Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
АЛП - інструкція типу регістр - безпосередній операнд
|
|
МІНІСТЕРСТВО ОСВІТИ І НАУКИ УКРАЇНИ
НАЦІОНАЛЬНИЙ УНІВЕРСИТЕТ " ЛЬВІВСЬКА ПОЛІТЕХНІКА"
КАФЕДРА ЕЛЕКТРОННИХ ОБЧИСЛЮВАЛЬНИХ МАШИН
Мельник А.О., Кицун Г.В., Сало А.М., Троценко В.В.
КУРСОВА РОБОТА НА ТЕМУ
ПРОЕКТУВАННЯ RISC-КОМП'ЮТЕРА
Курс – “Архітектура комп’ютерів”
Методичні вказівки і завдання на проектування
Львів - 2009
ЗМІСТ
Вступ
Система машинних інструкцій
Приклад для розрахунку формату адреси для кеш-пам’яті
Приклад розрахунку розрядності шини адрес для взаємодії з основною пам’яттю
Вихідні дані на проектування
Вимоги щодо оформлення матеріалів проекту
Література
Вступ
Вступ містить архітектурний опис комп’ютера, архітектурна ефективність якого досліджується.
Мета курсового проектування полягає в опануванні студентом знань про принципи дії та архітектуру прототипних варіантів сучасних RISC-комп'ютерів. В порівнянні з класичною CISC (complex instruction set computer) архітектурою більш швидка RISC (reduced instruction set computer ) архітектура має наступне:
1. Одноциклові операції (кожну інструкцію еквівалентно виконують за один тактовий інтервал, цикл).
2. Архітектурний дизайн системи інструкцій має назву load/storе, де інструкції звернення до комірок пам’яті розвантажені від виконання операцій (арифметичних, логічних, зсувних тощо).
3. Скорочену систему інструкцій і адресувальних режимів, що спрощує апаратуру керування.
4. Фіксований формат інструкцій і майже фіксований поділ цього формату на окремі поля.
5. Зменшення пригальмувань конвеєра інструкцій через застосування оптимізуючих компіляторів, що раціонально диспетчеризують виконуваний машинний код.
Формати RISC інструкцій DLX процесора подано рисунком 1.

Рис. 1 - Формати інструкцій RISC-DLX процесора [Hennessy & Patterson, 2003]
Пояснення щодо форматів інструкцій.
I - тип інструкції опрац, що використовує безпосередній операнд (Immediate).
R - тип інструкції; така інструкція отримує пару операндів із джерельних регістрів (Registers) регістрового файлу процесора і повертає результат знов таки до регістру призначення з цього файлу.
J – тип є інструкцією безумовного переходу (jump).
OpCode є полем коду операції, який залежить від кількості виконуваних процесором команд. Розрядність даного поля=Log2N, де N – множина виконуваних процесором команд. В даному випадку довжина поля складає 6 розрядів.
Rs1, rs2 є полями, що задають номери регістрів-джерел операндів (register of source), що належать множині регістрів регістрового файла. Розрядність кожного з цих полів визначається, як Log2N, де N – множина регістрів регістрового файлу. В даному випадку кожне поле має довжину 5 бітів, а множина регістрів від R0доR31.
rd є полем номера регістра призначення (приймача результату дії, register of destination). Розрядність поля визначається, як Log2N, де N – множина регістрів регістрового файлу. Регістр призначення також обирають з множини регістрів регістрового файлу. В даному випадку поле є п'ятибітовим.
Immediate - це 16-ти бітове поле, що містить безпосередній операнд; при цьому найлівіший розряд immediate розглядають як знаковий; при використанні безпосередній операнд попередньо знаково розширюють вліво (як доповняльний код) до 32-х бітів.
Function - це поле, що визначає функцію, що розширює на 211 – 1 = 2047 комбінацій обмежене число дозволених кодів операції.
Offset added to PC - це 26-ти бітова константа, яку додають до вмістимого регістру наступної адреси аби знайти цільову адресу безумовного переходу.
Особливості поданих форматів інструкцій:
1. Довжина всіх форматів – 32 біти.
2. Реалізовано дизайн архітектури load/store.
3. Реалізовано фіксовану систему поділу форматів на поля.
4. Всі інструкції з погляду їхньої обробки поділено на три групи:
- АЛП операції,
- операції load/store,
- операції керування виконанням програми.
Отже, формати АЛП-операцій є триадресувальними, тобто, завжди подаються як OP RX, RY, RZ.
Основою побудови структури інформаційного тракту (data path) є часова діаграма виконання інструкції з найбільшою складністю. До такої інструкції в нашому класичному RISC комп’ютері належить, наприклад, інструкція завантаження слова з комірки пам’яті до регістра. Тому розглянемо виконання інструкції завантаження слова LW R5, 16(R26) для багатоцикловоїї RISC машини(такий варіант побудови RISC машини є наочнішим в передбаченні подальшого переходу до конвеєрного варіанту). Задля виконання інструкції завантаження потрібно:
- вибрати нструкцію з пам’яті (на це витрачаємо перший цикл виконання з назвою IF),
- декодувати інструкцію і (паралельно, тобто, незалежно) вибрати операнди (на це витрачаємо другий цикл виконання з назвою ID),
- виконати інструкцію, тобто, в нашому випадку розрахувати виконавчу адресу операнда 16 + < R26> (на це витрачаємо третій цикл виконання з назвою EX),
- вибрати операнд із головної пам’яті (витрачаємо четвертий цикл виконання з назвою MEM),
- переслати вибраний з пам’яті операнд до регістра R5 регістрового файла (витрачаємо п’ятий цикл виконання з назвою WB).
Зауважимо, що (апаратним) циклом ми називаємо один тактовий інтервал. Отже, виконання інструкції, що розглядається, вимагає витрати п’яти циклів. Іншим інструкцїям можуть не знадобитися всі щойно перелічені цикли виконання через їхню меншу часову складність, Проте менш складним інструкціям теж віддають на виконанання п’ять циклів, деякі з яких є робочими, а деякі - порожніми. Ясно, що при рівній довжині кожного машинного циклу ми нехтуємо наявним ефектом парадоксу пам’яті. Адже, наприклад, довжини циклів маніпулювання комірками МЕМ і маніпулювання регістрами ID/OF в нас є рівними.
Наступним рисунком подано черговість слідування апаратних циклів (інколи кажуть - фаз, сходинок) при виконанні RISC інструкції. Зауважимо ще раз, що не всі інструкції вимагають виконання усіх фаз. Наприклад, інструкції переходів використовують як роочі лише перши три цикли, а два останні цикли – як порожні. При конвеєрному виконанні інструкції переходу два останні цикли також витрачають як порожні, аби вирівняти час виконання всіх, як складних, так і спрощених інструкцій. При цьому на перших трьох апаратних циклах перехід є переходом, а на два останні він долає вже як інструкція nop.

Рис. 2 – Організація апаратних засобів інформаційного тракту RISCмашини
Тут:
IF – апаратні засоби вибирання з інструкційної пам’яті ІМ чергової інструкції,
ID – апаратні засоби декодування інструкції і паралельного з цим вибирання операндів,
EX – апаратні засоби виконання інструкції,
MEM – апаратура запису/читання пам’яті даних МЕМ,
WB – зворотній запис до регістрового файла (як мети) результату виконання інструкції.
Рисунком 2 подано ще ідеалізовану структуру апаратних засобів, що функціонують на фазі виконання ЕХ, а саме, поокремо показано вузли виконання дій над цілими і над рухомими кодами. Структуру багатоциклового (максимально наближеного до конвеєрного варіанту) прототипу машини подано рисунком 3.

Рис. 3 - Багатоцикловий прототип RISC машини [Hennessy & Patterson, 2003]
Скороченням PC позначено лічильник інструкцій (Program Counter). Вмістиме РС визначає адресу інструкції в пам'яті інструкцій ІМ. Комбінаційний додавач Adder обраховує адресу наступної за чергою виконання інструкції. При цьому враховано, що впорядкована послідовність інструкцій (програма) складається виключно з чотирибайтових інструкцій (усі інструкції мають формати з довжиною 32 біти), які розміщено в IM за адресами 0, 4, 8, C ,... тощо. Через це константа зсуву адреси (пересування покажчика на наступну за чергою інструкцію) дорівнює +4. Визначене за допомогою додавача значення адреси наступної інструкції зберігають у регістрі NPC (next PC). Зчитаний з ІМ бінарний код поточної інструкції записують до регістру інструкції IR, розрядність якого така ж як і розрядність інструкції. Якщо шина даних для взаємодії між процесором та основною пам’яттю складає 32 розряди, то, за 1 процесорний такт буде зчитано 1 інструкцію. Поля щойно вибраної інструкції, що містять бінарні коди, ідентифікатори регістрів операндів, є фактично адресами комірок внутрішньо процесорної пам'яті, що емулює пул (множину) програмно керованих (видимих програмісту) регістрів. Вмістиме зазначених полів формату інструкції надсилають до адресувальних входів регістрового файлу Registers чи Regs, а відповідні надісланим адресам бінарні коди регістрових операндів завантажують до внутрішніх, програмно недосяжних службових регістрів А і В.
Існує ще один тип операнда з назвою “безпосередній” (Immediate чи Imm). Його задають прямо в інструкції. Як правило, довжина безпосереднього операнда не перевищує половини довжини формату інструкції. В нас безпосередній операнд має довжину 32/2 = 16 бітів. В той самий час бажано зафіксувати таку довжину формату даних, що дорівнює довжині формату інструкції (зауважимо без пояснень, що збільшення числа різних довжин форматів суттєво пригальмовує машину). Отже, в нас всі формати даних, всі формати інструкцій мають довжину 32 біти. Зараз ясно, що безпосередньому операнду не вистачає ще 16 бітів, аби використовуватися. Тому знакове розширення 16 бітового безпосереднього операнда до 32-х бітів виконує комбінаційний вузол Sign Extend. Результат знакового розширення тимчасово зберігають у службовому регістрі Imm. Отже, можна нарахувати чотири можливі операнди на вході АЛП:
- з регістрів А, В, Imm;
- вмістиме регістру адреси наступної для виконання інструкції NPC.
Зазначимо, що операнд-адресу NPC опрацьовують в АЛП при виконанні інструкцій умовного переходу, коли на додаток до наступної потрібна ще одна адреса, яку утворюють додаванням до вмістимого NPC певної константи переходу.
Вибирання двох операндів АЛП (з чотирьох можливих) виконують за допомогою мультиплексорів операндів mux. Результат операції АЛП тимчасово запам'ятовують у проміжному службовому регістрі ALUoutput (ALUout). Коли результатом операції є число, тоді його заносять до комірки регістрового файлу. Коли результатом операції є адреса, тоді цю адресу надсилають до (верхнього на рисунку) мультиплексора вибору адреси mux. За допомогою зазначеного мультиплексора вибирають адресу переходу (наступна або цільова адреса перехіду), яку і надсилають до лічильника інструкцій PC, аби коректно продовжити виконання програми.
Керування мультиплексором вибору адреси наступної інструкції покладено на вузол Zero?, де вмістиме службового регістра А порівнюють із нулем (дорівнює нулю, більше нуля, менше нуля тощо, в залежності від виду виконуваної операції порівняння). Результат порівняння є бінарним логічним значенням (так або ні). Саме цей бінарний результат керує роботою мультиплексора вибирання адреси наступної інструкції.
Результат з виходу АЛП надсилають до пам’яті даних як обчислену в АЛП адресу певної комірки цієї пам’яті (чого вимагають інструкції обміну регістрів з пам’яттю).
Результатом на виході (правий на рисунку) мультиплексора може бути або вмістиме пам’яті даних (під час виконання інструкції завантаження LW слова з комірки пам’яті даних до регістру регістрового файла), або результат виконання арифметичної, зсувної, логічної, іншої операції в АЛП (наприклад, під час виконання інструкцій ADD, SUB тощо). У подальшому цей результат зберігають в регістрі регістрового файла. Отже, зазначений мультиплексор, керований регістром поточної інструкції, комутує на вхід регістрового файла потрібну інформацію.
В циклі (Instruction Fetch cycle - IF) виконують наступні мікродії (мікрооперації):
IR = IM [PC];
NPC = PC+4.
Виконання першої мікродії спричинює завантаження до 32-х бітового регістру поточної інструкції IR, тобто, вмістимого чотирьох послідовно розташованих байтів, починаючи від адреси (PC) + 0 і завершуючи адресою (PC) + 3. Як і завжди, через (PC) позначено вмістиме лічильника інструкцій PC.
Друга мікродія (NPC = PC + 4) обчислює “планову” адресу наступної за чергою інструкції з їхнього послідовного потоку. Тобто в цьому циклі визначають наступне за чергою вмістиме програмного лічильника (його тимчасово зберігають у регістрі Next PC або NPC). “Логічне” вибирання вмістимого чотирьох послідовно розташованих байтових комірок замість однієї 4-х байтової підкреслює те, що навіть на рівні мікродій адресування комірок пам'яті виконують побайтно. Фізично, за умови коли адреса байта кратна чотирьом, тобто дотримано вирівнювання границь адрес інструкцій, з фізичної пам'яті, одразу (за одне звернення) вибирають чотири байти. Отриманий з пам’яті даних код тлумачать як 32-х розрядне слово, а з пам’яті інструкцій – як одну інструкцію.
Зауважимо, що обидві наведені мікродії теоретично є сумісними в часі. Саме тому вони можуть і повинні виконуватися паралельно. Ці мікродії утворюють єдину мікроінструкцію; в нашому випадку (але не завжди!) послідовність запису мікродій у мікроінструкції значення не має.
Надзвичайно важливою властивістю циклу IF є те, що він не бере до уваги існування відомого " парадоксу пам'яті". Дійсно, у циклі IF за часовими витратами мікродія вибирання з повільних комірок пам'яті інструкцій є тотожною мікродії, що працює з внутрішніми, а саме тому надшвидкими регістрами процесора.
В циклі ID (Instruction decode/register fetch cycle - ID) виконують наступні мікродії (мікрооперації):
A = Regs [IR 6..10 ];
B = Regs [IR 11..15];
Imm = ((IR16)16 ## IR 16..31).
У наведеному мікрокоді, що складений з трьох сумісних у часі, тобто спроможних до незалежного, паралельного виконання мікродій, вжито наступні позначення:
1. A, B, Imm - внутрішні службові 32-х бітні регістри проміжного збереження кодів можливих операндів; всі три регістри є " прозорими" для програміста в тому сенсі, що вони аж ніяк не відбиті машинними інструкціями.
2. Regs[address] - комірка внутрішньої пам'яті процесора із вже відомою назвою назвою регістровий файл;
3. R x..y - бітове поле регістра інструкцій, яке містить групу послідовно розташованих бітів - від біту з номером X до біту з номером Y включно; звернемо увагу на нумерацію бітів у слові процесора - лівий біт має 0-й номер, а правий - 31-й номер.
4. ІR6..10 - бітове поле регістру інструкцій, що містить бінарний номер регістру операнда (див. формат інструкцій); довжина поля є 5 бітів, це дозволяє позначати та реалізувати 32 регістра - від R0 до R31.
5. IR11..15 - також п'ятибітове поле номера ще одного регістра операнда (джерела) з множини R0,..., R31.
Вже зауважувалося, що поле безпосереднього операнду (Immediate чи Imm) у форматі інструкції має довжину лише 16 бітів. В цей самий час, розрядність інформаційного тракту і усіх трьох службових регістрів є 32. Аби записати 16-бітовий код IR16..31 безпосереднього операнда з регістру інструкцій до службового регістру Imm, цей код треба розширити з врахуванням знаку (або розряду IR16) до 32-х бітового значення за наступним стандартним алгоритмом знакового розширення:
IR16 ## IR16 ##...## IR16 # IR16..31.
Тут символом ## позначено операцію зчеплення (конкатенацію).
Важливо, що в циклі ID виконують декодування (розпізнавання) інструкції та вибирання усіх можливих варіантів операндів поточної інструкції, незалежно від її типу, з метою збільшення швидкодії. З іншого боку, можливість одночасного вибирання усіх варіантів операндів потенційно обумовлено відповідною структурою форматів інструкцій, де фіксовано розташування полів-покажчиків на регістри джерела операндів і регістр приймач результату. Іншими словами, формати інструкцій процесора втілюють техніку кодування форматів інструкцій, що відома під назвою fixed-field coding.
Мікродії, що виконують в циклі EX (Execution / effective address cycle), вже залежать від від типу поточної інструкції. Враховуючи це, вигідно поділити усі інструкції процесора на наступні три групи або типи:
· операції арифметичного і логічного пристрою;
· операції завантаження операндів з головної пам'яті та збереження результатів у головній пам'яті;
· операції умовних і безумовних переходів.
Далі розглядаємо притамані кожному типу інструкцій мікродії.
Операції звернення до пам'яті даних (load / store)
У циклі EX вказані операції обчислюють числове значення ефективної адреси, тобто вираховують значення бінарного коду, що безпосередньо визначає адресу комірки пам'яті даних. Отже, виконують наступну мікродію:
ALUoutput = A + Imm.
Позначене в мікродії додавання безпосереднього операнда (однієї з компонент адреси) з вмістимим робочого регістра А (другої компоненти) реалізують в АЛП (ALU). Отриману суму (її завжди сприймають як натуральний бінарний код, а переносом нехтують) записують до ще одного, прозорого для програміста регістру ALUoutput. Цей регістр має розрядність 32 біти. Він зберігає коди результатів, що з'являються на виході комбінаційної схеми з назвою ALU. Якщо пригадати дію інструкції LW, тоді призначення та форма запису наведеної мікродії стає ясною.
АЛП-інструкція типу регістр-регістр (наприклад, ADD R1, R2, R3)
Виконується відповідна інструкції наступна мікродія:
ALUoutput = A op B.
Тут узагальнене позначення (op) можна конкретизувати як (add), (sub) тощо в залежності від конкретного виду поточної інструкції, яку опрацьовують в інформаційному тракті машини. Підкреслимо, що на попередньому щодо EX циклі, а саме на циклі ID, до службових регістрів вже завантажено вмістиме вибраних комірок пам'яті " регістровий файл" з адресами R2 і R3. Результат дії поки що не збережено в R1, але його тимчасово розміщують у службовому регістрі ALUoutput.
АЛП - інструкція типу регістр - безпосередній операнд
(наприклад, ADD R1, R2, #23)
Виконується наступна мікродія:
ALUoutput = A op Imm.
Ясно, що замість вмістимого R3 в операції приймає участь безпосередній операнд число 23), який з врахуванням " знакового" розширення до 32-х бітів забирають із службового регістру Imm.
Умовний перехід (наприклад, BNEZ R5, data)
Виконуються наступні мікродії:
ALUoutput = NPC + Imm;
Cond (ition) = (A op 0).
Обидві мікродії є сумісними в часі. За допомогою першої мікродії вираховують цільову адресу умовного переходу. При цьому до вже визначеної адреси наступної інструкції (NPC), тобто такої, яка розташована безпосередньо за поточною інструкцією умовного переходу, додають знакову константу зі службового регістру Imm, (саме він містить значення data). Друга мікродія визначає (істинне або хибне) значення умови Condition умовного переходу. Заради цього вмістиме службового регістру A, що є збіжним із вмістимим R5 (у прикладі інструкції), порівнюють на основі операції (op) з нулем. Згідно семантики інструкції BNEZ отримуємо, що Cond = true, коли вмістиме R5 ненульове, або Cond = false, якщо R5 містить нуль. Фізично Cond являє собою однобітовий регістр у складі вузла Zero?.
Важливо, що обчислюється значення двох необхідних елементів виконання умовного переходу, а саме, однобітова умова Cond та цільова адреса переходу, яку тимчасово зберігають у службовому вихідному регістрі АЛП ALUoutput. Безпосереднє виконання умовного переходу, що полягає в природній (за чергою) чи неприродній (коли виконують стрибок до цільової адреси) зміні вмістимого PC, виконують наступним циклом.
В циклі (memory access/branch completion cycle - MEM) виконують наступну мікродію:
LMD = DM [ALUoutput];
або
DM [ALUoutput] = B.
Звернення до пам'яті застосовують в інструкціях завантаження (наприклад, LW R6, 112(R3)) і в інструкціях збереження (наприклад, SW 112(R3), R6).
Першу мікродію виконують тільки у випадку інструкції Load (завантаження). Тут за допомогою попередньо розрахованої ефективної адреси пам'яті даних, яку тимчасово зберігають у службовому регістрі ALUoutput, здійснюють доступ до пам'яті, що і позначено записом DM[ALUoutput].
Фізично з пам'яті завжди зчитують 32 біти (або навіть цілі пакети з 32-х бітових структурних одиниць). Отриманий з пам’яті даних бінарний код тимчасово завантажують до ще одного службового регістру LMD (Load Memory Data). І тільки наступного циклу WB, що поки що не розглядався, пересилають зчитаний код з регістру LMD до конкретної комірки (в нашому прикладі - це комірка з адресою R6) регістрового файла.
Другу мікродію реалізують лише в інструкції Store (збереження). Тут до комірки пам'яті даних за адресою, що зберігають в службовому регістрі ALUoutput = (R3) + 112, засилають вмістиме службового регістру B. При цьому (у наведеному прикладі) для інструкції SW має місце тотожність (В)=(R6).
Увага! Цикл змінює програмний стан комп’ютера. Після його виконання поновлення попереднього програмного стану унеможливлено!
Умовний перехід (branch)
Виконують наступну умовну мікродію:
if (condition) PC = ALUoutput else PC = NPC.
Здійснюють природну (cond=0) або неприродну (cond =1) заміну вмістимого PC з метою реалізації наступної за branch інструкції.
Увага! Тут змінюють програмний стан комп’ютера. Після його виконання поновлення попереднього програмного стану унеможливлено!
На останньому циклі (write-back cycle - WB) виконання інструкції у разі потреби результат, що отримано на попередніх фазах записують до певної комірки RX регістрового файла. Наприклад, до R1, якщо поточною є інструкція ADD R1, R2, R3, або до R6 для інструкції LW R6, #112(R3).
Увага! Тут змінюють програмний стан комп’ютера. Після його виконання поновлення попереднього програмного стану унеможливлено!
АЛП-операція “регістр – регістр”
Виконують наступну мікродію:
Regs[IR16..20] = ALUoutput.
Мікродія зберігає результат ALU-операції в регістрі призначення (наприклад, в регістрі R1 на прикладі інструкції ADD). Зрозуміло, що біти 16..20 з формату поточно виконуваної інструкції містять бінарний номер регістру призначення.
AЛП-операція “регістр - безпосередній операнд”
Виконують наступну мікродію:
Regs[IR11..15 ] = ALUoutput.
Ця мікродія також зберігає результат операції, наприклад, SUB R5, R4, #1002, в комірці R5 регістрового файла.
Інструкція завантаження (наприклад, LW R6, 112(R3))
Виконують наступну мікродію:
Regs[IR 11..15 ] = LMD.
Наведена мікроінструкція надсилає до комірки R6 регістрового файла вмістиме комірки пам'яті даних за адресою 112 + (R3), яке на попередніх циклах вже було вибране з пам'яті і тимчасово утримувалося в службовому регістрі LMD.
Цим опис мікродій керування роботою RISC машини завершено.
Далі розглянемо конвеєризований варіант машини.
Конвеєрний інформаційний тракт DLX (рис. 4) складено з наступних сходинками конвеєра: IF, ID, EХ, MEM, WB. Апаратура кожної сходинки реалізує притамані їй мікрооперації. Наприклад, на першій сходинці виконують вибирання інструкції з пам’яті інструкцій IM за вмістимим програмного лічильника PC, інкремент на +4 (аби врахувати логічно байтове адресування пам’яті інструкцій) поточної адреси за допомогою комбінаційного додавача ADD та занесення отриманої наступної адреси до поля NPC (Next PC) конвеєрного регістра IF/ID. Мультиплексор Mux, що керується відповідним однобітовим полем умови переходу конвеєрного регістра EX/MEM, визначає джерело запису до NPC – або наступна за чергою адреса, або цільова адреса умовного (безумовного) переходу. Важливо, що обов’язок змінювати природне адресування послідовності вибирання інструкцій з пам’яті інструкцій покладено на контекст інструкції, яка пройшла цикл конвеєра MEM.
Конвеєрні регістри виконують функцію збереження контекстів інструкцій, а саме вмістимого інтегрованих до них регістру інструкції IR, робочих регістрів А, В тощо. Конвеєрні регістри розташовано поміж сходинками. Регістри мають назви, відповідні граничним сходинкам, наприклад IF/ID. Тоді поле A конвеєрного регістра позначають як EX/MEM.A.
До апаратури другої сходинки ID належать регістровий файл Regs, що містить множину програмно керованих регістрів та знаковий розширювач Signum Extender. Останній конвертує 16-бітові безпосередні знакові константи на 32-х бітові стандартні операнди формату з фіксованою комою.
Апаратура третьої сходинки містить комбінаційний АЛП із мультиплексорами на кожному вході і схему (Zero?) визначення істинності чи хибності умови інструкції умовного переходу. Особливість інформаційного тракту – залучення до нього двох пристроїв пам’яті: даних DM і інструкцій ІМ. Саме через це мова йдеться про інформаційний тракт, а не процесор.
Призначення інших вузлів є зрозумілим з рисунку. На завершення зауважимо, що регістровий файл має два порти на читання і один порт на запис. Ця особливість є прямим наслідком запроваджених в DLX системи інструкцій і конвеєрного принципу роботи.

Рис. 4 - Інформаційний тракт конвеєрної DLX машини [Hennessy & Patterson, 2003]
З метою спрощення на рисунку пристрій керування не зазначено.
Кеш-пам’ять в RISC-процесорі
В RISC-процесорі DLX є два кеші: кеш команд - IM (Instruction Memory) та кеш даних DM (Data Memory). Вони збільшують швидкість обміну даних між процесором та зовнішньою пам’яттю MEM(Memory).
Введемо поняття блок (рядок) та відображення.
Блок є базовою одиницею інформації, яка переміщається між основною та кеш-пам’яттю. Отже, основна пам'ять складається з великої кількості рядків з послідовними адресами. В кеш-пам’яті поняття послідовний адрес відсутнє. Тут кожне слово супроводжується адресним тегом, що вказує на те, який рядок основної пам’яті представляє даний рядок кешу.
Відображенням називається спосіб розміщення і вибірки рядків основної пам’яті з кешу.
Існує три основних типи відображення:
· Повністю асоціативна кеш-пам'ять. Будь-який рядок основної пам’яті може знаходитись в будь-якому рядку кешу. Кожен радок кешу містить свій компаратор. Коли процесору потрібен рядок з певною адресою, він повинен шукати її шляхом порівняння адреси з тегами всіх рядків кешу. Якщо таке порівняння здійснювати послідовно, то кеш втрачає зміст через низьку швидкодію. Якщо ж порівняння робити одночасно зі всіма тегами, то така пам'ять через свою складність буде мати великий об’єм.
Кеш-пам'ять асоціативного типу здебільшого має малий об’єм та використовується в допоміжних цілях. В серійних універсальних процесорах він не використовується через складність реалізації.
· Кеш з прямим відображенням. Одна з можливих реалізацій використовує розрядне відображення. Наприклад, якщо в адресі рядка присутні N розрядів то молодші n з них вибирають, в який рядок кешу може копіюватись рядок основної памяті. Отже, всі рядки з однаковими молодшими адресами потрапляють в один і той самий рядок кешу. M-n розрядів, що залишилися, використовуються як адресний тег для порівняння з адресою, виданою процесором.
Основною перевагою є те, що кеш має структуру звичайної пам’яті з прямою адресацією, потрібен лише один компаратор. Отже пам'ять такого типу може мати великий об’єм.
Основний недолік – в кеші може знаходитись обмежене число комбінацій рядків.
Як наслідок збільшується кількість промахів.
· Кеш-пам'ять з множинно-асоціативним доступом. В такій реалізації як і в пам’яті з прямим відображенням використовується схема вибору рядка з кешу по молодшим розрядам адреси основної пам’яті, але в такому рядку кешу міститься одразу декілька слів основної пам’яті, вибір між якими здійснюється на основі асоціативного пошуку.
Кеш з прямим відображенням
Кожний блок пам’яті, що складають у середньому з (16 –64) сусідніх з точки зору адресування слів, можна копіювати не до будь-якого, а тільки до наперед визначеного блоку робочої пам’яті кеша. В нас номер блоку кеша, що приймає участь у копіюванні, однозначно визначено за допомогою семи розрядів адреси процесора, які містить поле Block (рис.5). Негайно зауважимо, що процесор “не розуміє” і не “сприймає” структурної інтерпретації адреси, що згенерував. Таку інтерпретацію адресі надає лише і тільки лише контролер кеша, коли “незаконно, без відома процесора” перехоплює цю адресу, що призначена пам’яті даних або пам’яті інструкцій.
Нехай адреса, яку генерує процесор при читанні вмістимого однієї комірки пам’яті (тобто, слова) до власного регістра, має довжину 16 бітів. В цьому випадку, контролер кеша за допомогою семи середніх розрядів адресного слова звертається до визначеного цими розрядами блоку власної пам’яті. Зрозуміло, що бінарний номер кеша є збіжним з бінарним наповненням поля Block адреси процесора. Шуканий в такий спосіб блок завжди присутній в робочій пам’яті кеша. При цьому кеш мусять скласти з 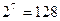 блоків.
блоків.
Але вмістиме винайденого блоку робочої пам’яті кеша може бути копією не одного, а одного з декількох дозволених на копіювання блоків пам’яті. Наприклад, в нас до нульового блоку кеша дозволено копіювати наступні блоки пам’яті: 0, 128, 256, 512 і т.д. Усього до кожного блоку кеша можна скопіювати один з  блоків пам’яті. Ясно, що інформаційна місткість пам’яті в 32 рази перевищує місткість кеша. Таке співвідношення місткостей є коректним гідно до означення парадоксу пам’яті. Доходимо висновку, що нас задовільнить лише однин з 32-х можливих варіантів копіювання. Питання лише в тому, чи є поточне наповнення визначеного блоку кеша відповідним запитанню процесора? Питання розв’язують за допомогою вмістимогостарших п’яти бітів адреси процесора, які утворюють поле із назвою Tag.
блоків пам’яті. Ясно, що інформаційна місткість пам’яті в 32 рази перевищує місткість кеша. Таке співвідношення місткостей є коректним гідно до означення парадоксу пам’яті. Доходимо висновку, що нас задовільнить лише однин з 32-х можливих варіантів копіювання. Питання лише в тому, чи є поточне наповнення визначеного блоку кеша відповідним запитанню процесора? Питання розв’язують за допомогою вмістимогостарших п’яти бітів адреси процесора, які утворюють поле із назвою Tag.

Рис. 5. Внутрішня структура кеша з прямою проекцією; в кеші внутрішню структуру кожного блоку як сукупності множини слів відбито, а пам’яті – приховано
Якщо при вже визначеному номері блоку вмістиме блоку кеша є відповідним, тоді вмістиме полів tag з поля адреси процесора і з мітки блоку робочої пам’яті кеша співпадають, тоді у блок кеша в поточний момент містить потрібну копію. В цьому випадку фіксують ситуацію “влучення до кеша” (cache hit). Лишається за допомогою бітів правого поля формату адреси Word визначити шукане слово в межах винайденої в кеші копії блоку, яку щойно знайдено і перевірено на адекватність, та переслати це слово до входу процесора. Бачимо, що адресне запитання процесора на читання вмістимого комірки перехопив та задовільнив швидкий кеш, а повільна пам’ять не працювала.
Інша ситуація з назвою промах (cache miss) виникає при розбіжності вище зазначених двох тегів. Контролер кеша вимушений перетранслювати адресне запитання від процесора до повільної пам’яті та перейти (разом із процесором) до стану очікування результатів роботи пам’яті на читання. Аби зменшити кількість звернень до пам’яті навіть у цій ситуації, читають не одне, вказане адресою процесора слово, а цілий інформаційний блок (з 16-64 сусідніх слов), який, безперечно, мусить містити шукане процесором слово пам’яті. Тут спрацьовує принцип локалізації адресних звертань процесора – “ наступне слово, що знадобиться процесору, скорше від усього, буде мати і наступну адресу”.
Блок надсилають до кеша, де йогон копіюють до блоку робочої пам’яті із вже відомим номером, і, водночас, потрібне слово з цього блоку, подають до інформаційного входу процесора. Зрозуміло, що при копіюванні інформаційного блоку з пам’яті до блоку робочої пам’яті кеша перевизначають вмістиме відповідного тегового поля.
Під час запису (пересилання слова з регістру процесора до комірки пам/яті) робота контролера кеша виконується так. Спочатку визначають присутність або відсутність копії блоку, який містить старе значення, відповідного до наданої процесором адреси. У разі влучення до кеша запис виконують як до блоку кеша, так і до блоку пам’яті, інакше тільки до блоку пам’яті Але в обидвох випадках запис виконують повільно через обов’язкову участь у ньому повільної пам’яті даних. Зазначимо, що пояснений алгоритм запису реалізує так званий кеш із наскрізним записом.
Більш складні, але ефективні алгоритми запису, ми не розглядаємо і пропонуємо з цього питання звернутися до літературних джерел.
Реалізація кешу команд з прямим відображенням
На рис. 6 представлено функціональну схему кешу команд.
На вхід кешу поступає адреса команди. Кеш визначає чи є потрібний блок зовнішньої пам’яті у пам’яті кешу (Cache MEM). Це здійснюється порівнянням (за допомогою компаратора) номера блоку зчитаного із пам’яті тегів (TAG MEM), для текучої секції із номером блоку взятим із вхідної адреси. В результаті на виході компаратора (==) є сформований сигнал порівняння CH (Cache Hit), котрий надходить до керуючого пристрою кешу (Instruction Control Unit). Якщо такий блок є (активний рівень сигналу СН), то на вхід пам’яті кешу подається номер секції та номер байту в середині блоку, вибраного за допомогою мультиплексора із вхідної адреси, а з виходу зчитується потрібне слово.
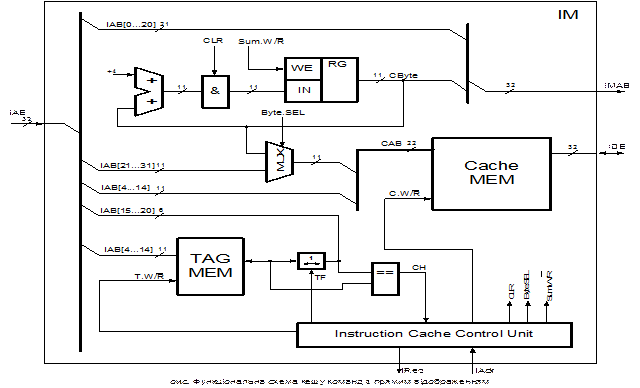
Якщо ж, потрібний блок зовнішньої пам’яті в пам’яті кешу відсутній, то кеш починає зчитувати його. Так як по двонаправленій шині даних можна прочитати тільки одне слово, то для читання цілого блоку кеш організовує цикл читання блоку із пам’яті. Номер секції береться із вхідної адреси. А номер байту індексується і надходить до адресної шини кешу CAB через мультиплексор, який адресується сигналом керуючого пристрою Byte.SEL. Індексація здійснюється комбінаційною схемою, яка складається із додавача (збільшує текучий індекс на 4), обнулювача (встановлює значення індексу в нуль за керуючим сигналом CLR), регістра (записує значення текучого сигналу за керуючим сигналом  ) та містить зворотній зв’язок (для збільшення значення індексу). Після зчитування блоку його номер записується до пам’яті тегів, при цьому передача даних із шини адреси текучої команди на вхід/вихід пам’яті тегів дозволяється елементом із третім станом, який керується керуючим сигналом TF.
) та містить зворотній зв’язок (для збільшення значення індексу). Після зчитування блоку його номер записується до пам’яті тегів, при цьому передача даних із шини адреси текучої команди на вхід/вихід пам’яті тегів дозволяється елементом із третім станом, який керується керуючим сигналом TF.
Реалізація кешу даних з прямим відображенням
Процес читання із кешу даних такий самий як і в кеші команд тільки пам’ять кешу команд має у собі ще комбінаційну схему, котра для команди LBU на вихідну 32-ох розрядну шину видає слово, в молодшому байті якого є потрібний (адресований) байт, а решта байти заповнені нулями (unsigned). Загалом, різниця між кешами полягає у тому, що в них різні формати адрес та дані можна записувати у зовнішню пам’ять через кеш даних. При записі даних у зовнішню пам’ять (команда SW), запис відбувається спочатку в зовнішню пам’ять, а потім у пам’ять кешу. Якщо в кеші блок зовнішньої пам’яті у котрий відбувається запис відсутній, то цей блок зчитується із пам’яті (у ньому вже є записане слово).

|
|