Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Персептрон
|
|
Персептрон – однослойная нейронная сеть, при этом каждый персептронный нейрон в качестве активационной функции использует функцию единичного скачка.
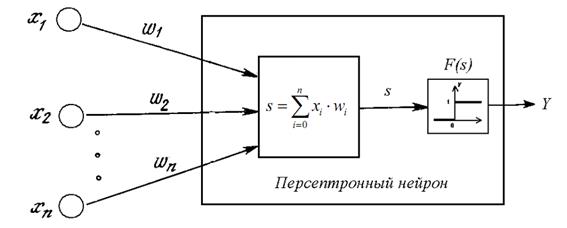
Рис. 10. Однонейронный персептрон с n входами.
АЛГОРИТМ ОБУЧЕНИЯ ОДНОНЕЙРОННОГО ПЕРСЕПТРОНА
Шаг 0. Проинициализировать весовые коэффициенты wi, i= 0, 1, …, n, небольшими случайными значениями (например, из диапазона [–0.3, 0.3])
Шаг 1. Подать на вход персептрона один из обучающих векторов и вычислить его выход.
Шаг 2. Если выход правильный, перейти на шаг 4. Иначе вычислить ошибку – разницу между верным значением и полученным значением выхода.
Шаг 3. Модифицируются весовые коэффициенты:
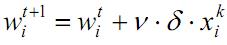
Шаг 4. Шаги 1-3 повторяются для всех обучающих векторов.
АЛГОРИТМ ОБУЧЕНИЯ СЕТИ, ВКЛЮЧАЮЩЕЙ n ПЕРСЕПТРОНОВ
Шаг 0. Проинициализировать элементы весовой матрицы W небольшими случайными значениями.
Шаг 1. Подать на входы один из входных векторов и вычислить его выход.
Шаг 2. Если выход правильный, перейти на шаг 4. Иначе вычислить ошибку – разницу между верным значением и полученным значением выхода.
Шаг 3. Модифицируются весовые коэффициенты:
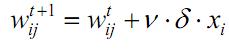
Шаг 4. Шаги 1-3 повторяются для всех обучающих векторов.
Сеть обратного распространения
Нейронные сети обратного распространения — это современный инструмент поиска закономерностей, прогнозирования, качественного анализа. Такое название — сети обратного распространения — они получили из-за используемого алгоритма обучения, в котором ошибка распространяется от выходного слоя к входному, т. е. в направлении, противоположном направлению распространения сигнала при нормальном функционировании сети.
Нейронная сеть обратного распространения состоит из нескольких слоев нейронов, причем каждый нейрон предыдущего слоя связан с каждым нейроном последующего слоя. В большинстве практических приложений оказывается достаточно рассмотрения двухслойной нейронной сети, имеющей входной (скрытый) слой нейронов и выходной слой.
Сеть Кохонена. Классификация образов
Задача классификации заключается в разбиении объектов на классы, причем основой разбиения служит вектор параметров объекта. Часто бывает так, что сами классы заранее неизвестны, и их приходится формировать динамически. Назовем прототипом класса объект, наиболее типичный для своего класса. Один из самых простых подходов к классификации состоит в том, чтобы предположить существование определенного числа классов и произвольным образом выбрать координаты прототипов. Затем каждый вектор из набора данных связывается с ближайшим к нему прототипом, и новыми прототипами становятся центроиды всех векторов, связанных с исходным прототипом.
На этих принципах основано функционирование сети Кохонена, обычно используемой для решения задач классификации. Данная сеть обучается без учителя на основе самоорганизации. По мере обучения векторы весов нейронов становятся прототипами классов — групп векторов обучающей выборки. На этапе решения информационных задач сеть относит новый предъявленный образ к одному из сформированных классов.
Рассмотрим архитектуру сети Кохонена и правила обучения подробнее. Сеть Кохонена состоит из одного слоя нейронов. Число входов каждого нейрона п равно размерности вектора параметров объекта. Количество нейронов т совпадает с требуемым числом классов, на которые нужно разбить объекты (меняя число нейронов, можно динамически менять число классов).
Обучение начинается с задания небольших случайных значений элементам весовой матрицы W. В дальнейшем происходит процесс самоорганизации, состоящий в модификации весов при предъявлении на вход векторов обучающей выборки. Каждый столбец весовой матрицы представляет собой параметры соответствующего нейрона-классификатора. Для каждого у'-го нейрона (/= \, 2, т) определяется расстояние от него до входного вектора X
Далее выбирается нейрон с номером к, 1< £ < т, для которого это расстояние минимально (т. е. сеть отнесла входной вектор к классу с номером к). На текущем шаге обучения N будут модифицироваться только веса нейронов из окрестности нейрона к
Первоначально в окрестности любого из нейронов находятся все нейроны сети, но с каждым шагом эта окрестность сужается. В конце этапа обучения подстраиваются только веса нейрона с номером к. Темп обучения aN с течением времени также уменьшается (часто полагают а0 = 0, 9, aN+] = aN — 0, 001). Образы обучающей выборки предъявляются последовательно, и каждый раз происходит подстройка весов.
Нейроны Гроссберга.Входные и выходные звезды
Входная звезда Гроссберга (S. Grossberg) [45, 46], как показано на рис. 6.14, состоит из нейрона, на который подается группа входов, умноженных на синапсические веса.
 |
Выходная звезда, показанная на рис. 6.15, является нейроном, управляющим группой весов. Входные и выходные звезды могут быть взаимно соединены в сети любой сложности.
 |
Двухслойная сеть встречного распространения
Сеть встречного распространения состоит из двух слоев: слоя нейронов Кохонена и слоя нейронов Гроссберга. Автор сети Р. Хехт-Нильсен удачно объединил эти две архитектуры, в результате чего сеть приобрела свойства, которых не было у каждой из них в отдельности.
Слой Кохонена классифицирует входные векторы в группы схожих. Это достигается с помощью такой подстройки весов слоя Кохонена, что близкие входные векторы активируют один и тот же нейрон данного слоя. Затем слой Гроссберга дает требуемые выходы.
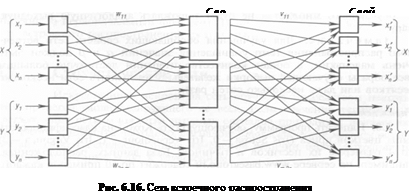
На рис. 6.16 показана сеть встречного распространения полностью.
В режиме нормального функционирования предъявляются входные векторы X и Y, и обученная сеть дает на выходе векторы X' и Y', являющиеся аппроксимациями соответственно для X и Y. Векторы X, Y предполагаются здесь нормированными векторами единичной длины, следовательно, порождаемые на выходе векторы также должны быть нормированными.
 |
В процессе обучения векторы X и Y подаются одновременно и как входные векторы сети, и как желаемые выходные сигналы.
В результате получается отображение, при котором предъявление пары входных векторов порождает их копии на выходе. Это не было бы особенно интересным, если не учитывать способность этой сети к обобщению. Благодаря обобщению предъявление только вектора X (с вектором Y, равным нулю) порождает как выходы X', так и выходы Y'. Если F — функция, отображающая X в К', то сеть аппроксимирует ее. Кроме того, если функция F обратима, то предъявление только вектора Y (при нулевом векторе X) порождает выходы X'.
Уникальная способность порождать функцию и обратную к ней делает сеть встречного распространения полезной в ряде приложений. Например, в задаче аппроксимации многомерной векторной функции сеть обучается на известных значениях этой функции.
Сеть Хопфилда
Нейросетевые архитектуры получили всеобщее признание во многом благодаря исследованиям Джона Хопфилда, физика из Калифорнийского технологического института. Он изучал свойства сходимости сетей на основе принципа минимизации энергии, а также разработал на основе этого принципа семейство нейросетевых архитектур.
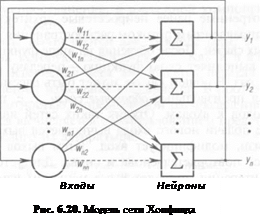 |
Рассмотрим однослойную сеть с обратными связями, состоящую из п входов и п нейронов (рис. 6.20). Каждый вход связан со всеми нейронами. Совокупность выходных значений всех нейронов у. на некотором этапе N образует вектор состояния сети YN. Нейродинамика приводит к изменению вектора состояния на YN+].
Сеть Хопфилда нашла широкое применение в системах ассоциативной памяти, позволяющих восстанавливать идеальный образ по имеющейся неполной или зашумленной его версии
В качестве примера рассмотрим сеть, состоящую из 70 нейронов, упорядоченных в матрицу 10x7.
Сеть обучалась по правилу Хебба на трех идеальных образах — шрифтовых начертаниях латинских букв А, В и С (рис. 6.21). Темные ячейки соответствуют нейронам в состоянии +1, светлые -1.
После обучения нейросети в качестве начальных состояний нейронов предъявлялись различные искаженные версии образов, которые в процессе функционирования сети сходились к стационарным состояниям. Для каждой пары изображений на рис. 6.24 левый образ является начальным состоянием, а правый — результатом работы сети — достигнутым стационарным состоянием.
Опыт практического применения сетей Хопфилда показывает, что эти нейросетевые системы способны распознавать практически полностью зашумленные образы и могут ассоциативно узнавать образ по его небольшому фрагменту. Однако особенностью работы данной сети является возможная генерация ложных образов. Ложный образ является устойчивым локальным минимумом функции энергии, но не соответствует никакому идеальному образу. На рис. 6.24 показано, что сеть не смогла различить, какому из идеальных образов (В или С) соответствует поданное на вход зашумленное изображение и выдала в качестве результата нечто собирательное.

 |
Ложные образы являются «неверными» решениями, и поэтому для исключения их из памяти сети на этапе ее тестирования применяется механизм «разобучения».
Если обученная сеть на этапе тестирования сошлась к ложному образу, то ее весовые коэффициенты пересчитываются/ что гарантирует незначительное ухудшение полезной памяти. После нескольких процедур разобучения свойства сети улучшаются. Это объясняется тем, что состояниям ложной памяти соответствуют гораздо более «мелкие» энергетические минимумы, чем состояниям, соответствующим запоминаемым образам.
Другим существенным недостатком сетей Хопфилда является небольшая емкость памяти. Многочисленные исследования показывают, что нейронная сеть, обученная по правилу Хебба, может в среднем, при размерах сети п, хранить не более чем 0, 14м различных образов. Для некоторого увеличения емкости памяти сети используется специальный алгоритм ортогонализации образов.
Сеть ДАЛ(двунаправленная ассоциативная память)
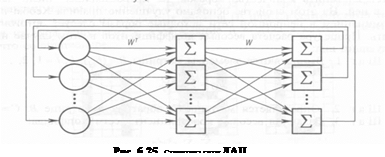
Сеть Хопфилда реализует так называемую автоассоциативную память. Это означает, что образ может быть завершен или исправлен, но не может быть ассоциирован с другим образом. Двунаправленная ассоциативная память (ДАП), разработанная в 1988 году Бертом Коско (В. Kosko) [53], является гетероассоциативной: она сохраняет пары образов и выдает второй образец пары, когда ассоциированный с ним первый образец подается на вход сети. Как и сеть Хопфилда, сеть ДАП способна к обобщению, вырабатывая правильные реакции, несмотря на искаженные входы. Сеть ДАП (рис. 6.25) содержит два слоя нейронов.
 |
|
|