то его удобно хранить последовательно, обеспечивая прямой доступ к любому элементу списка индексов. Подсписки B1, B2,..., Bm хранятся связанно, что упрощает вставку и удаление узлов(элементов). В частности, подобный метод хранения используется в ЕС ЭВМ для организации, так называемых, индексно-последовательных наборов данных, в которых доступ к отдельным записям возможен как последовательно, так и при помощи ключа.
Последовательно-связанное индексное хранение для приведенного примера изображено на рис.11, где X=.

Рис.11. Последовательно-связанное индексное хранение списка.
Рассмотрим еще одну задачу. На входе задана последовательность целых положительных чисел, заканчивающаяся нулем. Составить процедуру для ввода этой последовательности и организации ее последовательно-связанного индексного хранения таким образом, чтобы числа, совпадающие в двух последних цифрах, помещались в один подсписок.
Выберем в качестве индексной функции G(K)=K%100+1, а в качестве индексного списка Х - массив из 100 элементов. Следующая функция решает поставленную задачу:
#include #include typedef struct nd { float val; struct nd *n; } ND; int index (ND *x[100]) { ND *p; int i, j=0; float inp; for (i=0; i< 100; i++) x[i]=" NULL; " scanf(" %d", & inp); while (inp! =" 0)" { j++; p=" malloc(sizeof(ND)); " i=" inp%100+1; " p-> val=inp; p-> n=x[i]; x[i]=p; scanf(" %d", & inp); } return j; }
Возвращаемым значением функции index будет число обработанных элементов списка.
Для индексного списка также может использоваться индексное хранение. Пусть, например, имеется список B= с элементами
K1=(338, Z), K2=(145, A), K3=(136, H), K4=(214, I), K5 =(146, C), K6=(334, Y), K7=(333, P), K8=(127, G), K9=(310, O), K10=(322, X).Требуется разделить его на семь подсписков, т.е. X= таким образом, чтобы в каждый список B1, B2,..., B7 попадали элементы, совпадающие в первой компоненте первыми двумя цифрами. Список Х, в свою очередь, будем индексировать списком индексов Y=, чтобы в каждый список Y1, Y2, Y3 попадали элементы из X, у которых в первой компоненте совпадают первые цифры. Если списки B1, B2,..., B7 хранить связанно, а списки индексов X, Y индексно, то такой способ хранения списка B называется связанно-связанным связанным индексным хранением. Графическое изображение этого хранения приведено на рис.12.
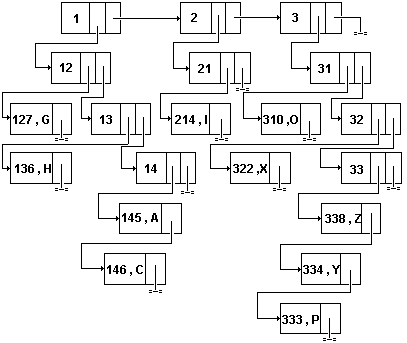
Рис.12. Связанно-связанное связанное индексное хранение списка.
|
|