Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
XI. Микроархитектура Sandy Bridge.
|
|
Можно считать, что к 2006 году закончилась эпоха процессоров Intel с микроархитектурой NetBurst (серии Pentium 4, Pentium D), в которой основным способом увеличения производительности процессоров являлось увеличение его тактовой частоты. Причем это переосмысление методов дальнейшего развития микропроцессорной техники пришло примерно в это же время и другим производителям микропроцессоров, например, такими как главный конкурент корпорации Intel фирмы AMD. Причиной этого переосмысления явилось резкое увеличение потребляемой мощности (свыше 130 – 150 Вт на корпус) и, как следствие этого, существенное увеличение затрат на отвод тепла.
С этого времени основной задачей проектировщиков микропроцессоров стало разработка методов не просто максимального увеличения производительности, а достижения высокого уровня производительности при обеспечении энергопотребления на приемлемом уровне, т.е. улучшение энергетической эффективности работы микропроцессоров.
Энергетическую эффективность обычно характеризуют величиной, численно равной среднему количеству поглощенной энергии, приходящейся на одну выполненную инструкцию (Energy Per Instruction, EPI). Она измеряется в джоулях и определяется по формуле:
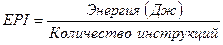
Заметим, что эту характеристику целесообразнее было бы назвать энергетической неэффективностью, так как чем она больше, тем хуже для процессора, с точки зрения удельного потребления энергии.
Поскольку затраченная энергия равна произведению энергетической мощности (Power) на временной интервал (T), а количество выполненных инструкций определится произведением производительности процессора (Performance) на этот временной интервал, то:
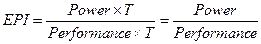
То есть, энергетическую эффективность EPI можно трактовать как потребляемую мощность процессора в расчете на единицу производительности.
С другой стороны, общую производительность процессора можно выразить в виде:

Где F – тактовая частота процессора, а IPC (Instruction Per Cycle) – абсолютная производительность, определяемая как количество инструкций, выполняемых процессором за один такт.
Потребляемая же процессором мощность может быть определена по формуле: 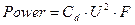
Где U – напряжение питания процессора;
Сd – динамическая емкость - некоторая константа, которая определяется числом транзисторов в микросхеме процессора и активностью их переключения, а также технологией производства.
(Строго говоря, динамическая емкость равна отношению электростатического заряда проводника к разнице потенциалов между проводниками, обеспечивающими этот заряд).
Следовательно, энергетическая эффективность процессора может быть выражена как:

Отсюда следует, что энергетическая эффективность процессора не зависит от тактовой частоты, на которой работает процессор, хотя и существует некоторая зависимость между напряжением питания процессора и его возможной тактовой частотой. При одинаковой тактовой частоте, энергетическая эффективность будет тем меньше, чем меньше Cd, и напряжение питания, и чем больше инструкций выполняется за один такт.
Заметим, при этом, что напряжение питания U определяется, в основном, не архитектурой, а уровнем технологии производства микропроцессоров. Увеличение же абсолютной производительности IPC достигается путем архитектурных усовершенствований, главным образом за счет распараллеливания процессов обработки.
Поэтому разработчики обратили особое внимание на разработке методов распараллеливания вычислительного процесса. К ним относят: усовершенствование методов многозадачного режима работы, и разработка многоядерных процессоров, позволяющих эффективно реализовать этот режим на одном процессоре; разработка методов реализации многопоточной обработки (технология Hyper Threading), позволяющая выполнять одновременно два потока информации на одном ядре процессора; введение технологии SIMD (MMX, SSE, AVX), позволяющей одной инструкцией обрабатывать несколько данных; применение суперскалярных процессоров, использующих несколько исполнительных устройств и, вследствие этого исполнять несколько команд одновременно и пр.
Именно исходя с этой позиции, позиции приоритетности достижения наилучшей энергетической эффективности, специалисты фирмы Intel разработали к 2006 году новую микроархитектуру микропроцессоров – Core Microarchitecture. Эта микроархитектура легла в основу целого ряда новых серий процессоров.
Интересно отметить, что эта новая микроархитектура по сути является не улучшением архитектуры NetBurst (Pentium 4), как казалось бы логичным, а дальнейшим, хотя и существенным, развитием архитектуры P6 – архитектуры предшествующего 6-го поколения семейства Х86 (процессоров Pentium Pro, Pentium II, Pentium III, Pentium M).
Микропроцессоры, основанные на архитектуре Intel Core, стали обрабатывать до 4 инструкций за один такт, т.е. больше, чем все предшествующие МП семейства Х86, а также все, существующие на то время, разработки фирмы AMD. Длина исполнительного конвейера МП с архитектурой Intel Core – 14 ступеней и, следовательно, их тактовые частоты не смогут повышаться до таких значений, которые позволяет архитектура NetBurst. Зато это обстоятельство позволяет существенно повысить эффективность работы микропроцессоров с точки зрения характеристики «производительность на ватт».
Еще в 2007 году корпорация Intel объявила, что в будущем она собирается придерживаться в своей деятельности по созданию новых микропроцессоров концепции «Tick-Tock» - принципа двухгодичной периодичности выпуска новой продукции. Он заключается в том, что в первый год двухлетки, вводится в эксплуатацию новый технологический процесс, для изготовления процессоров уже существующей микроархитектуры. А на второй год, на базе этого технологического процесса, выпускается процессор принципиально новой микроархитектуры и.т.д.
В конце 2008 года было опубликовано сообщение о перспективах дальнейшего развития процессорного направления Intel после выпуска процессоров микроархитектуры Nehalem. Приведенный ниже рисунок (см. рис XI.1) иллюстрирует действие принципа Tick Tock до 2013 года.
`
| Микроархитектура Intel Core (2006 – 2008) | Микроархитектура Intel Nehalem (2009 – 2010) | Микроархитектура Sandy Bridge (2011 – 2012) | Микроархитектура Haswell (2013 -?) | ||||
| Merom New architecture (65 nm) | Penrun New Process Technology (45 nm) | Nehalem New architecture (45 nm) | Westmere New Process Technology (32 nm) | Sandy Bridge New architecture (32 nm) | Ivy Bridge New Process Technology (22 nm) | Haswell New architecture (22 nm) | Broadwell New Process Technology (14 nm) |
| TOCK | TICK | TOCK | TICK | TOCK | TICK | TOCK | TICK |
Рис XI.1 Иллюстрация принципа Tick-Tock развития микропроцессоров
корпорации Intel
Опубликованный план фирма Intel выполняла неукоснительно. Так, в 2011 году поступили в широкую продажу микропроцессоры новой микроархитектуры Sandy Bridge на базе 32 нм технологического процесса. Считается, что ядра микропроцессоров типа Westmere являются последними представителями поколения Intel Core, а микроархитектурa Sandy Bridge является первенцем нового поколения – Intel Core II.
В микропроцессорах архитектуры Sandy Bridge сохранился принцип «динамического исполнения команд», который провозглашен еще при разработке микропроцессоров поколения P6, усовершенствован при разработке микропроцессоров архитектур Intel Core и Nehalem и существенно расширен в микроархитектуре Sandy Bridge.
Этот принцип включает в себя три базовых концепции: предсказание переходов (Branch prediction), динамический анализ потока данных (Dynamic data flow analysis) и спекулятивное выполнение инструкций (‘Speculative execution). Эти концепции возникли и стали реализовываться в связи с внедрением в процессоры, для повышения их производительности, конвейерного принципа выполнения команд.
Предсказание переходов (ветвлений) – это концепция, которая возникла в связи с появлением конвейерного способа исполнения команд и реализуется довольно давно. В микропроцессорах Intel начиная с процессоров семейства P6 (Pentium Pro+), а также в RISC процессорах и даже в микроархитектуре целого ряда высокопроизводительных процессоров типа mainframe, причем с каждой новой микроархитектурой все более и более совершенствуется. Связано это с тем, что в большинстве пользовательским программ на долю условных переходов приходится от 10 % до 20 % команд и до 10 % команд безусловных переходов. И когда в потоке инструкций встречается инструкция безусловного перехода, выборка следующей инструкции может осуществиться только на той ступени конвейера, когда выбран адрес перехода. Для команд безусловных переходов это, в лучшем случае, на этапе (ступени конвейера) выборки операнда (адреса) из памяти. А когда встречается инструкция условного перехода, то вопрос об адресации передачи управления может быть решен только после исполнения инструкции, вырабатывающей условие перехода, т.е. только тогда, когда она достигнет по конвейеру соответствующего исполнительного блока и будет выполнена. Следовательно, если предварительный адрес передачи управления будет выбран неправильно, то все команды, которые уже находятся на различных ступенях конвейера, придется сбрасывать и на конвейер подавать новую цепочку инструкций, начиная с точки разветвления. Все это приводит к существенному снижению производительности процессора и компьютера в целом.
Поэтому прежде чем подавать инструкции на конвейер, они анализируются в так называемом специальном блоке предсказания переходов (ветвлений) (Branch Prediction Unit - BPU). Цель анализа – определить точки ветвления в исполняемом потоке инструкций и предсказать наиболее вероятные ветви (пути) по которым пойдет обработка инструкций после точек ветвления. После определения ветви, инструкции к ней относящиеся тут же ставятся в очередь на исполнение. Этим минимизируется количество сбросов конвейера, и тем самым повышается производительность процессора. Конечно, такой порядок очередности поступления потока инструкций на конвейер даст выигрыш только в том случае, если алгоритм определения наиболее вероятных ветвей исполнения программы реализуется достаточно эффективно. Если ветвь программы предсказана неверно, то процессору придется исполнять инструкции, принадлежащие как неправильно угаданной, так и истинной ветви, т.е. проделать в данном случае двойную работу. Однако современные алгоритмы предсказания переходов, как показывает практика работы на тестах SPEC, позволяет правильно предсказывать до 98-99 % ветвлений программы.
Обычно разделяют две основных группы методов предсказания ветвлений: статические и динамические.
Статическое предсказание ветвлений. В основе статистических методов предсказания ветвлений, относится предположение, что некоторые типы переходов осуществляются всегда, либо не осуществляются никогда. Основанием этого является, например, то, что программисты, как правило, проектируют программы таким образом, чтобы в большинстве случаев условных переходов ветвления бы не происходило. Созданное на основе такого предположения, устройство предсказания ветвления всегда выбирало бы ветвь программы, которая не требует передачи управления. И таким образом уменьшало бы число сбросов конвейера по причине неправильно выбранного предсказания.
Для переходов по переполнению, из этих же соображений, разумно предполагать, что перехода не будет никогда.
Примером статического предсказания переходов может также служить предположение, что любой прямой переход, т.е. переход на более старшие адреса, не выполняется, а переход обратный, т.е. на более младшие адреса – выполняется всегда. Вероятность справедливости такого утверждения довольно высока и основывается на том, что переход на более младшие адреса характерен при организации циклов, которые в программах встречаются довольно часто. Действительно, проведенные исследования показывают, что переходы назад обычно соответствуют циклу и выполняются в 90 % случаев, а переходы вперед большей частью соответствуют ветвлению и выполняются в 50 % случаев.
Следует отметить, что статическое предсказание ветвлений часто реализуется и на ступени компиляции, например, такие приемы как вынос ветвлений за пределы цикла, развертку итераций и т.п.
Однако в современных процессорах статические предсказания используются обычно только в том случае, когда невозможно использовать методы динамического предсказания. Например, когда команда перехода встречается первый раз и еще не накоплена статистика предыдущих переходов.
По мере того, как накапливается статистика результатов различных условных переходов (предыстория условных переходов) задействуется механизм динамического предсказания ветвлений, основанный как раз на анализе статистики результатов условных переходов, совершённых ранее.
Динамическое предсказание ветвлений. Динамические методы предсказания ветвлений основываются на анализе истории ветвлений. Блок динамического предсказания ветвлений на стадии выборки команды должен обеспечить следующие операции:
· Предсказать, является ли только что выбранная команда командой ветвления;
· Предсказать, будет ли переход или нет;
· Предсказать адрес перехода.
Для этого в блоке предсказания ветвлений предусматривается специальная ассоциативная память, называемая буфером адресов ветвлений (BTB – Branch Target Buffer) итаблица хранения истории предсказания ветвлений (BHT – Branch History Table). Например, в процессорах поколения P6, в памяти BTB сохраняется 512 адресов ранее выполненных переходов. (В современных моделях микропроцессоров объём этой памяти достигает до 4086 адресов и больше). BTB процессоров поколения P6 организована в виде 128 наборов, с ассоциативностью 4 (4-х входовая множественно-ассоциативная кэш-память). Для адресации используются младшие разряды адреса 16-байтового блока инструкций.
Структурная схема буфера адресов ветвлений (совместно c BHT), поясняющая принцип его работы, приведена на рис.XI.2.
Эта буферная память содержит адреса инструкций, на которые ранее производились переходы. Кроме этого BTB содержит четыре бита предыстории ветвления, которые определяют, выполнялся ли переход при четырех предыдущих выборках данной команды.
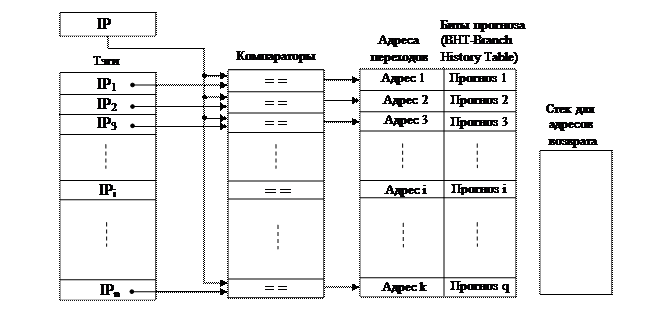
Рис XI.2 Структурная схема буфера адресов ветвлений
Основой блока предсказания ветвлений, как было уже отмечено, является буфер BTB, ассоциативная память, доступ к содержимому которой осуществляется по адресу очередной выбранной команды, сформированному в регистре IP (Instruction Pointer).
Тэгами этой ассоциативной памяти являются адреса команд переходов в выполняемых программах.
Как только поступила команда условного перехода, определенная по коду операции команды, адрес этой команды сравнивается с адресами (тэгами), находящимися в буферной памяти BTB. При отсутствии аналогичного адреса в буферной памяти, делается вывод о том, что ранее по этому адресу переходов не было и, следовательно, предсказывается отсутствие ветвления. Поэтому дальнейшая выборка и декодирование инструкций продолжается в порядке их следования. Если же указанный в инструкции адрес передачи управления в BTB обнаруживается, то производится анализ предыстории переходов, при котором определяется чаще всего реализуемое направление ветвления и выявляются чередующиеся переходы. Предыстория переходов кодируется в таблице BHT и дает информацию о вероятности реализации переходов на основе поведения при нескольких (в МП поколения P6 – четырёх) предыдущих выборках данной команды. В стандартной (двухбитной) схеме определяется четыре вероятности: 1) ветвь часто выполняется (strongly taken - 11); 2) ветвь выполняется (taken – 10); 3) ветвь не выполняется (not taken – 01); ветвь часто не выполняется (strongly not taken - 00). Адрес перехода определяется в соответствии с этой, зафиксированной в таблице, вероятности. После этого на конвейер передаётся команда по предсказанному адресу. При этом в блоке декодирования конвейера сохраняется декодированной и та команда, которая должна была выполняться, если бы предсказание перехода было бы отрицательным. Это делается для сокращения потерь времени на перезагрузку конвейера в случае, если бы предсказание оказалось бы ошибочным.
Поскольку передача управления на одну и ту же процедуру может осуществляться с разных точек программы, адрес возврата запоминается в специальном небольшом аппаратном стеке.
После окончания операций по выявлению истинности реализованного прогноза осуществляется коррекция содержания соответствующих областей памяти BTB. Новые адреса вводятся в BHT вместо адресов с нулевой вероятностью.
Заметим, что в микропроцессорах архитектуры IA-64 (например, семейства Itanium) используется прием одновременного вычисления нескольких веток программного кода. Встретив инструкцию условного перехода, процессор начинает просчитывать одновременно оба варианта исполнения программы, пока не станет ясно какой из этих путей должен быть реализован. Поскольку исполнительные устройства процессоров этой архитектуры обычно загружены далеко не полностью, то исполнение ветвей программы осуществляется практически с одинаковой скоростью. Поэтому даже при неправильном предсказании условного перехода, осуществляется лишь небольшое снижение производительности на этом небольшом участке программы.
Динамический анализ потока данных – концепция, которая заключается в том, что в режиме реального времени происходит анализ зависимости инструкций от исходных данных и значений, хранящихся в регистрах процессора. Этот анализ позволяет определить возможность исполнения инструкций не в том порядке, который определён программой, а в том, который позволяет наиболее эффективно загрузить исполнительные блоки процессора. Анализируется наличие данных для выполнения той или иной микрокоманды, либо из-за отсутствия их в данный момент в кэш L1 памяти данных, либо в связи с тем, что эти данные должны быть получены в результате исполнения последующей команды и т.д.
Таким образом, в результате динамического анализа потока данных, процессор определяет оптимальную последовательность обработки, что позволяет выполнять команды наиболее эффективным способом.
Спекулятивное (упреждающее) исполнение инструкций – способность процессора исполнять инструкции не в том порядке, который задан программой, а в том, который оптимален для наибольшей производительности исполнительного модуля процессора..
К упреждающему исполнению инструкций относится и одновремённое исполнение обоих ветвей, при выявлении команд условного перехода, однако, без записи полученного результата. После того, как определена правильная ветвь обработки, процессор записывает в память результат «правильной ветви» и отменяет остальные результаты. При этом, может происходить и предварительная загрузка данных (опережающее чтение, чтение по предположению), что часто даёт возможность избежать ситуации, когда процессору приходиться ожидать прихода данных, чтобы начать их обработку. Однако возвращать результаты исполнения инструкций он должен в той же последовательности, которая соответствует исходному потоку инструкций
В начале 2011 года фирма Intel объявила о 14 моделях новых процессоров микроархитектуры Sandy Bridge для настольных компьютеров, 15 – для мобильных и несколько серверных версий. Торговые марки Core i3, i5 и i7 сохранились, в качестве модельного ряда для массовых и бюджетных персональных компьютеров, соответствуя процессорам начального уровня, массового рынка и топ – моделей. Однако числа-модификаторы изменились.
Список объявленных моделей настольных версий микропроцессоров архитектуры Sandy Bridge приведен в таблице XI.1. Заметим, что первой двойкой в индексе модели Intel определяет принадлежность микропроцессора к поколению Intel Core II. (Точнее, первой цифрой 2 определяется принадлежность МП к микроархитектуре Sandy Bridge, поскольку МП, относящиеся к Ivy Bridge, имеют тройку первой цифрой в индексе, а МП микроархитектуры Haswell, первой цифрой в индексе характеризуются 4).
Существуют подтверждения стабильной работоспособности Core i7-2600k при разгоне до 5.0 ГГц с воздушным охлаждением.
Все приведенные модели микропроцессоров предназначены для установки в новые сокеты (разъёмы) типа LGA 1155 (LGA→ Land Grid Array – корпус интегральной схемы с матрицей контактных площадок; 1155 – число контактов корпуса).
В 4-ом квартале 2011 года фирма Intel на рынке появилось несколько топовых моделей настольных микропроцессоров с архитектурой Sandy Bridge модели Core i7 Extreme с 4, 6 и 8 ядрами (8, 12 и 16 потоками) с поддержкой памяти до 4-х каналов DDR3 – 1600, которые устанавливаются уже в сокеты LGA 2011.
В 2013 году Intel начала производить CPU по технологии 14 нм, а с 2015 года планирует производить CPU по технологии 10 нм. Причем, только на строительство предприятия по производству этих новых микросхем компанией Intel выделяется 15 миллиардов долларов. При этом, сообщается, что начиная с 2013 года, процессоры будут использоваться уже с модулями памяти стандарта DDR4, напряжение питания которых снижено до 1, 0…1, 2 В.
В заключение, в табл. XI.2, приводиться перечень типов МП микроархитектуры Haswell, которые корпорация Intel запланировала выпустить в продажу, начиная с 2013 года, и их основные характеристики.
Табл. XI.1
| Ядра (Потоки) | Процессор Марка, модель | ЦПУ (Тактовая частота, ГГц) | Графика (Тактовая частота, МГц) | Кэш L3 Мб. | TDP Вт | Шина | Поддержка памяти | Стоим. | |||
| Шт. | Турбо | Шт. | Турбо | ||||||||
| (8) | Core i7 | 2600k | 3, 4 | 3, 8 | DMI 2.0 | До 4-х каналов DDR3-1333 | $317 | ||||
| $294 | |||||||||||
| 2600s | 2, 8 | $306 | |||||||||
| (4) | Core i5 | 2500k | 3, 3 | 3, 7 | $216 | ||||||
| $205 | |||||||||||
| 2500s | 2, 7 | $216 | |||||||||
| 2500t | 2, 3 | 3, 3 | $184 | ||||||||
| 3, 1 | 3, 4 | $195 | |||||||||
| 2405s | 2, 5 | 3, 3 | $195 | ||||||||
| 2400s | $195 | ||||||||||
| 2, 8 | 3, 1 | $177 | |||||||||
| (4) | 2390t | 2, 7 | 3, 5 | $195 | |||||||
| Core i3 | 3, 3 | × | $138 | ||||||||
| $117 | |||||||||||
| $117 | |||||||||||
| 2100t | 2, 5 | $127 |
Примечание: Шт. – обозначение штатной тактовой частоты.
Значение индексов: k – процессоры со свободным множителем.
s - энергоэффективные процессоры.
t - высокоэнергоэффективные процессоры
Таблица XI.2
| Процессор | Ядер / потоков | TDP ватт | Номинальная тактовая частота, МГц | Максимальная частота для 4-х ядер, МГц | Кэш L3 Мбайт | GPU | Максимальная частота GPU МГц |
| Процессоры Core i7 на ядре Haswell | |||||||
| I7-4770k | 4/8 | HD Graphics 4600 | |||||
| I7-4770 | 4/8 | HD Graphics 4600 | |||||
| I7-4770r | 4/8 | HD Graphics 5200 | |||||
| I7-4770s | 4/4 | HD Graphics 4600 | |||||
| I7-4770t | 4/4 | HD Graphics 4600 | |||||
| I7-4765t | 4/4 | HD Graphics 4600 | |||||
| Процессоры Core i5 на ядре Haswell | |||||||
| I5-4670k | 4/4 | HD Graphics 4600 | |||||
| I5-4670s | 4/4 | HD Graphics 4600 | |||||
| I5-4670r | 4/4 | HD Graphics 5200 | |||||
| I5-4670t | 4/4 | HD Graphics 4600 | |||||
| I5-4570 | 4/4 | HD Graphics 4600 | |||||
| I5-4570s | 4/4 | HD Graphics 4600 | |||||
| I5-4670r | 4/4 | HD Graphics 5200 | |||||
| I5-4670t | 2/4 | HD Graphics 4600 | |||||
| I5-4430 | 4/4 | HD Graphics 4600 | |||||
| I5-4430s | 4/4 | HD Graphics 4600 | |||||
| Мобильные процессоры Core i7 на ядре Haswell | |||||||
| I7-4950hq | 4/8 | HD Graphics 5200 | |||||
| I7-4930mx | 4/8 | HD Graphics 4600 | |||||
| I7-4900mq | 4/8 | HD Graphics 4600 | |||||
| I7-4850hq | 4/8 | HD Graphics 5200 | |||||
| I7-4800mq | 4/8 | HD Graphics 4600 |
Сообщается также, что в рамках мобильного ряда процессоров Haswell будет несколько процессоров с ультранизким энергопотреблением, у которых потребляемая мощность не превышает 7 – 10 ватт. И в тоже время для создания особо производительных, эксклюзивных, систем будут выпускаться процессоры модели Haswell-EP, потребляющими мощность до 160 ватт.
|
|