Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Индексы
|
|
В таблице БД данные обычно хранятся в том же порядке, в котором их ввели в таблицу. Многие реляционные СУБД имеют страничную организацию, при которой физически таблица может храниться фрагментарно в разных областях диска, причем строки таблицы располагаются на страницах неупорядоченно. Хотя такой способ хранения и позволяет быстро вводить новые данные, но для того, чтобы найти нужную строку, придется просмотреть всю таблицу. В промышленных системах каждая таблица может содержать миллионы строк, поэтому простой перебор ведет к катастрофическому падению производительности ИС.
Чтобы решить проблему поиска данных, СУБД использует особый объект, называемый индексом. Он подобен содержанию книги, которое указывает на все номера страниц, посвященных конкретной теме. Индекс содержит отсортированную по колонке или нескольким колонкам информацию и указывает на строки, в которых хранится конкретное значение колонки.
Например, если необходимо найти клиента по имени (рис. 2.73), можно создать индекс по колонке Customer Name таблицы CUSTOMER. В индексе имена клиентов будут отсортированы в алфавитном порядке. Для имени индекс будет содержать ссылку, указывающую, в каком месте таблицы хранится эта строка.

Рис. 2.73
Для поиска клиента серверу направляется запрос с критерием поиска (Customer Name =" Иванов"). При выполнении запроса СУБД просматривает индекс, вместо того чтобы просматривать по порядку все строки таблицы CUSTOMER. Поскольку значения в индексе хранятся в определенном порядке, просматривать нужно гораздо меньший объем данных, что значительно уменьшает время выполнения запроса. Индекс можно создать для всех колонок таблицы, по которым часто производится поиск.
При генерации схемы физической БД ER-win автоматически создает с дельный индекс на основе первичного ключа каждой таблицы, а также в основе всех альтернативных ключей, внешних ключей и инверсионных входов, поскольку эти колонки наиболее часто используются для поиска данных. Можно отказаться от генерации индексов по умолчанию и для повышения производительности создать собственные индексы, Администратор СУБД должен анализировать наиболее часто выполняемые запросы создавать индексы с различными колонками и порядком сортировки для увеличения эффективности поиска при работе конкретных приложений.
При создании индекса на основе ключа ER-win вводит в его состав в колонки ключа. Например, если в сущности CUSTOMER (рис. 2.73) три атрибута назначены как АК1, ER-win автоматически создает индекс и включает в него весе три атрибута ( Customer Name, Region, City ). Следовательно, на уровне логической модели можно неявно создать индекс, включая колонки в состав альтернативных ключей и инверсионных входов.
ER-win автоматически генерирует имя индекса, созданного на основе ключа по принципу " X" + имя ключа + имя таблицы (физическое имя таблицы, а не логическое имя сущности!), где имя ключа " РК" для первичного ключа, " IFn" - для внешнего, " АКn" - для альтернативного, " IEn" - для инверсионного входа. Например, по умолчанию при создании таблиц CUSTOMER (см. рис. 2.70) будут созданы индексы ХРК CUSTOMER (первичный ключ, в состав войдет колонка CustomerID ), XAKICUSTOMER (альтернативный ключ, колонки Customer Name, Region, City ), XIE CUSTOMER (инверсионный вход 1, колонка Region ) и XIE2CUSTOMER (инверсионный вход 2, колонка Customer Address ),
Изменить характеристики существующего индекса или создать, новы можно в редакторе Index Editor (рис. 2.74). Для его вызова следует щелкнуть правой кнопкой мыши по таблице и выбрать во всплывающем меню пункт Index.
В редакторе Index Editor можно изменить имя индекса, изменить его определение так, чтобы он принимал уникальные или дублирующиеся значения, или изменить порядок сортировки данных.
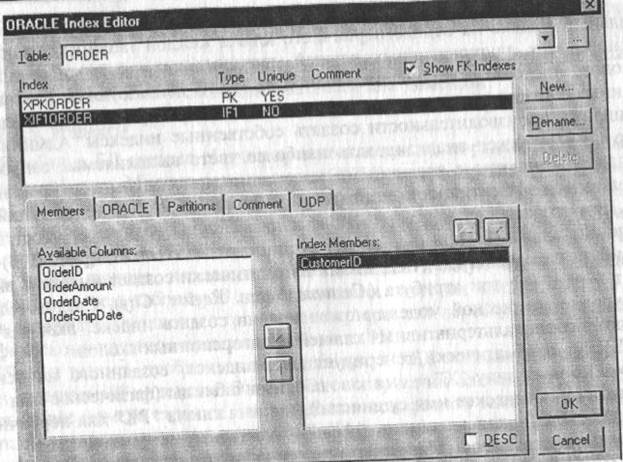
Рис. 2.74. Диалог Index Editor
ER-win создаст индексы, которые могут содержать либо повторяющиеся, либо только уникальные значения. При создании нового уникального индекса (кнопка NewH, диалог New Index, рис. 2.75) следует включить опцию Unique, для создания индекса с неповторяющимися значениями опцию следует выключить. Если на основе колонки создается уникальный индекс, то при попытке вставить запись с неуникальным (повторяющимся) значением сервер выдаст ошибку и значение не будет вставлено. Например, уникальный индекс в таблице CUSTOMER, построенный на колонке Customer Name, предотвратит от внесения двух строк с информацией об одном и
том же клиенте.
Иногда необходимо разрешить повторяющиеся значения, если ожидается, что индексированная колонка будет с большой вероятностью содержать повторяющуюся информацию. Например, на основе инверсионных входов, которые используются для доступа к нескольким строкам и поэтому могут содержать повторяющиеся значения, генерируется неуникальный индекс. Неуникальный индекс генерируется также на основе внешнего ключа. На основе первичного и альтернативных ключей генерируются уникальные индексы.
И наоборот, при создании нового индекса автоматически создается альтернативный ключ для уникального и инверсионный вход для неуникального индекса, а также соответствующее ключу имя индекса. Имя сгенерированного индекса в дальнейшем при необходимости можно изменить вручную.

Рис. 2.75. Диалог New Index
По умолчанию ER-win автоматически сохраняет значения в индексе в порядке возрастания (значения сортируются по алфавиту от А до Z, а числа от 0 до 9). Если нужно изменить порядок сортировки для колонки и выбранная СУБД поддерживает режим сортировки по убыванию, следует выбрать колонку и включить опцию DESC (см. рис. 2.74).
Редактор Index Editor содержит следующие закладки:
Members - позволяет включить колонки в состав индекса;
Comment - содержит комментарий для каждого индекса;
UDP - позволяет связать с индексом свойства, определяемые пользователем;
закладка, соответствующая выбранной СУБД (на рис. 2.76 - ORACLE), задает свойства индекса, специфические для выбранной СУБД.

Рис. 2.76. Закладка ORACLE диалога Index Editor
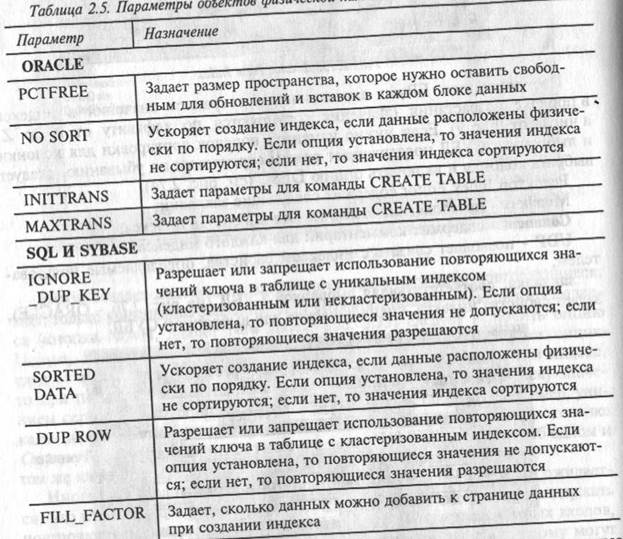
При создании индекса для СУБД ORACLE, SYBASE или SQL Server можно выбирать, в каком объекте физической памяти (создание и редактирование объектов физической памяти рассмотрено в 2.2.6) будет храниться индекс, и изменять параметры хранения. В табл. 2.5 представлены некоторые параметры объектов физической памяти, доступные в закладке, соответствующей выбранной СУБД диалога Index Editor для ORACLE, SYBASE и SQL.
Таблица 2.5. Параметры объектов физической памяти
Некоторые СУБД поддерживают кластеризованные и кластеризованные котированные индексы. ER-win позволяет создать такие индексы для DB2/MVS, DB2/390, HiRDB, INFORMIX, MS Access, MS SQL Server, SYBASE и SQLBase. Для того чтобы сделать индекс кластеризованным, нужно включить опцию CLUSTER в закладке, соответствующей выбранной СУБД. Кластеризованный индекс - это специальная техника индексирования, при которой данные в таблице физически располагаются в индексированном порядке, использованиекластеризованного индекса значительно ускоряет выполнение запросов по индексированной колонке. Например, можно создать кластеризованный индекс в таблице CUSTOMER по колонке City. Информация о всех клиентах из одного города будет физически располагаться на диске рядом, что значительно повысит скорость выполнения запроса, который делает выборку всех клиентов из какого-то определенного города.
Поскольку данные физически расположены в индексированном порядке, для каждой таблицы может существовать только один кластеризованный индекс. Если СУБД поддерживает использование кластеризованного индекса, то ER-win автоматически создает индекс первичного ключа кластеризованным. При создании кластеризованного индекса не по первичному ключу ER-win автоматически снимает кластеризацию с индекса по первичному ключу. Для СУБД SQLBase (CENTURA) ER-win позволяет создать кластеризованный хешированный индекс (clustered hashed index). Хеширование -альтернативный способ хранения данных в заранее заданном порядке с целью ускорения поиска, но физически это более сложно, чем простое сохранение строк в алфавитном порядке или в соответствии с числовыми
Кластеризованный или хешированный индекс значительно ускоряет операции поиска и сортировки, но добавление и удаление строк замедляется из-за необходимости реорганизации данных для соответствия индексу.
|
|