Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Единицы количества информации: вероятностный и объемный подходы
|
|
ВОПРОС 1
Информация – это сведения, которые можно собирать, хранить, передавать, обрабатывать, использовать.
Информация – это отражение внешнего мира с помощью знаков или сигналов.
Информационная ценность сообщения заключается в новых сведениях, которые в нем содержатся (в уменьшении незнания).
Свойства информации:
- полнота — свойство информации исчерпывающе (для данного потребителя) характеризовать отображаемый объект или процесс;
- актуальность— способность информации соответствовать нуждам потребителя в нужный момент времени;
- достоверность — свойство информации не иметь скрытых ошибок. Достоверная информация со временем может стать недостоверной, если устареет и перестанет отражать истинное положение дел;
- доступность — свойство информации, характеризующее возможность ее получения данным потребителем;
- релевантность — способность информации соответствовать нуждам (запросам) потребителя;
- защищенность — свойство, характеризующее невозможность несанкционированного использования или изменения информации;
- эргономичность — свойство, характеризующее удобство формы или объема информации с точки зрения данного потребителя.
Единицы количества информации: вероятностный и объемный подходы
Определить понятие «количество информации» довольно сложно. В решении этой проблемы
существуют
два основных подхода. Исторически они возникли почти одновременно. В конце 40-х годов
XX века
один из основоположников кибернетики американский математик Клод Шеннон развил
вероятностный
подход к измерению количества информации, а работы по созданию ЭВМ привели к
«объемному» подходу.
Вероятностный подход
Рассмотрим в качестве примера опыт, связанный с бросанием правильной игральной кости,
имеющей N
граней. Результаты данного опыта могут быть следующие: выпадение грани с одним из
следующих знаков:
1, 2,... N.
Введем в рассмотрение численную величину, измеряющую неопределенность — энтропию
(обозначим
ее H). Согласно развитой теории, в случае равновероятного выпадания каждой из граней
величины N и H
связаны между собой формулой Хартли H = log2 N.
Важным при введении какой-либо величины является вопрос о том, что принимать за
единицу ее
измерения. Очевидно, H будет равно единице при N = 2. Иначе говоря, в качестве единицы
принимается
количество информации, связанное с проведением опыта, состоящего в получении одного
из двух
равновероятных исходов (примером такого опыта может служить бросание монеты
при котором возможны
два исхода: «орел», «решка»). Такая единица количества информации называется «бит».
В случае, когда вероятности Pi результатов опыта (в примере, приведенном выше — бросания
игральной
кости) неодинаковы, имеет место формула Шеннона 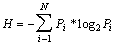 . В случае равновероятности
. В случае равновероятности
событий 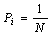 , и формула Шеннона переходит в формулу Хартли.
, и формула Шеннона переходит в формулу Хартли.
В качестве примера определим количество информации, связанное с появлением каждого
символа в
сообщениях, записанных на русском языке. Будем считать, что русский алфавит состоит
из 33 букв
и знака «пробел» для разделения слов. По формуле Хартли H = log2 34 ~ 5.09 бит.
Однако, в словах русского языка (равно как и в словах других языков) различные буквы
встречаются
неодинаково часто. Ниже приведена табл. 3 вероятностей частоты употребления различных
знаков
русского алфавита, полученная на основе анализа очень больших по объему текстов.
Воспользуемся для подсчета H формулой Шеннона: H ~ 4.72 бит. Полученное значение
H, как и
можно было предположить, меньше вычисленного ранее. Величина H, вычисляемая по формуле
Хартли,
является максимальным количеством информации, которое могло бы приходиться на один знак.
Аналогичные подсчеты H можно провести и для других языков, например, использующих
латинский
алфавит — английского, немецкого, французского и др. (26 различных букв и «пробел»).
По формуле
Хартли получим H = log2 27 ~ 4.76 бит.
Рассмотрим алфавит, состоящий из двух знаков 0 и 1. Если считать, что со знаками 0 и 1 в
двоичном
алфавите связаны одинаковые вероятности их появления (P (0)= P (1)= 0.5), то количество
информации на
один знак при двоичном кодировании будет равно H = log2 2 = 1 бит.
Таким образом, количество информации (в битах), заключенное в двоичном слове, равно числу
двоичных
знаков в нем.
Объемный подход
В двоичной системе счисления знаки 0 и 1 называют битами (от английского выражения Binary
digiTs —
двоичные цифры). В компьютере бит является наименьшей возможной единицей информации.
Объем
информации, записанной двоичными знаками в памяти компьютера или на внешнем носителе
информации, подсчитывается просто по количеству требуемых для такой записи двоичных
символов.
При этом, в частности, невозможно нецелое число битов (в отличие от вероятностного подхода).
Для удобства использования введены и более крупные, чем бит, единицы количества информации.
Так, двоичное слово из восьми знаков содержит один байт информации. 1024 байта образуют
|
|