Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника

⚡️ Для новых пользователей первый месяц бесплатно. А далее 290 руб/мес, это в 3 раза дешевле аналогов. За эту цену доступен весь функционал: напоминание о визитах, чаевые, предоплаты, общение с клиентами, переносы записей и так далее.
✅ Уйма гибких настроек, которые помогут вам зарабатывать больше и забыть про чувство «что-то мне нужно было сделать».
Сомневаетесь? нажмите на текст, запустите чат-бота и убедитесь во всем сами!
Технология IA-64
|
|
Дальнейшим развитием идеи VLIW стала новая архитектура IA-64 — совместная разработка фирм Intel и Hewlett-Packard (IA - это аббревиатура от Intel Architecture). В IA-64 реализован новый подход, известный как вычисления с явным параллелизмом команд (EPIC, Explicitly Parallel Instruction Computing) и являющийся усовершенствованным вариантом технологии VLIW. Первым представителем данной стратегии стал микропроцессор Itanium компании Intel. Корпорация Hewlett-Packard также реализует данный подход в своих разработках.
Разработчики процессоров стремятся создавать чипы, содержащие как можно больше функциональных узлов - что позволяет обрабатывать больше команд параллельно - но одновременно приходится существенно усложнять управляющие цепи для распределения потока команд по обрабатывающим узлам. На данный момент лучшие процессоры не могут выполнять более четырёх команд одновременно, при этом управляющая логика занимает слишком много места на кристалле.
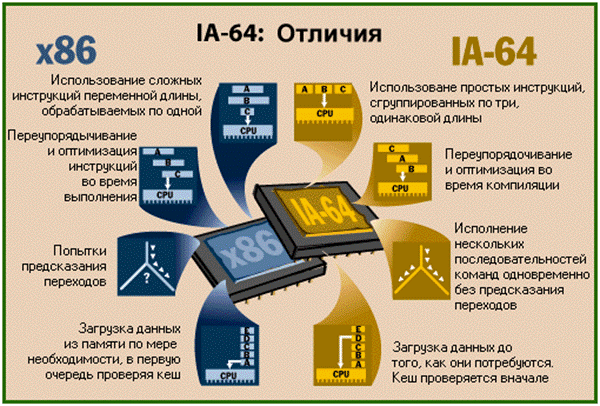
Отличия архитектуры IA-64 от x86
В то же время, последовательная структура кода программ и большая частота ветвлений делают задачу распределения потока команд крайне сложной. Современные процессоры содержат огромное количество управляющих элементов для того, чтобы минимизировать потери производительности, связанные с ветвлениями, и извлечь как можно больше " скрытого параллелизма" из кода программ. Они изменяют порядок команд во время исполнения программы, пытаются предсказать, куда необходимо будет перейти в результате очередного ветвления, и выполняют команды до вычисления условий ветвления. Если путь ветвления предсказан неверно, процессор должен сбросить полученные результаты, очистить конвейеры и загрузить нужные команды, что требует достаточно большого числа тактов. Таким образом, процессор, теоретически выполняющий четыре команды за такт, на деле выполняет менее двух.
Проблему ещё осложняет тот факт, что микросхемы памяти не успевают за тактовой частотой процессоров. Когда Intel разработала архитектуру х86, процессор мог извлекать данные из памяти с такой же скоростью, с какой он их обрабатывал. Сегодня процессор тратит сотни тактов на ожидание загрузки данных из памяти, даже несмотря на наличие большой и быстрой кэш-памяти.
Команды в формате IA-64 упакованы по три в 128-битный пакет для быстрейшей обработки. Обычно это называют " LIW encoding". (Русский аналог подобрать сложно. Наиболее адекватно, на мой взгляд, перевести как " кодирование в длинные слова команд".) Однако компания Intel избегает такого названия, заявляя, что с ним связаны " негативные ассоциации" (negative connotation). По той же причине Intel не любит называть сами команды RISC-подобными (RISC-like), даже несмотря на то, что они имеют фиксированную длину и предположительно оптимизированы для исполнения за один такт в ядре, не нуждающемся в микрокоде. Intel предпочитает называть свою новую LIW-технологию Explicitly Parallel Instruction Computing или EPIC (Вычисления с Явной Параллельностью Инструкций, где " явной" означае явно указанной при трансляции). В любом случае формат команд IA-64 не имеет ничего общего с х86. Команды х86 могут иметь длину от 8 до 108 бит, и процессор должен последовательно декодировать каждую команду после определения её границ.
- Каждый 128-битный пакет содержит шаблон (template) длиной в несколько бит, помещаемый в него компилятором, который указывает процессору, какие из команд могут выполняться параллельно. Теперь процессору не нужно будет анализировать поток команд в процессе выполнения для выявления " скрытого параллелизма". Вместо этого наличие параллелизма определяет компилятор и помещает информацию в код программы. Каждая команда (как для целочисленных вычислений, так и для вычислений с плавающей точкой) содержит три 7-битных поля регистра общего назначения (РОН). Из этого следует, что процессоры архитектуры IA-64 содержат 128 целочисленных РОН и 128 регистров для вычислений с плавающей точкой. Все они доступны программисту и являются регистрами с произвольным доступом (programmer-visible random-access registers). По сравнению с процессорами х86, у которых всего восемь целочисленных РОН и стек глубины 8 для вычислений с плавающей точкой, IA-64 намного " шире" и, соответственно, будет намного реже простаивать из-за " нехватки регистров".
- Компиляторы для IA-64 будут использовать технологию " отмеченных команд" (predication) для устранения потерь производительности из-за неправильно предсказанных переходов и необходимости пропуска участков кода после ветвлений. Когда процессор встречает " отмеченное" ветвление в процессе выполнения программы, он начинает одновременно выполнять все ветви. После того, как будет определена " истинная" ветвь, процессор сохраняет необходимые результаты и сбрасывает остальные.
- Компиляторы для IA-64 будут также просматривать исходный код с целью поиска команд, использующих данные из памяти. Найдя такую команду, они будут добавлять пару команд - команду предварительной загрузки (speculative loading) и проверки загрузки (speculative check). Во время выполнения программы первая из команд загружает данные в память до того, как они понадобятся программе. Вторая команда проверяет, успешно ли произошла загрузка, перед тем, как разрешить программе использовать эти данные. Предварительная загрузка позволяет уменьшить потери производительности из-за задержек при доступе к памяти, а также повысить параллелизм.
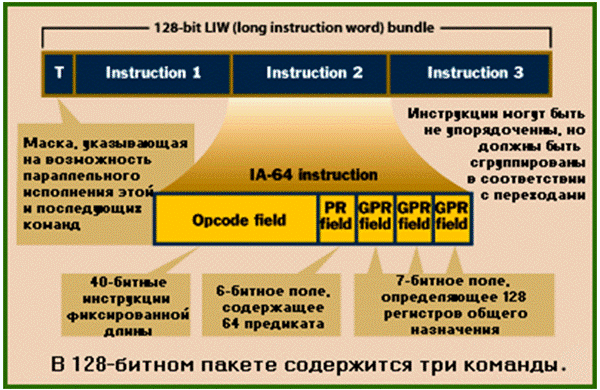
Формат инструкций IA-64
Поле каждой из трех команд в связке, в свою очередь, состоит из пяти полей:
- 13-разрядного поля кода операции;
- 6-разрядного поля предикатов, хранящего номер одного из 64 регистров предиката;
- 7-разрядного поля первого операнда (первого источника), где указывается номер регистра общего назначения или регистра с плавающей запятой, в котором содержится первый операнд;
- 7-разрядного поля второго операнда (второго источника), где указывается номер регистра общего назначения или регистра с плавающей запятой, в котором содержится второй операнд;
- 7-разрядного поля результата (приемника), где указывается номер регистра общего назначения или регистра с плавающей запятой, куда должен быть занесен результат выполнения команды.
Следует пояснить роль подполя предикатов. Предикация - это способ обработки условных ветвлений. Суть в том, что еще компилятор указывает, что обе ветви выполняются на процессоре параллельно, ведь EPIC-процессоры должны иметь много функциональных блоков.
Если в исходной программе встречается условное ветвление (по статистике — через каждые шесть команд), то команды из разных ветвей помечаются разными регистрами предиката (команды имеют для этого соответствующие поля), далее они выполняются совместно, но их результаты не записываются, пока значения регистров предиката (РП) не определены. Когда, наконец, вычисляется условие ветвления, РП, соответствующий «правильной» ветви, устанавливается в 1, а другой - в 0. Перед записью результатов процессор проверяет поле предиката и записывает результаты только тех команд, поле предиката которых указывает на РП с единичным значением.
Предикаты формируются как результат сравнения значений, хранящихся в двух регистрах. Результат сравнения («Истина» или «Ложь») заносится в один из РП, но одновременно с этим во второй РП записывается инверсное значение полученного результата. Такой механизм позволяет процессору более эффективно выполнять конструкции типа I F - T H E N-E L S E.
Логика выдачи команд на исполнение сложнее, чем в традиционных процессорах типа VLIW, но намного проще, чем у суперскалярных процессоров с неупорядоченной выдачей.
|
|