Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Анализ и интерпретация результатов моделирования на ЭВМ
|
|
Как правило, количественная оценка степени влияния того или иного фактора на значения наблюдаемой переменной (показателя эффективности) вызывает значительную сложность, особенно при наличии взаимного влияния факторов. Наиболее простой и доступный способ решения этой проблемы состоит в использовании результатов оценки чувствительности модели.
Однако эти результаты сложно представить в форме аналитической зависимости. Такое представление может оказаться весьма полезным для многих практических задач, связанных как с разработкой моделей (речь опять-таки идет о принципе параметризации), так и непосредственно с принятием решений по экспериментальным данным.
Отыскание аналитических зависимостей, связывающих между собой различные параметры, фигурирующие в модели, может быть основано на совместном использовании группы методов математической статистики: дисперсионного, корреляционного и регрессионного анализа. Подробному и строгому описанию соответствующих процедур посвящено огромное количество книг учебного, научного и справочного характера. Поэтому основная цель изложения последующего материала сводится к тому, чтобы показать роль и место указанных методов при проведении анализа данных, полученных в ходе имитационного эксперимента [3, 10, 12].
Однофакторный дисперсионный анализ. Его суть сводится к определению влияния на результат моделирования одного выбранного фактора.
Пусть, например, исследователя интересует средняя интенсивность отказов компьютера, и в созданной им модели учтены следующие факторы: интенсивность поступления заданий пользователей, интенсивность обращений в оперативную память, временные характеристики решаемых задач и интенсивность обращений к жесткому диску. Если предварительные данные говорят о том, что основной причиной отказов является ненадежная работа жесткого диска, то в качестве анализируемого фактора целесообразно выбрать интенсивность обращений к нему. Задача факторного анализа в данном случае состоит в том, чтобы оценить влияние указанного фактора на среднее число отказов.
Формально постановка задачи однофакторного дисперсионного анализа состоит в следующем. Пусть интересующий нас фактор х имеет l уровней. Для каждого из них получена выборка значений наблюдаемой переменной у: yj (1), уj (2),..., уj (l), j =1,..., п, п — объем выборки (число наблюдений).
Необходимо проверить гипотезу H 0 о равенстве средних значений выборок (т.е. о независимости значений у от значений исследуемого фактора х). Уравнение однофакторного дисперсионного анализа имеет вид:
yij = т+ аi+ еij,
где уij —j-e значение у в i -й серии опытов,
т — генеральное среднее случайной величины у (т. е. среднее значение наблюдаемой переменной, обусловленное ее «сущностью»),
аi— неизвестный параметр, отражающий влияние факторов («эффект» i -го значения фактора х),
еij — ошибка измерения у.
Для проверки гипотезы Н 0 используют F -критерий и переходят от проверки значимости различий средних к проверке значимости различий двух дисперсий:
- генеральной (обусловленной погрешностями измерений) — D0;
- факторной (обусловленной изменением фактора x) — Dx.
Значение F -критерия вычисляется как отношение Dx/D0 или D0/Dx (в числителе должна стоять большая из дисперсий); затем по таблице F -распределений находят его критическое значение Fкр для заданного уровня значимости и числа степеней свободы.
Если F> Fкр, то гипотезу H 0 отвергают, т. е. различия являются значимыми (фактор х влияет на значения у).
Многофакторный дисперсионный анализ (МДА) позволяет оценивать влияние на наблюдаемую переменную уже не одного, а произвольного числа факторов. Точнее, МДА позволяет выбрать из группы факторов, участвующих в эксперименте, те, которые действительно влияют на его результат.
Методику проведения многофакторного дисперсионного анализа рассмотрим применительно к частичному факторному эксперименту, проводимому в соответствии с латинским планом.
Пусть в эксперименте рассматриваются один первичный фактор и два вторичных, каждый из которых имеет п уровней (т. е. объем испытаний равен N=п2).
Обозначим через уijk результат эксперимента при условии, что фактор а находился на уровне i, фактор b —на уровне j, фактор с —на уровне k. Множество значений, которые может принимать упорядоченная тройка (i, j, k), обозначим через L.
В этом случае уравнение дисперсионного анализа выглядит следующим образом:
yijk=m+ai+bj+gk+eijk,
где т — генеральное среднее случайной величины у,
ai, bj, gk — неизвестные параметры («эффекты» соответствующих факторов). Решение задачи дисперсионного анализа заключается в проверке гипотез о независимости результатов измерений от факторов а, b, с.
Для этого по методу наименьших квадратов (МНК) находят оценки параметров m, ai, bj, gk, минимизируя по указанным переменным (поочередно) функцию

Затем по каждому фактору вычисляется F -статистика. Величина F есть мера потерь при принятии гипотезы H 0. Чем больше F, тем хуже модель, отвергающая влияние соответствующего фактора. Таким образом, если вычисленное значение F больше Fкр, найденного по таблице для некоторого уровня значимости, то гипотеза отвергается.
Необходимо отметить, что дисперсионный анализ может использоваться для оценки влияния факторов, имеющих как количественный характер, так и качественный, поскольку в уравнении дисперсионного анализа фигурируют не сами факторы, а только их «эффекты».
Корреляционный и регрессионный анализ. Это два близких метода, которые обычно используются совместно для исследования взаимосвязи между двумя или более непрерывными переменными.
Методы корреляционного анализа позволяют делать статистические выводы о степени зависимости между переменными.
Величина линейной зависимости между двумя переменными измеряется посредствомпростого коэффициента корреляции, величина зависимости от нескольких - посредствоммножественного коэффициента корреляции.
В корреляционном анализе используется также понятиечастного коэффициента корреляции, который измеряет линейную взаимосвязь между двумя переменными без учета влияния других переменных.
Если корреляционный анализ позволил установить наличие линейной зависимости наблюдаемой переменной от одной или более независимых, то форма зависимости может быть уточнена методами регрессионного анализа.
Для этого строится такназываемое уравнение регрессии, которое связывает зависимую переменную с независимыми и содержит неизвестные параметры. Если уравнение линейно относительно параметров (но необязательно линейно относительно независимых переменных), то говорят о линейной регрессии, в противном случае регрессия нелинейна.
Рассмотрим простой корреляционный анализ, т. е. метод определения взаимосвязи между двумя переменными.
Обозначим их х и у. Независимо от способа получения выборки имеются два предварительных шага для определения существования и степени линейной зависимости между х и у. Первый шаг заключается в графическом отображении точек (хi, уi) на плоскости (х, у) - т. е. в построении диаграммы рассеяния. Анализируя диаграмму рассеяния, можно решить, допустимо ли предположение о линейной зависимости между х и у (рис.16.1.).
Если rxy не равен нулю, то на втором шаге вычисляется его точное значение.
Чем больше по абсолютному значению rxy, тем сильнее линейная зависимость между переменными. При | rxy |=1 имеет место функциональная линейная зависимость между х и у вида y = b0 + b1х, причем если rxy = +1, то говорят о положительной корреляции, т.е. большие значения одной величины соответствуют большим значениям другой; при rxy =-1 имеет место отрицательная корреляция; при 0< rxy < 1 вероятна либо линейная корреляция с рассеянием (рис.16.1., б), либо нелинейная корреляция (рис.16.1., г).
При анализе результатов ИМ необходимо иметь в виду, что если даже удалось установить тесную зависимость между двумя переменными, это еще не является прямым доказательством их причинно-следственной связи. Возможно, имеет место стохастическая зависимость, обусловленная, например, коррелированностью псевдослучайных чисел, используемых в имитационной модели.
Поэтому результаты корреляционного анализа целесообразно уточнить, проведя регрессионный анализ.
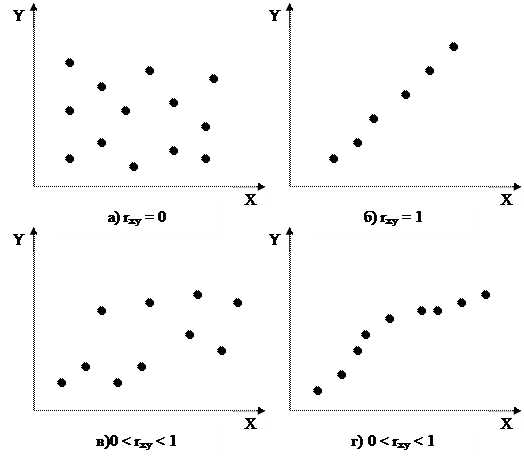 |
Рис. 16.1. Графическое отображение корреляции переменных
Регрессионный анализ позволяет решать две задачи:
1. устанавливать наличие возможной причинной связи между переменными;
2. предсказывать значения зависимой переменной по значениям независимых переменных. Эта возможность особенно важна в тех случаях, когда прямые измерения зависимой переменной затруднены.
Если предполагается линейная зависимость между х и у, то она может быть описана уравнением вида:
yi =b0 + b1* xi + ei (i =1,..., п, п - объем испытаний), которое называется простой линейной регрессией у по х.
Величины b0 и b 1, являются неизвестными параметрами, а еi - случайные ошибки испытаний.
Цель регрессионного анализа - найти наилучшие в статистическом смысле оценки параметров b0 и b1 (величину b1 обычно называют коэффициентом регрессии).
Контрольные вопросы
1. В чем суть однофакторного дисперсионного анализа?
2. Охарактеризуйте многофакторный дисперсионный анализ.
3. Что такое корреляционный анализ?
4. Для чего нужна диаграмма рассеяния?
5. Какая цель регрессионного анализа?
|
|