Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Краткие теоретические сведения
|
|
Моделью называется записанная на определенном языке (естественном, математическом и др.) совокупность знаний, представлений и гипотез о соответствующем объекте или явлении. Моделирование – это замещение одного объекта другим с целью получения информации о важнейших свойствах объекта-оригинала с помощью объекта-модели.
Математической моделью называется совокупность знаний, представлений и гипотез о процессе или явлении, записанная на языке математических символов.
Разработка математической модели состоит из четырех взаимосвязанных этапов:
- формулировка целей моделирования;
- определение объекта моделирования;
- выбор структуры (структурный синтез) модели;
- идентификация модели.
Объектом называется реально существующий процесс, выбираемый для моделирования.
При определении объекта моделирования осуществляется его локализация во времени, в пространственных и параметрических координатах.
Локализация объекта во времени состоит в выборе временного интервала функционирования объекта. Для агрегатов периодического действия – это длительность рабочего цикла или его фазы; для агрегатов непрерывного действия – это время процесса в одной технологической цепочке или зоне обработки.
Локализация объекта в пространственных координатах заключается в определении технологических границ, состава основных и вспомогательных агрегатов, направлений материальных и энергетических потоков.
Локализация объекта в параметрических координатах включает в себя выделение совокупности входных переменных Х 1, Х 2, …, Хn, управляющих воздействий U 1, U 2, …, Uk, влияющих на процесс, выходных переменных Y 1, Y 2, …, Ym, характеризующих протекание процесса, а также внутренних параметров модели P 1, P 2, …, Pl.
Управляющие воздействия U 1, U 2, …, Uk являются целенаправленно изменяемыми переменными и формируются на основе информации о входных переменных, которые называются управляемыми. Остальные входные переменные относятся к возмущающим воздействиям, а выходные переменные – к неуправляемым.
Внутренние параметры модели – это внутренние характеристики объекта, не зависящие от процесса моделирования, например, конструктивные параметры агрегатов, теплофизические свойства объектов и т.п.
Возмущающие воздействия и неуправляемые переменные могут быть контролируемыми (наблюдаемыми) и неконтролируемыми (ненаблюдаемыми).
Основными требованиями к выбору объекта моделирования является возможность получения информации о его состоянии (наблюдаемость объекта) и целенаправленного воздействия на его состояние (управляемость объекта).
Следующий этап - структурный синтез модели - включает в себя:
а) выбор математической структуры (дифференциальные, алгебраические уравнения, регрессионные уравнения и др.);
б) определение входных и выходных переменных, вектора внутренних параметров модели и вектора управления;
в) запись уравнений взаимосвязи между выходными переменными, входными воздействиями, управлениями и внутренними параметрами на основе физико-химических закономерностей процесса.
Эффективность математической модели определяется следующими характеристиками:
- адекватность модели – соответствие математической модели объекту в отношении отражения заданных свойств объекта;
- степень целенаправленности поведения модели, в соответствии с которой модели могут быть разделены на одноцелевые и многоцелевые, модели с управлением и без управления;
- сложность, которую можно оценить по общему числу элементов в системе и связей между ними;
- целостность, котораяуказывает на то, что создаваемая модель является одной общей системой, включает в себя большое количество составных частей, находящихся в сложной взаимосвязи друг с другом;
- неопределенность, которая проявляется в системе, оценивается энтропией и позволяет в ряде случаев оценить количество управляющей информации для достижения заданного состояния системы;
- поведенческая стратегия, которая позволяет оценить эффективность достижения системой поставленной цели. Для количественной оценки эффективности управления используются критерии качества;
- адаптивность (приспособляемость) к различным внешним возмущающим факторам в широком диапазоне изменения воздействий внешней среды;
- управляемость модели, вытекающая из необходимости обеспечивать управление со стороны экспериментов для получения возможности рассмотрения протекания процесса в различных условиях, имитирующих реальные (например, управление технологическим процессом в нормальном и в предаварийном состоянии);
- возможность развития модели, которая позволяет создавать мощные системы моделирования для исследования многих сторон функционирования реального объекта. Модель должна быть открытой и позволять включение в ее состав новых подмоделей или подсистем управления.
Математическая модель процесса или явления в общем виде представляется зависимостью:

| (2.1) |
где  – вектор–функция, зависящая от управляющих воздействий, входных переменных и внутренних параметров;
– вектор–функция, зависящая от управляющих воздействий, входных переменных и внутренних параметров;  – выходные переменные,
– выходные переменные,  – вектор входных переменных;
– вектор входных переменных;  – вектор управляющих воздействий;
– вектор управляющих воздействий;  – вектор внутренних параметров.
– вектор внутренних параметров.
наиболее полное отображение процессов в реальных объектах дают системы алгебраических (статика процессов) и дифференциальных уравнений (динамика процессов), которые широко используются в математическом моделировании.
В основе методологии построения математических моделей стохастических процессов и зависимостей, отражающих взаимосвязи между данными, полученными экспериментальным путем лежит теория случайных величин и регрессионный анализ.
Случайной величиной называется величина, которая в результате одного и того же опыта может принять то или иное заранее неизвестное значение. Случайные величины могут быть дискретными (прерывными) и непрерывными. Дискретные случайные величины принимают изолированные числовые значения, отделенные друг от друга конечными интервалами (например: число попаданий при нескольких выстрелах, число появлений герба при нескольких подбрасывания монеты). Значения непрерывных случайных величин не могут быть заранее перечислены и непрерывно заполняют некоторый промежуток (например: ошибка измерения, дальность полета снаряда).
Всякое соответствие между возможными значениями случайной величины и вероятностями, с которыми эти значения принимаются, называется законом распределения случайной величины. Закон распределения количественно может выражаться в следующих формах: табличной, графической и аналитической.
При количественном описании закона распределения вероятностей можно воспользоваться вероятностью события X < x, где x – текущая переменная. Вероятность этого события, есть некоторая функция x. Эта функция называется функцией распределения случайной величины X
| F (x) = P (X< x). | (2.2) |
Одной из форм закона распределения непрерывной случайной величины является плотность распределения вероятностей f (x). Она связана с функцией распределения формулой
| f (x) = F' (x). | (2.3) |
Для решения большинства практических задач закон распределения, т.е. полная характеристика случайной величины, неудобен для использования. Поэтому чаще применяют числовые характеристики случайной величины, определяющие основные черты закона распределения. Наиболее распространенными из них являются математическое ожидание, дисперсия и среднее квадратическое отклонение.
Математическое ожидание непрерывной случайной величины определяется следующим образом:

| (2.4) |
Дисперсия D [ X ] и среднее квадратическое отклонение определяют рассеяние случайной величины около её математического ожидания и вычисляются по формулам
 , ,
| (2.5) | |
 . .
| (2.6) |
В практических применениях теории вероятностей очень часто приходится сталкиваться с задачами, в которых результат опыта описывается не одной, а двумя и более случайными величинами, образующими комплекс или систему.
Свойства системы нескольких случайных величин не исчерпываются свойствами отдельных величин, ее составляющих, они включают также взаимные связи (зависимости) между случайными величинами называемые корреляцией, т.е. корреляция – это связь между двумя или несколькими величинами или исследуемыми объектами.
Корреляция бывает двух видов: детерминированная (определяется строгими закономерностями и обычно описывается физико-химическими формулами) и стохастическая (случайная, вероятностная – проявляется в том, что одна из величин влияет на изменение другой изменениями своего закона распределения).
Характеристикой системы двух случайных величин, описывающей связь между ними является коэффициент корреляции:
 , ,
| (2.7) |
где mx, m y – сокращенное обозначение математического ожидания величины Х и Y, соответственно. mx=M [ X ], my=M [ Y ].Если rxy =0, то корреляционная связь между величинами отсутствует.
Зависимость между случайными величинами называется регрессией. Она понимается как зависимость между математическими ожиданиями этих величин.
Форма связи между случайными величинами определяется линией регрессии, показывающей, как в среднем изменяется величина Y при изменении величины Х, что характеризуют условным математическим ожиданием my/x величины Y, вычисляемым при Х=х. Таким образом, кривая регрессии Y на Х есть зависимость условного математического ожидания Y от известного значения Х.
Задачарегрессионного анализа ставится следующим образом: для каждого i -того опыта имеется набор значений входных параметров X 1 i, X 2 i, …, X n i . и соответствующего этому набору значений выходного параметра Yi.
Необходимо определить зависимость выходного параметра Y от входных факторов X 1 i, X 2 i, …, Xni, которая в случае, например, линейной связи может иметь следующий вид:
| Y = b 0 + b 1 X 1 + b 2 X 2 + …+ b n X n. |
Такая зависимость называется линейной регрессией. Любая другая зависимость называется нелинейной регрессией.
Задача сводится к тому, чтобы при измеренных во время опытов значениях входных переменных X 1, X 2, …, Xn и выходной переменной Y определить коэффициенты уравнения регрессии b 0, b 1, b 2, … bn, которые с определенной степенью вероятности будут отражать влияние аргументов X 1, X 2, …, Xn на Y.
Регрессионная зависимость вида Y=f (Xi) называется однофакторной или парной и описывает связь между двумя переменными: входной Х и выходной Y.
Регрессионная зависимость вида Y=f (X 1, X 2, …, Xn) называется многофакторной или множественной и описывает связь между несколькими входными X 1, X 2, …, Xn и одной выходной Y.
Построение и исследование регрессионной модели можно разбить на четыре этапа.
1 этап. Исследование стохастической связи между рассматриваемыми величинами. Для этого, нужно определить по значению rxy существует ли корреляционная связь между Х и Y.
2 этап. Выбор вида уравнения регрессии. Вид уравнения регрессии выбирается исходя из особенностей изучаемой системы случайных величин. Одним из возможных подходов при этом является экспериментальный подбор типа уравнения регрессии по соответствующим критериям адекватности. В случае же, когда имеется определенная априорная (доопытная) информация об объекте, более эффективным является использование для этой цели теоретических представлений о процессах и типах связей между изучаемыми параметрами.
3 этап. Расчет параметров (коэффициентов) уравнения регрессии. Для определения параметров (коэффициентов) уравнения регрессии, используется метод наименьших квадратов (МНК). Сущность метода заключается в том, что выбирается такая линия регрессии, при которой сумма квадратов разностей между экспериментальными значениями выходной переменной Yi, полученными на объекте, и значениями рассчитанными по выбранной регрессионной формуле (модели)  будет минимальной:
будет минимальной:
 , ,
| (2.8) |
где n – количество экспериментальных данных;  e – критерий близости модели и объекта (отклонения Y i от оцененной линии регрессии), называемый невязкой модели.
e – критерий близости модели и объекта (отклонения Y i от оцененной линии регрессии), называемый невязкой модели.
Задача построения линейной модели сводится к минимизации функции невязки следующего вида:
 . .
|
В качестве нелинейных регрессионных моделей чаще всего используются полиномы разной степени
Yi = b 0 + b 1 Xi + b 2 Xi 2 + b 3 Xi 3 + …+ bmXmm- 1.
4 этап. Проверка адекватности структуры модели. О степени адекватности структуры модели можно судить по значению коэффициента корреляции r или корреляционного отношения h, гистограмме распределения остатков и содержательному анализу остатков модели [10].
Коэффициент корреляции r характеризует степень тесноты линейной связи между  и Y и приближенное значение r определяется по формуле
и Y и приближенное значение r определяется по формуле
 , ,
| (2.9) |
где n – число экспериментальных данных. Коэффициент корреляции изменяется от –1 до +1.
Корреляционное отношение h характеризует степень тесноты нелинейной связи между переменными и Y и рассчитывается по формуле
 , ,
| (2.10) |
где  – текущее значение, вычисленное по математической модели значение параметра Y; Yi – текущее значение, полученное на объекте;
– текущее значение, вычисленное по математической модели значение параметра Y; Yi – текущее значение, полученное на объекте;  – выборочное среднее значение, которое вычисляется по формуле
– выборочное среднее значение, которое вычисляется по формуле
 . .
| (2.11) |
Корреляционное отношение изменяется от 0 до +1.
Следует иметь в виду, что коэффициент корреляции является частным случаем корреляционного отношения и используется обычно только при исследовании линейных моделей. Диапазон изменения коэффициента корреляции (корреляционного отношения) указывает на корреляцию (связь) между
 и Y.
и Y.
Гистограмма распределения остатков модели строится следующим образом. Весь диапазон изменения остатков (от минимального из остатков до максимального) разбивается на несколько равных интервалов или поддиапазонов (в зависимости от размера выборки), которые откладываются на оси абсцисс. Далее на оси ординат отмечается число попаданий остатка в каждый интервал или поддиапазон. Число попаданий ошибки можно откладывать как в натуральных показателях, так и в процентном соотношении. При адекватности модели реальному объекту гистограмма распределения приобретает колоколообразный вид, при неадекватности модели она имеет несимметричный характер или второй горб (рис. 2.1).
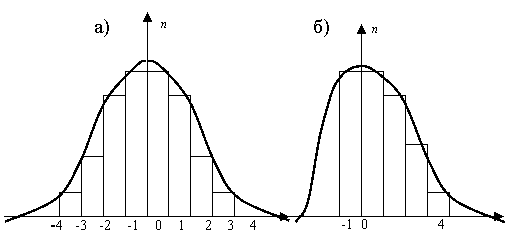
|
| Рис. 2.1. Гистограмма распределения остатков |
Содержательный анализ остатков модели состоит в построении распределения остатков модели в зависимости от входного параметра Х. Попадание большинства данных в горизонтальную полосу, расположенную симметрично оси OX, свидетельствует об адекватности модели.
|
|