Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Нормальное распределение вероятностей
|
|
ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 4
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ О ВИДЕ закона РАСПРЕДЕЛЕНИЯ
Нормальное распределение вероятностей
Проверка статистических гипотез о виде закона распределения по критерию согласия Пирсона (хи-квадрат)
Нормальное распределение вероятностей
Нормальное распределение получило широкое распространение для приближенного описания случайных явлений, в которых на результат воздействует большое количество независимых случайных факторов, среди которых нет сильно выделяющихся. Например, ошибки измерения.
В Excel для вычисления значений нормального распределения используются функции: НОРМРАСП, НОРМСТРАСП, НОРМОБР, НОРМСТОБР и НОРМАЛИЗАЦИЯ.
Функция НОРМРАСП вычисляет значения вероятности нормальной функции распределения для указанного среднего и стандартного отклонения. Эта функция имеет очень широкий круг приложений в статистике, включая проверку гипотез.
Функция имеет параметры – НОРМРАСП (х; среднее; стандартное_откл; интегральная). Здесь:
х – значение, для которого строится распределение;
среднее – среднее арифметическое распределение;
стандартное_откл – стандартное отклонение распределения;
интегральная – логическое значение, определяющее форму функции. Если интегральная имеет значение Истина, то функция НОРМРАСП возвращает интегральную функцию распределения; если это аргумент имеет значение ЛОЖЬ, то вычисляет значение функция плотности распределения. Если среднее = 0 и стандратное_откл = 1, то функция НОРМРАСП возвращает стандартное нормальное распределение, то есть НОРМСТРАСП.
Функция НОРМСТРАСП используется для вычисления стандартного нормального интегрального распределения. Это распределение имеет среднее равное нулю и стандартное отклонение равное единице. Эта функция может использоваться вместо таблицы для стандартной нормальной кривой.
Функция имеет параметры – НОРМСТРАСП(z), где z -значение случайной величины, для которого строится распределение.
Функция НОРМОБР вычисляет значения квантилей для указанного среднего и стандартного отклонения (решения уравнения F(х) = р).
Функция имеет параметры – НОРМОБР (вероятность; среднее; стандартное_откл). Здесь:
вероятность – вероятность, соответствующая нормальному распределению;
q среднее – среднее арифметическое распределения;
q стандартное_откл – это стандартное отклонение распределения.
Функция НОРМСТОБР аналогична функции НОРМОБР в случае, если среднее = 0 и стандартное_отклонение = 1. при этом используется стандартное нормальное распределение. Единственным параметром функции НОРМСТОБР является вероятность:
Функция НОРМАЛИЗАЦИЯ позволяет по значению х и параметрам распределения найти нормализованное значение, соответствующее заданному х. Формат функции – НОРМАЛИЗАЦИЯ(х; среднее; стандартное_отклонение).
Пример 1. Построить диаграмму нормальной функции плотности вероятности f(х) при М = 24, 3 и s =1, 5.
Решение.
1. В ячейку А1 вводим символ случайной величины х, а в ячейку В1 – символ функции плотности вероятности – f(х).
2. Вычисляем диапазон М ± 3s - от 19, 8 до 28, 8. вводим в диапазон А2: А21 значения х от 19, 8 до 28, 8 с шагом 0, 5. Для этого в ячейку А2 вводим левую границу диапазон (19, 8), а затем Правка – Заполнить – Прогрессия – расположение по столбцам, шаг – 0, 5, предельное значение – 28, 8.
3. Устанавливаем табличный курсор в ячейку В2 и для получения значения вероятности воспользуемся специальной функцией – нажимаем на панели инструментов кнопку Вставка функции (fх). В появившемся диалоговом окне Мастер функций – шаг 1 из 2 слева в поле Категория указаны виды функций. Выбираем Статистическая. Справа в поле Функция выбираем функцию НОРМРАСП. Нажимаем на кнопку ОК. Появляется диалоговое окно НОРМРАСП. В рабочее поле х вводим значение х, для которого строится распределение (в примере адрес ячейки А2 щелчком мыши на этой ячейке). В рабочее поле Среднее вводим с клавиатуры значение математического ожидания М (в примере – 24, 3). В рабочее поле Стандартное_откл вводим с клавиатуры значение среднеквадратического отклонения s (в примере –1, 5). В рабочее поле Интегральный вводим с клавиатуры вид функции распределения – интегральная или весовая (в примере - 0). Нажимаем на кнопку ОК В ячейке В2 появляется вероятность р=0, 002955. Указателем мыши а правый нижний угол табличного курсора протягиваем (при нажатой левой кнопке мыши) яз ячейки В2 до В21 копируем функцию НОРМРАСП в диапазон В3: В21. По полученным данным строим диаграмму нормальной функции распределения. Щелчком указателя мыши на кнопке на панели инструментов вызываем Мастер диаграмм. В появившемся диалоговом окне выбираем тип диаграммы График, вид – левый верхний. После нажатия кнопки Далее указываем диапазон данных – В1: В21 (с помощью мыши). Проверяем положение переключателя Ряды: в столбцах. Выбираем вкладку Ряд и с помощью мыши вводим диапазон подписей оси Х: А2: А21. нажав на кнопку Далее, вводим названия осей Х и Y: x и f(x), соответственно. Нажав на кнопку Готово. Получен приближенный график нормальной функции плотности распределения:
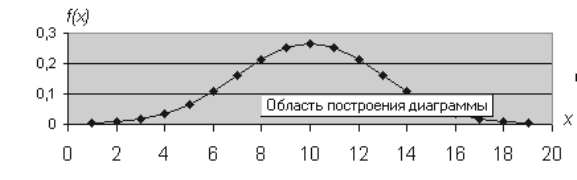
Рис.1
Исследуем, как влияют параметры на вид графика. Для этого изменяем Среднее значение 24, 33 на значение 34, нажимаем Enter. Видим, что график сместился вправо, изменяем на 14, график сместился влево. Возвращаем значение 24, 33, и изменяем в В2 значение 1, 5 на 2. График растянулся. Изменяем в В2 на 0, 5 – график сжался. Делаем вывод: Параметр m изменяет положение графика, с увеличением параметра график смещается вправо. Параметр s влияет на ширину графика, с увеличением параметра график растягивается.
ПРОВЕРКА СТАТИСТИЧЕСКИХ ГИПОТЕЗ О ВИДЕ закона РАСПРЕДЕЛЕНИЯ по критерию согласия Пирсона (хи-квадрат)
Цель: ознакомиться с методами проверки статистических гипотез о принадлежности генеральной совокупности, представленной выборочными данными, к тому или иному типу распределений, используя критерий согласия Пирсона (хи-квадрат) с помощью ПЭВМ.
Методы проверки статистических гипотез занимают центральное место в исследованиях математической статистики. Одной из важнейших групп критериев проверки гипотез являются критерии проверки гипотез о виде распределений (критерии согласия). Они по выборочным данным проверяют предположение о принадлежности генеральной совокупности к тому или иному виду распределений. Одним из наиболее мощных критериев согласия является критерий Пирсона, называемый еще критерием хи-квадрат.
Распределение можно считать соответствующим теоретическому если выполняется условие:
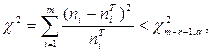 (1)
(1)
где 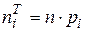 – теоретические частоты попадания в i -ый интервал;
– теоретические частоты попадания в i -ый интервал; 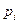 - вероятность попадания в i -ый интервал;
- вероятность попадания в i -ый интервал; 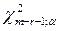 – табличное значение распределения χ 2 для числа степеней свободы k=m-r-1 и уровня значимости α; r – число параметров гипотетического закона распределения.
– табличное значение распределения χ 2 для числа степеней свободы k=m-r-1 и уровня значимости α; r – число параметров гипотетического закона распределения.
ПРИМЕР 2. Имеется выборка прибыли (тыс. руб.) коммерческой фирмы за 40 дней. Необходимо проверить статистическую гипотезу о том, что прибыль данной фирмы распределена по нормальному закону распределения. Взять уровень значимости a = 0, 05.
| Выборка прибыли коммерческой фирмы за 40 дней (тыс. руб.) |
| 64 56 69 78 78 83 47 65 77 57 61 52 50 58 60 48 62 63 68 64 |
| 64 64 79 66 65 62 85 75 88 61 82 52 72 75 84 66 62 73 64 74 |
Для проверки гипотезы о принадлежности генеральной совокупности нормальному виду распределений необходимо строить группированный статистический ряд, т.к. нормальное распределение является непрерывным. Для этого нужно знать размах выборки, который равен разнице между максимальным и минимальным элементами выборки. Кроме того, нужно рассчитать точечные оценки математического ожидания и среднеквадратического отклонения (СКО). Открываем электронную таблицу и вводим данные выборки в нее в ячейки А2-А41, делаем подписи для расчетных параметров в соответствии с рисунком 2:
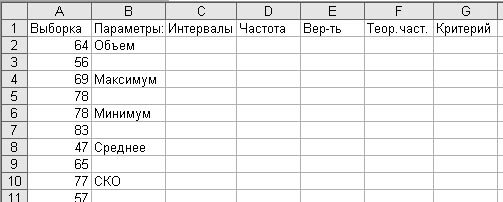
Рис.2
Вычисляем параметры по выборке. Для этого вводим в ячейку В3: =СЧЁТ(A2: A41), (функции можно вводить с помощью мастера функций из категории «Статистические», ссылки на ячейки можно ввести щелкнув мышью по ячейке). В В5 вводим: =МАКС(A2: A41), в В7: =МИН(A2: A41), в В9: =СРЗНАЧ(A2: A41), в В11: =СТАНДОТКЛОН(A2: A41).
Видно, что весь диапазон значений элементов лежит на интервале от 47 до 88. Разобьем этот интервал на интервалы группировки:
[0; 50], (50; 55], (55; 60], (60; 65], (65; 70], (70; 75], (75; 80], (80; 85], (85; 90]. Для этого вводим в ячейки С2-С11 границы интервалов:
| Ячейка С2 С3 С4 С5 С6 С7 С8 С9 С10 С11 |
| Число 0 50 55 60 65 70 75 80 85 90 |
Для вычисления частот 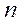 используем функцию ЧАСТОТА. Для этого в D3 вводим формулу =ЧАСТОТА(A2: A41; C3: C11). Затем обводим курсором ячейки D3-D11, выделяя их и нажимаем F2, а затем одновременно Ctrl+Shift+Enter. В результате в ячейках D3-D11 окажутся значения частот.
используем функцию ЧАСТОТА. Для этого в D3 вводим формулу =ЧАСТОТА(A2: A41; C3: C11). Затем обводим курсором ячейки D3-D11, выделяя их и нажимаем F2, а затем одновременно Ctrl+Shift+Enter. В результате в ячейках D3-D11 окажутся значения частот.
Для расчета теоретической вероятности 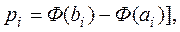 вводим в ячейку Е3 разницу между функциями нормального распределения (функция НОРМРАСП категории «Статистические») с параметрами: «Х» – значение границы интервала, «Среднее» - ссылка на ячейку В9, «Стандартное_откл» - ссылка на В11, «Интегральная» - 1. В результате в Е3 будет формула:
вводим в ячейку Е3 разницу между функциями нормального распределения (функция НОРМРАСП категории «Статистические») с параметрами: «Х» – значение границы интервала, «Среднее» - ссылка на ячейку В9, «Стандартное_откл» - ссылка на В11, «Интегральная» - 1. В результате в Е3 будет формула:
=НОРМРАСП(C3; $B$9; $B$11; 1)-НОРМРАСП(C2; $B$9; $B$11; 1)
Автозаполняем эту формулу на Е3-Е10 перемещая нижний правый угол Е3 до ячейки Е10. В последней ячейке столбца Е11 для соблюдения условия нормировки вводим дополнение предыдущих вероятностей до единицы. Для этого вводим в Е11: =1-СУММ(E3: E10)
Для расчета теоретической частоты вводим в F3 формулу: =E3*$B$3, автозаполняем ее на F3-F11.
Для вычисления элементов суммы 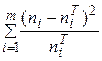 критерия Пирсона вводим в G3 значение «=(D3-F3)*(D3-F3)/F3» и автозаполняем его на диапазон G3-G11.
критерия Пирсона вводим в G3 значение «=(D3-F3)*(D3-F3)/F3» и автозаполняем его на диапазон G3-G11.
Находим значение критерия 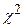 и критическое значение критерия
и критическое значение критерия
Для этого вводим в F12 подпись «Сумма», а в F13 подпись «Критич.». Вводим в соседние ячейки формулы – в G12: =СУММ(G3: G11), а в G13: =ХИ2ОБР(0, 05; 6), здесь параметр a = 0, 05 взят из условия, а степень свободы (k-r-1)=(9-2-1)=6, так как k=9 – число интервалов группировки, а r=2, т.к. были оценены два параметра нормального распределения: математическое ожидание и СКО. Видно, что 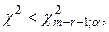 то есть можно считать, что прибыль данной фирмы распределена по нормальному закону распределения.
то есть можно считать, что прибыль данной фирмы распределена по нормальному закону распределения.
Проверим это, построив графики плотностей эмпирического и теоретического распределений. Ставим курсор в любую свободную ячейку и вызываем мастер диаграмм (Вставка/Диаграмма). Выбираем тип диаграммы «График» и вид «График с маркерами» самый левый во второй строке, нажимаем «Далее». Ставим курсор в поле «Диапазон» и удерживая кнопку CTRL обводим мышью область ячеек D3-D11 а затем F3-F11. Переходим на закладку «Ряд» и в поле «Подписи оси Х» обводим область С3-С11. Нажимаем «Готово». Видно, что графики достаточно хорошо совпадают, что говорит о соответствии данных нормальному закону.
Задание 1. Дана выборка числа посетителей Интернет – сайта за 30 дней. Проверить по критерию Пирсона на уровне значимости α =0, 02 статистическую гипотезу о том, что генеральная совокупность, представленная выборкой, имеет нормальный закон распределения.
Вариант Выборка
1. 45 52 49 48 42 51 54 54 50 47 56 53 59 57 50
45 50 46 55 46 54 55 64 67 51 49 47 47 55 40
2. 48 43 52 42 38 57 47 47 51 52 55 53 50 46 53
50 49 58 53 44 51 49 53 51 51 48 45 46 49 54
3. 65 81 76 84 81 80 78 86 85 83 75 85 83 80 77
69 73 78 75 75 91 79 74 67 68 78 80 81 81 81
4. 75 82 79 78 72 81 84 84 80 77 86 83 89 87 80
75 80 76 85 76 84 85 94 97 81 79 77 77 85 70
5. 78 73 82 72 68 87 77 77 81 82 85 83 80 76 83
80 79 88 83 74 81 79 83 81 81 78 75 76 79 84
6. 70 59 57 62 49 63 59 60 57 66 64 57 59 58 59
56 62 56 57 63 59 55 58 62 61 60 59 59 61 63
7. 39 41 35 41 42 38 41 41 36 45 40 39 41 41 40
42 45 39 39 35 41 36 36 39 41 43 40 41 38 44
8. 15 31 26 34 31 30 28 36 35 33 25 35 33 30 27
19 23 28 25 25 41 29 24 17 18 28 30 31 31 31
9. 25 32 29 28 22 31 34 34 30 27 36 33 39 37 30
25 30 26 35 26 34 35 44 47 31 29 27 27 35 20
10. 59 60 65 50 55 64 66 63 55 62 60 58 67 58 65
63 59 57 65 56 66 59 59 60 61 65 59 50 64 63
11. 40 41 37 37 40 42 39 43 38 41 45 44 48 43 28
39 41 39 38 44 37 41 42 45 40 43 35 44 44 44
12. 54 59 55 57 44 42 52 55 49 53 51 50 61 59 53
46 47 44 52 49 48 56 40 52 46 46 45 52 59 57
Критерий Пирсона также можно использовать для проверки предположения о том, что полученные в результате наблюдений данные соответствуют нормам. Пусть имеются некоторые показатели, которые должны соответствовать стандартным нормам. Для проверки из генеральной совокупности получается выборка значений данных показателей. Рассматривается гипотеза о том, что отклонения от норм невелики, и ими можно пренебречь. Рассмотрим проверку гипотезы на примере.
ПРИМЕР 3. На консервном заводе принимаемое зерно горошка считается высшего сорта, если в нем не менее 60 % зерна размером более 7 мм в диаметре, не менее 20% зерна размером 5-7 мм, 10% зерна 4-5 мм и 10% зерна менее 4 мм в диаметре. На завод привезли партию зерна, из которой отобрали одну тонну для проверки. В результате оказалась, что размером более 7 мм в диаметре 550 кг, зерна размером 5-7 мм 220 кг, зерна 4-5 мм 120 кг и зерна размером менее 4 мм 110 кг. Можно ли с вероятностью 0, 95 (α = 0, 05) говорить о том, что привезенное зерно высшего сорта?
Если бы зерно точно бы соответствовало норме, то его количество из одной тонны распределялось бы по размерам как 600 кг, 200 кг, 100 кг и 100 кг. Введем в А1 заголовок «НОРМА» и ниже в А2-А5 показатели – числа 600, 200, 100, 100. В ячейку В1 введем заголовок «НАБЛЮДЕНИЯ» и ниже в В2-В5 наблюдаемые показатели 550, 220, 120, 110. В третьем столбце вводятся формулы для критерия: в С1 заголовок «КРИТЕРИЙ», в С2 формулу «=(А2-В2)*(А2-В2)/А2». Автозаполнением размножим эту формулу на С3-С5. В ячейку С6 запишем общее значение критерия – сумму столбца С2-С5. Для этого поставим курсор в С6 и вызвав функции в категории «Математические» найдем СУММ и в аргументе «Число 1» укажем ссылку на С2-С5. Получится результат критерия Z=11, 16667. для ответа на вопрос, соответствуют ли опытные показатели нормам, Z сравнивают с критическим значением Zкр. Вводим в D1 текст «критическое значение» в Е1 вводим функцию ХИ2ОБР (категория «Статистические») у которой два аргумента: «Вероятность» – вводится уровень значимости a = 1- p (в нашем случае 1-0, 95=0, 05) и «Степени_свободы» – вводят число n-1, где n – число норм (в нашем случае 4-1=3). Результат 7, 814725. Видно, что критическое значение меньше критерия, следовательно опытные данные не соответствует стандартам и зерно с заданной вероятностью нельзя отнести к высшему сорту.
Задание 2. При производстве микросхем процессоров используются кристаллы кварца. Стандартом предусмотрено, чтобы у 50 % образцов не было обнаружено ни одного дефекта кристаллической структуры, у 15% - один дефект, у 13 % - 2 дефекта, у 12 % - 3 дефекта, у 10 % более 3 дефектов. При анализе выборочной партии оказалось, что из 1000 экземпляров распределение по дефектам следующее:
Вариант 0 дефектов 1 дефект 2 дефекта 3 дефекта более 3
1. 489 144 135 122 110
2. 491 145 134 125 105
3. 489 155 133 123 100
4. 483 153 132 130 102
5. 516 148 131 110 95
6. 508 152 129 111 100
7. 494 147 136 121 102
8. 492 155 128 120 105
9. 471 160 137 122 110
10. 471 159 135 127 108
11. 489 156 131 117 107
12. 486 153 136 119 106
Можно ли с вероятностью 0, 99 (при α = 0, 01) считать, что партия соответствует стандарту?
ПРИМЕР 4. В MS Excel критерий хи-квадрат реализован в функции ХИ2ТЕСТ. Функция ХИ2ТЕСТ вычисляет вероятность совпадения наблюдаемых (фактических) значений и теоретических (гипотетических) значений. Если вычисленная вероятность ниже уровня значимости (0, 05), то нулевая гипотеза отвергается и утверждается, что наблюдаемые значения не соответствуют нормальному закону распределения. Если вычисленная вероятность близка к 1, то можно говорить о высокой степени соответствия экспериментальных данных нормальному закону распределения.
Функция имеет следующие параметры:
ХИ2ТЕСТ (фактический_интервал; ожидаемый_интервал).
Здесь:
- фактический_интервал — это интервал данных, которые содержат наблюдения, подлежащие сравнению с ожидаемыми значениями;
- ожидаемый_интервал — это интервал данных, который содержит теоретические (ожидаемые) значения для соответствующих наблюдаемых.
Проверить соответствие выборочных данных (ПРАКТИЧЕСКОЕ ЗАНЯТИЕ 1, пример 1):
64, 57, 63, 62, 58, 61, 63, 60, 60, 61, 65, 62, 62, 60, 64, 61, 59, 59, 63, 61, 62, 58, 58, 63, 61, 59, 62, 60, 60, 58, 61, 60, 63, 63, 58, 60, 59, 60, 59, 61, 62, 62, 63, 57, 61, 58, 60, 64, 60, 59, 61, 64, 62, 59, 65 нормальному закону распределения.
Решение. (пункты 1-7 решения соответствуют примеру 1 ПРАКТИЧЕСКОГО ЗАНЯТИЯ 1).
1. В ячейку А1 введите слово Наблюдения, а в диапазон А2: Е12— значения веса студентов.
2. Выберите ширину интервала 1 кг. Тогда при крайних значениях веса 57 кг и 65 кг получится 9 интервалов. В ячейки G1 и G2 введите названия интервалов Вес и кг, соответственно. В диапазон G4: G12 введите граничные значения интервалов (57, 58, 59, 60, 61, 62, 63, 64, 65).
3. Введите заголовки создаваемой таблицы: в ячейки Н1: Н2— Абсолютные частоты, в ячейки I1: I2 — Относительные частоты, в ячейки J1: J2— Накопленные частоты.
4. Заполните столбец абсолютных частот. Для этого выделите для них блок ячеек Н4: Н12 (используемая функция ЧАСТОТА задается в виде формулы массива). С панели инструментов Стандартная вызовите Мастер функций (кнопка fx). В появившемся диалоговом окне Мастер функций Выберите категорию Статистические и функцию ЧАСТОТА, после чего нажмите кнопку ОК. Появившееся диалоговое окно ЧАСТОТА необходимо за серое поле мышью отодвинуть вправо на 1-2 см от данных (при нажатой левой кнопке). Указателем мыши в рабочее поле Массив_ данных введите диапазон данных наблюдений (А2: Е12). В рабочее поле Двоичный массив мышью введите диапазон интервалов (G4: G12). Последовательно нажмите комбинацию клавиш Ctrl+Shift+ Enter. В столбце Н4: Н12 появится массив абсолютных частот.
5. В ячейке Н13 найдите общее количество наблюдений. Табличный курсор установите в ячейку Н13. На панели инструментов Стандартная нажмите кнопку Автосумма. Убедитесь, что диапазон суммирования указан правильно (Н4: Н12), и нажмите клавишу Enter. В ячейке Н13 появится число 55.
6. Заполните столбец относительных частот. В ячейку I4 введите формулу для вычисления относительной частоты: =Н4/Н$13. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон 15: 112. Получим массив относительных частот.
7. Заполните столбец накопленных частот. В ячейку J4 скопируйте значение относительной частоты из ячейки I4 (0, 036364). В ячейку J5 введите формулу: =J4 + J5. Нажмите клавишу Enter. Протягиванием (за правый нижний угол при нажатой левой кнопке мыши) скопируйте введенную формулу в диапазон J6: J12, Получим массив накопленных частот.
В результате получится таблица (рис. 3)
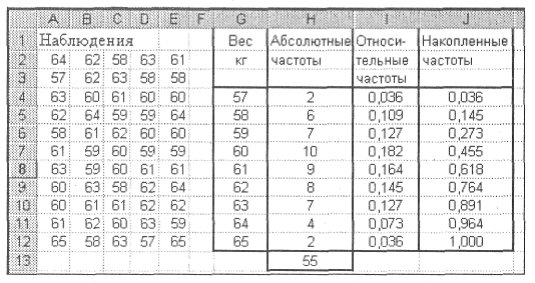
Рис. 3
8. Найдите теоретические частоты нормального распределения. Для этого предварительно необходимо найти среднее значение и стандартное отклонение выборки. В ячейке I13 с помощью функции СРЗНАЧ найдите среднее значение для данных из диапазона А2: Е12 (60, 855). В ячейке J13 с помощью функции СТАНДОТКЛОН найдите стандартное отклонение для этих же данных (2, 05). В ячейки К1 и К2 введите название столбца— Теоретические частости. Затем с помощью функции НОРМРАСП найдите теоретические частости. Установите курсор в ячейку К4, вызовите указанную функцию и заполните ее рабочие поля: х — G4; Среднее — $1$13; Стандартное_откл — $J$13; Интегральный — 0. Получим в ячейке К4 0, 033. Далее протягиванием скопируйте содержимое ячейки К4 в диапазон ячеек К5: К12. Затем в ячейки L1 и L2 введите название нового столбца— Теоретические частоты. Установите курсор в ячейку L4 и введите формулу =Н$13*К4. Далее протягиванием скопируйте содержимое ячейки L4 в диапазон ячеек L5: L12. Результаты вычислений представлены на рис. 4.
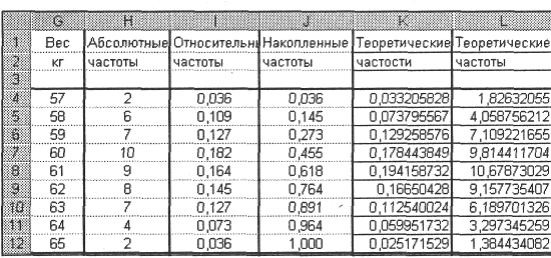
Рис. 4. Результаты вычисления теоретических частостей и частот
С помощью функции ХИ2ТЕСТ определите соответствие данных нормальному закону распределения. Для этого установите табличный курсор в свободную ячейку L13. На панели инструментов Стандартная нажмите кнопку Вставка функции (fx). В появившемся диалоговом окне Мастер функций выберите категорию Статистические и функцию ХИ2ТЕСТ, после чего нажмите кнопку ОК. Появившееся диалоговое окно ХИ2ТЕСТ отодвиньте вправо на 1-2 см от данных. Указателем мыши в рабочие поля введите фактический Н4: Н12 и ожидаемые L4: L12 диапазоны частот (рис. 5). Нажмите кнопку ОК. В ячейке L13 появится значение вероятности того, что выборочные данные соответствуют нормальному закону распределения — 0, 9842.

Рис. 5. Пример заполнения рабочих полей функции ХИ2ТЕСТ
9. Поскольку полученная вероятность соответствия экспериментальных данных р = 0, 98 много больше, чем уровень значимости ά = 0, 05, то можно утверждать, что нулевая гипотеза не может быть отвергнута и, следовательно, данные не противоречат нормальному закону распределения. Более того, поскольку полученная вероятность р = 0, 98 близка к 1, можно говорить о высокой степени вероятности того, что экспериментальные данные соответствуют нормальному закону.
|
|