Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Введение. Оптимизация и доработка цифрового фильтра масштабирования видеоданных
|
|
Оптимизация и доработка цифрового фильтра масштабирования видеоданных
Отчет по преддипломной практике
Студент гр. 437
Марченко В.В.
«___»___________ 201_ г.
Руководитель
Груздев Д.Н.- начальник отдела,
ведущий инженер-программист ЗАО «Элекард-Девайсез», г.Томск
«____»___________ 201_ г.
2012
Содержание
Введение. 4
1 ТЕХНОЛОГИЯ DIRECTSHOW... 7
1.1 Обзор технологии. 7
1.2 Фильтр видео масштабирования компании Элекард в контексте технологии DirectShow.. 10
2 МЕТОДЫ МАСШТАБИРОВАНИЯ ЦИФРОВЫХ ИЗОБРАЖЕНИЙ ПРИМЕНЯЕМЫЕ В ФИЛЬТРЕ КОМПАНИИ ЭЛЕКАРД.. 12
2.1 Метод Ланцоша. 12
3 СПОСОБЫ ОПТИМИЗАЦИИ ПРОГРАММЫ НА ЯЗЫКЕ СИ.. 14
3.1 Выбор оптимального алгоритма. 14
3.1.1 Вычислительная сложность. 14
3.1.2 Выбор команд. 15
3.1.3 Зависимость по данным и параллелизм команд. 16
3.2 Оптимизация имеющейся программной реализации алгоритма. 18
3.2.1 Оптимизация циклов. 18
3.2.2 Оптимизация проверки условий. 19
3.2.3 Оптимизация медленных команд. 22
3.2.4 Оптимизация работы с памятью.. 23
3.3 Технология SIMD.. 25
3.3.1 Общее описание. 25
3.3.2 Основные особенности применения технологии. 27
3.4 Использование многопоточности. 30
3.4.1 Общие принципы многопоточности. 30
3.4.2 Способы программной организации многопоточности. 31
3.4.3 Основные аспекты оптимизации многопоточности. 32
4 ПОСТАНОВКА ЗАДАЧИ.. 34
5 ХОД ВЫПОЛНЕНИЯ ПРАКТИКИ.. 35
ЗАКЛЮЧЕНИЕ. 37
Список использованных источников. 38
Введение
Со времен первого фильма братьев Люмьер видео начало постепенно внедряться в нашу повседневную жизнь и профессиональную деятельность. В связи с развитием компьютерной техники и информационных технологий способы передачи, хранения и воспроизведения видео также эволюционировали и перешли на цифровую основу.
За последние два десятилетия компьютеры в различных реализациях (персональные компьютеры, ноутбуки, планшетные компьютеры, смартфоны и т.д.) распространились настолько широко, что в 2011 году количество только пользователей Интернета в России составило более 70 миллионов (Лента новостей «РИА Новости». Технологии. https://www.ria.ru/technology/20111226/527204414.html). С увеличением числа пользователей компьютерных устройств и Интернета развитие получило и цифровое видео, и сегодня оно затрагивает уже огромное количество аспектов нашей жизни:
· системы наблюдения на объектах;
· кинематография;
· любительское видео;
· телевещание;
· видеоконференции;
· системы компьютерного зрения.
Исследование перспектив развития телекоммуникаций аналитиками компании CISCO [1] показали, то, что к 2013 году суммарный поток видеоданных составит примерно 90% пользовательского телекоммуникационного трафика, включая видеоконференции, мобильную телефонию и видеонаблюдение.
В настоящее время уже вошло в широкое потребление видео формата DVD, и постепенно развивается уже более высококачественное, так называемое HDVideo, то есть видеосигнал высокого разрешения.
Это является следствием технологического прогресса. Вычислительные мощности современных компьютеров уже достаточно велики, а скорость соединения через сеть Интернет достаточно высока. Однако даже нынешние компьютерные системы не позволяют работать непосредственно с несжатыми видеоданными повсеместно и необходимо применять кодирование видео. Это позволяет при одной и той же ширине канала связи передать видео более высокого качества, а так же уменьшить объем на жестком диске, требуемый для хранения видео.
Несмотря на имеющиеся достижения в скорости передачи и обработки видеоданных далеко не все пользователи интернета могут смотреть видео в высоком разрешении (1280x720 или больше) из-за недостаточной скорости передачи данных. Дисплеи многих устройств также еще не поддерживают высокое разрешение. В связи с этим встает вопрос о масштабировании разрешения исходной видеопоследовательности до требуемого и приемлемого каждым конкретным пользователем. Кроме того, эффективность в достижении лучшего качества изображения показало и предварительное сжатие видео перед кодированием [2].
Существует множество методов масштабирования цифровых изображений (кадров видеопоследовательности):
· метод ближайшего соседа;
· метод полиномов Эрмита;
· билинейная интерполяция;
· бикубическая интерполяция;
· интерполяция B-сплайнами;
· метод Митчела;
· интерполяция catmull-rom-сплайнами;
· метод Ланцоша.
Все эти методы реализованы в программах разных производителей.
В рамках производственной практики необходимо детально ознакомиться с DirectShow-фильтром масштабирования видео компании Элекард, проанализировать возможности для оптимизации фильтра и выполнить оптимизацию с целью повышения быстродействия данного фильтра.
1 ТЕХНОЛОГИЯ DIRECTSHOW
1.1 Обзор технологии
Фильтр масштабирования видео, разработанный компанией Элекард, реализован в рамках технологии DirectShow® компании Microsoft®. В связи с этим для более глубокого понимания работы фильтра, а также для дальнейшего тестирования и отладки фильтра на реальных данных необходимо ознакомиться с данной технологией.
Технология DirectShow® была разработана в 1997 году и с тех пор активно используется разработчиками мультимедиа приложений и компонентов. Данная технология предназначена для работы с потоковым мультимедиа – видео и звуком. Используя DirectShow, приложение может захватывать, фильтровать, и воспроизводить мультимедиа с различных устройств, при этом разработчику приложения нет необходимости вникать в детали реализации используемых аппаратных средств и их программных интерфейсов. DirectShow поддерживает многие современные форматы мультимедиа данных (Windows Media Video, Windows Media Audio, Digital Video, MPEG-4, MP3 и др). Кроме того, архитектура данной технологии такова, что мультимедиа данные какого-либо формата могут быть использованы при наличии всех необходимых фильтров, требуемых для выполнения конкретной задачи. Иначе говоря, технология не привязана к встроенным типам и может работать с любыми типами мультимедиа данных, для которых реализованы и зарегистрированы в системе необходимые фильтры.
Немного подробнее о фильтрах. В рамках технологии DirectShow фильтр – это программный компонент, который встраивается в поток мультимедиа данных и может выполнять определенные действия [3]:
· чтение данных из файла или получение данных непосредственно с их источника (микрофон, видеокамера и др.);
· кодирование, декодирование, обработка данных;
· передача данных в файл или на устройство вывода.
Все фильтры, в соответствии с их основными функциями, делятся на три вида [3]:
· фильтры-источники – передают данные в граф из какого-либо источника данных. Таковым источником может быть файл на каком-либо носителе, сеть, устройство захвата и т.п. Разные фильтры-источники оперируют различными типами источников данных;
· преобразующие фильтры – получают данные от источника, обрабатывают их и создают выходной поток данных. Примером трансформационных фильтров могут служить декодер, энкодер, фильтр масштабирования видео, фильтр конверсии цветового пространства и др.;
· фильтры вывода – располагаются в конце цепи графа. Они получают данные и представляют их пользователю. Пример – фильтр вывода изображения на экран (Video Renderer), фильтр воспроизведения звука (Default DirectSound Device), и фильтр записи данных в файл;
· разделяющие фильтры или демультиплексоры – разделяют единый входной поток на два и более потока. Например, разделение мультимедиа потока, считанного из файла, на поток видео- и аудиоданных;
· мультиплексор – данный фильтр предназначен для соединения нескольких различных потоков единый, например раздельные потоки видео- и аудиоданных в единый файл в соответствии с форматом данных.
Каждый фильтр имеет хотя бы одну точку соединения. Эта точка называется пином. У фильтра ввода такая точка одна и предназначена для передачи считанных данных дальше по цепочке фильтров. У фильтра трансформации таких точек обычно два: для приема необработанных данных и для передачи обработанных данных. У фильтра вывода такая точка одна – для считывания обработанных данных, предназначенных для записи в файл или воспроизведения. Каждый пин характеризуется форматами данных, которые он может принимать, либо выдавать в зависимости от того входной это пин или же выходной.
Кроме того, фильтры могут иметь свойства, позволяющие непосредственно пользователю или прикладной программе управлять ходом их работы. К примеру, основное свойство фильтра масштабирования видео – требуемое разрешение видео. Свойством фильтра вывода может быть путь к файлу, в который необходимо записать данные.
Фильтр может находиться в одном из трех состояний: активен, остановлен и в состоянии паузы [3]. В активном состоянии фильтр в зависимости от назначения выполняет свою непосредственную задачу: считывает данные, обрабатывает их требуемым образом, воспроизводит и т.д. В состоянии остановки данные не обрабатываются. Состояние паузы реализует временную остановку работы фильтра с возможностью последующего возобновления с точки останова.
Цепочка фильтров, соединенных в соответствии с форматами на их пинах, образует граф. Граф является единым управляемым объектом. Для управления графом в DirectShow реализован менеджер графа фильтров, реализующий следующие функции [3]:
· координация смены состояний фильтров;
· установка ссылочных часов;
· передача событий приложению;
· обеспечение методов построения графа приложением.
Далее рассмотрим данные функции несколько подробнее.
Смена состояний фильтров производится в конкретном порядке. Чтобы избавить разработчиков прикладных приложений от необходимости контролировать порядок перевода фильтров в нужное состояние, эта задача возложена на менеджер графа фильтров. Приложение должно только направить ему одну единственную команду с запросом на перевод графа из текущего состояния в требуемое.
Фильтры в графе используют одни и те же часы, именуемые ссылочными часами. Они отвечают за синхронизацию потоков данных. Простой пример – контроль времени воспроизведения кадров на экране. В фильтр вывода поступает кадр с указанием времени, когда он должен быть воспроизведен. Фильтр вывода должен сравнить время, заданное на кадре, и время на ссылочных часах и если время воспроизведения уже прошло или только наступило – вывести кадр на дисплей, иначе – поставить кадр в очередь до наступления времени его воспроизведения.
Менеджер графа фильтров предоставляет прикладному приложению возможность добавлять фильтры в граф, соединять их между собой, разъединять. Для уведомления о событиях при работе графа менеджер использует специальную очередь событий.
1.2 Фильтр видео масштабирования компании Элекард в контексте технологии DirectShow
С точки зрения рассмотренной выше технологии DirectShow фильтр видео масштабирования представляет собой фильтр трансформации с двумя пинами. Входной пин принимает несжатые видеоданные для масштабирования. Выходной пин выдает отмасштабированные несжатые видеоданные. Для большей совместимости данного фильтра с другими фильтрами в нем реализован конвертер формата несжатого видео, что позволяет соединяться со многими другими фильтрами, выдающими или принимающими несжатое видео разных форматов.
Основным свойством данного фильтра является выходное разрешение видео. Предусмотрен выбор пользователем одного из следующих методов масштабирования:
· быстрый (sharp);
· аккуратный (precise);
· метод Ланцоша (Lanczos) для шести точек.
Также есть возможность указания формата потока (прогрессивный, чересстрочный) в случае ошибки в метаинформации буфера кадра, изменения соотношения сторон видео с использованием различных методов (обрезание сторон кадра, растяжение, растяжение с панорамным эффектом), а также возможность вырезания части исходного кадра, необходимой для масштабирования.
Таким образом, данный фильтр реализует все необходимые для него функции и, кроме того, предоставляет дополнительный функционал для более удобной, полноценной работы с ним без реализации дополнительных фильтров.
2 МЕТОДЫ МАСШТАБИРОВАНИЯ ЦИФРОВЫХ ИЗОБРАЖЕНИЙ, ПРИМЕНЯЕМЫЕ В ФИЛЬТРЕ КОМПАНИИ ЭЛЕКАРД
В фильтре масштабирования видео компании Элекард применяются модификации метода Ланцоша для двух, четырех и шести точек.
2.1 Метод Ланцоша
Метод Ланцоша (третьего порядка) относится к числу методов, позволяющих масштабировать цифровые изображения с наилучшим качеством. В настоящее время он применяется во многих популярных графических программах, например ACDSee®, Adobe Photoshop®, GIMP и другие.
Данный метод использует нормированную функцию кардинального синуса sinc(x). В линейном случае формула преобразования по методу Ланцоша имеет вид [4]:
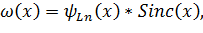
Функция 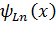 имеет вид [4]:
имеет вид [4]:
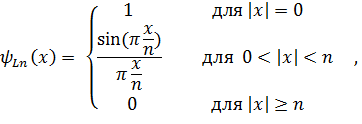
где 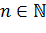 обозначает границу фильтра.
обозначает границу фильтра.
Для фильтров Ланцоша порядка 2 и 3, наиболее часто используемых в компьютерной графике, получим функции следующего вида:
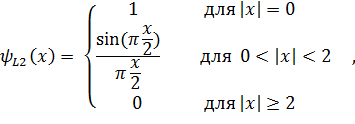
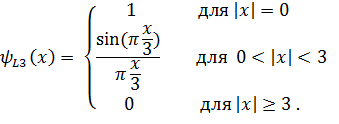
Таким образом, полное выражение, описывающее фильтр Ланцоша порядка 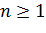 , принимает вид:
, принимает вид:
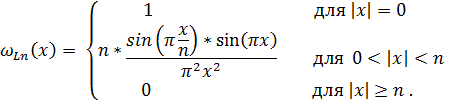
Для двумерного случая масштабирование методом Ланцоша может быть разделено на две стадии: сначала производится масштабирование каждой строки по горизонтали, а затем производится масштабирование каждого столбца пикселей с измененным горизонтальным масштабом по вертикали.
Двумерный фильтр Ланцоша в общем виде можно описать выражением [4]:
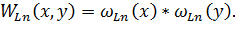
Точку с координатами (x0, y0) интерполированного изображения можно получить, воспользовавшись следующим выражением [4]:

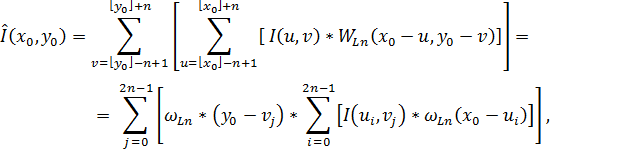
где 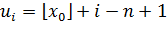 и
и 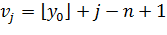 .
.
Интерполяция производится по квадратному участку изображения размером 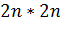 пикселей.
пикселей.
3 СПОСОБЫ ОПТИМИЗАЦИИ ПРОГРАММЫ НА ЯЗЫКЕ СИ
Существует множество способов оптимизировать программу, написанную на языке Си. К основным методам, дающим наибольший прирост скорости, можно отнести:
· выбор оптимального алгоритма;
· оптимизация имеющейся программной реализации алгоритма;
· применение технологии SIMD;
· использование многопоточности.
Каждый из этих способов дает определенный прирост производительности, и только применение их в совокупности позволяет получить максимальное ускорение. Рассмотрим каждый из методов более подробно.
3.1 Выбор оптимального алгоритма
Выбор подходящего алгоритма является одним из важнейших факторов, определяющих скорость и качество работы будущей программы. Идеальный алгоритм решает задачу быстро и качественно, однако, как правило, разработчики программ вынуждены искать компромисс между качеством и скоростью работы алгоритма.
Выбор наилучшего алгоритма для решения конкретной задачи - непростое дело. Необходимо учесть вычислительную сложность, требования к памяти, типы данных, с которыми работает алгоритм; типы функций, использующихся в алгоритме; зависимости по данным, надежность – эти и другие факторы определяют степень пригодности алгоритма для решения поставленной задачи.
3.1.1 Вычислительная сложность
Производительность алгоритма может быть оценена через О-нотацию. Для примера сравним сложность и быстродействие алгоритмов сортировки.
Пузырьковая сортировка – один из простейших в реализации и в то же время самых медленных алгоритмов сортировки. Его вычислительная сложность равна O (n2) [5]. Это значит, что при удвоении числа сортируемых элементов, то время выполнения сортировки увеличится приблизительно в четыре раза.
Алгоритм быстрой сортировки имеет сложность равную O (n * log n) [5]. Для более наглядного сравнения рассмотрим задачу сортировки 1000 элементов. При использовании пузырьковой сортировки программе понадобится выполнить около 1000000 операций, в то время как применяя быструю сортировку – всего 9965 операций. Таким образом, использование алгоритма с меньшей вычислительной сложностью в данном случае дает стократное уменьшение числа выполняемых операций. Учитывая время выполнения операций в каждом из алгоритмов, можно приблизительно сравнить оценки времени решения поставленной задачи данными алгоритмами. Подробнее это рассмотрим далее.
3.1.2 Выбор команд
Оценка времени работы алгоритма, основанная на предположении о равнозначности времени выполнения команд, может дать ошибку, и порой весьма значительную. К примеру, команда целочисленного умножения имеет латентность равную 10 тактам, а пропускную способность равную 1 такту [6]. В то же время латентность и пропускная способность команды целочисленного деления для того же процессора равны 66-80 и 30 тактам соответственно [6]. Дадим определения упомянутым временным характеристикам команд процессора.
Латентность – это число тактов, необходимых для завершения одной команды с момента готовности входных данных команды (выборки их из памяти) и начала ее выполнения [5].
Пропускная способность команды – это число тактов ожидания, которое требуется процессору перед запуском на выполнение той же команды. Значение пропускной способности всегда меньше или равно по величине латентности этой команды. Причина разницы между числом тактов пропускной способности и числом тактов латентности является конвейерная обработка команд [5].
Учет латентности и пропускной способности команд может оказать существенное влияние на выбор алгоритма или на программную реализацию выбранного алгоритма, так как иногда одно и то же математическое действие можно выполнить командами с разными временными характеристиками (далее рассмотри это более подробно). К примеру, если в одном алгоритме программе необходимо выполнить 5 целочисленных умножений, а во втором алгоритме – всего лишь 1 деление, то, несмотря на кажущееся преимущество второго алгоритма, программная реализация первого алгоритма будет обладать более высоким быстродействием.
3.1.3 Зависимость по данным и параллелизм команд
Рассмотрим еще одну характеристику, оказывающую влияние на быстродействие алгоритма – зависимость по данным. Процессор Intel Pentium® 4 способен выполнить шесть команд за один такт. Однако на практике такой эффективности достичь не удается из-за зависимости команд по данным. Здесь необходимо вспомнить определение пропускной способности процессора для конкретной команды – число тактов после начала выполнения данной команды, необходимое для начала выполнения следующей такой же команды [5].
Рассмотрим эту ситуацию на примере. Пусть нам необходимо произвести следующие действия:
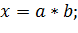
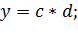
 Пусть для нашего примера латентность умножения составляет три такта, а пропускная способность – один такт. Все переменные целочисленные. Как мы видим, все команды используют разные аргументы, то есть они независимы по данным. Это позволяет за первый такт начать выполнение первой команды, за второй такт продолжить выполнение первой и приступить к выполнению второй, за третий такт продолжить выполнение предыдущих двух и начать выполнение третьей. Таким образом, все команды будут выполнены не за 9 тактов (3 такта латентности * 3 команды), а всего за 5 тактов, что почти в два раза быстрее.
Пусть для нашего примера латентность умножения составляет три такта, а пропускная способность – один такт. Все переменные целочисленные. Как мы видим, все команды используют разные аргументы, то есть они независимы по данным. Это позволяет за первый такт начать выполнение первой команды, за второй такт продолжить выполнение первой и приступить к выполнению второй, за третий такт продолжить выполнение предыдущих двух и начать выполнение третьей. Таким образом, все команды будут выполнены не за 9 тактов (3 такта латентности * 3 команды), а всего за 5 тактов, что почти в два раза быстрее.
Теперь рассмотрим другую ситуацию, когда вторая команда зависит по данным от первой, а первая и третья команды не зависимы по данным:
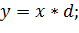
Выполнение данных команд в такой последовательности окажется не самым производительным и займет 7 тактов, так как второй команде придется ждать полного завершения первой команды перед началом своего выполнения. Теперь попробуем изменить порядок операций:
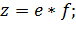
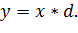
Такая последовательность дает нам максимально быстрое решение задачи, которое займет 6 тактов процессора.
Рассмотрим более сложный пример. Пусть нам необходимо найти сумму тысячи элементов массива. Запишем это следующим образом [5]:
a = 0;
for (x = 0; x < 1000; x++)
a += buffer[x];
В данном примере мы можем начать прибавление к переменной a следующего элемента массива и тут же приступить к инкременту итератора x. В этих операциях нет зависимости по данным. Но приступить к прибавлению следующего элемента массива мы уже не сможем до окончания инкремента итератора x. Эту зависимость можно устранить следующим образом [5]:
a = b = c = d = 0;
for (x = 0; x < 1000; x+=4)
{
a += buffer[x];
b += buffer[x+1];
c += buffer[x+2];
d += buffer[x+3];
}
a += b + c + d;
Помимо уменьшения зависимостей по данным мы, таким образом, уменьшили и число увеличений значения итерационной переменной x, а так же число сравнений ее значения с количеством складываемых элементов массива.
3.2 Оптимизация имеющейся программной реализации алгоритма
Следующим шагом после выбора оптимального алгоритма является оптимальная его реализация на языке программирования. В данном случае рассмотрим язык высокого уровня Си, а также Ассемблер, но без применения наборов векторных команд процессора.
3.2.1 Оптимизация циклов
На первом шаге оптимизации необходимо устранить излишние вычисления, то есть такие команды, которые выполняются неоднократно без необходимости их повторного выполнения. Данную ситуацию можно показать на простом примере:
a = 3.14;
for(i=0; i< 1000; i++)
buffer[i] = cos(a);
В данном случае результат вычислений функции косинуса будет одинаков для всех элементов массива buffer. Подобного рода вычисления можно устранить переносом вычисления функции косинуса перед циклом, что может дать существенный прирост производительности, так как вычисление тригонометрических функций – затратные по времени операции. При вычислении в цикле значений косинуса от периодически повторяющихся аргументов также целесообразно будет перенести вычисление данных функций перед циклом, а результаты занести в массив. Таким же образом следует тщательно отследить все действия, выполняемые в цикле, будь то дорогостоящие арифметические операции или проверка условий, так как цикл увеличивает затраты на выполнение данных операций кратно количеству итераций.
Еще одно часто встречающееся преобразование цикла – развертывание. Под развертыванием цикла понимается приведение его к такому виду, когда одна итерация модифицированного цикла эквивалентна по данным нескольким итерациям неразвернутого цикла. Как уже упоминалось ранее, такая оптимизация дает возможность уменьшить зависимость по данным. Однако при сильном развертывании цикла можно столкнуться с тем, что с определенного момента рост производительности прекратится вновь из-за зависимости по данным. Можно сформулировать общее правило по развертыванию циклов: полезно такое развертывание циклов, которое ведет к меньшему количеству по данным или к более удачному упорядочиванию команд [5].
3.2.2 Оптимизация проверки условий
В качестве следующего аспекта оптимизации программного кода рассмотрим проверку условий и выполнение условных переходов. В современных процессорах присутствует механизм предсказания переходов. К настоящему времени процессор может достаточно точно предсказать результат многих переходов, однако все равно остаются ситуации, когда процессор прогнозирует неверный результат перехода, и производительность падает [5]. К примеру, если в условии есть переменная, принимающая случайные значения, или в качестве аргумента условного перехода присутствует функция, то вероятность ошибки предсказания возрастает.
Может показаться, что в таких ситуациях было бы выгодно исключить механизм предсказания переходов, но это невозможно и нежелательно. Для пояснения данного положения необходимо еще раз вспомнить о конвейеризации в процессоре. Без предсказания переходов процессору пришлось бы на каждом шаге останавливаться и ждать окончания выполнения перехода в конвейере. Возможность внести на конвейер команды, следующие за переходом, и приступить к их выполнению отсутствовала бы. В то же время потеря производительности при отключенном механизме предсказания переходов и при восстановлении после неверно предсказанного перехода примерно одинаковы [5].
Еще одним фактором, препятствующим росту производительности, является использование сложных условий. Рассмотрим пример [5]:
if (t1 == 0 & & t2 == 0 & & t3 == 0)
В данном случае должно быть выполнено три сравнения переменных с нулем. Предположим, что переменные t1, t2 и t3 уже занесены в регистры ax, bx и cx соответственно. Тогда в реализации на ассемблере может выглядеть следующим образом:
cmp ax, 0
jne skip
cmp bx, 0
jne skip
cmp cx, 0
jne skip
< действия при выполнении всех трех условий >
skip:
< действия при невыполнении хотя бы одного из условий >
Подобные ситуации сложно предсказуемы, однако если бы можно было бы обойтись вместо трех проверок одной, то можно было бы получить лучшую предсказуемость. Для этого воспользуемся операцией побитового сложения [5]:
if ((t1 | t2 | t3) == 0)
Данный переход по своей логике эквивалентен предыдущему, однако требует уже гораздо меньше проверок условий и вообще инструкций, с учетом того, что значения латентности и пропускной способности операции побитового сложения малы и составляют 1 и 0, 5 такта соответственно [6]. Как и в предыдущем примере, предполагается расположение переменных в регистрах. Реализация данного случая на ассемблере может выглядеть следующим образом:
or ax, bx
or ax, cx
cmp ax, 0
jne skip
< действия при выполнении всех трех условий >
skip:
< действия при невыполнении хотя бы одного из условий >.
Применение данной оптимизации перехода на языке Си позволила сократить время работы тестовой программы до двух раз [5].
К сожалению, предусмотреть заранее плохую предсказуемость условных переходов бывает затруднительно. Облегчить данную задачу можно применением специальных программ – профилировщиков, позволяющих оценить время, затраченное на выполнение тех или иных процедур, процент ошибок предсказания переходов и другие параметры производительности. Данные программы предоставляются компаниями-производителями процессоров AMD® (CodeAnalyst™) и Intel® (VTune™ Performance Analyzer). Однако даже в этом случае оптимизация всех переходов, где выявлены ошибки предсказания, окажется затратным по времени мероприятием. Целесообразно оптимизировать лишь наиболее плохо предсказуемые переходы, то есть чей процент успешных предсказаний ниже 95% [5].
3.2.3 Оптимизация медленных команд
Иногда горячая точка оказывается просто в медленном фрагменте кода, или даже в единственной команде. Однако часто причиной потери производительности является не сам факт большой латентности той или иной команды, а нерациональное применение команд. Некоторые команды слишком универсальны, и для конкретной цели возможно применить более оптимальную по быстродействию команду или последовательность команд. Рассмотрим пример, когда нам необходимо сравнить длину строки с заданной константой. Один из вариантов реализации такой задачи:
if (strlen(string) == constant)
Это очевидная реализация, однако, она не оптимальна. Необходимо вспомнить, что строка – это массив символов, каждый из которых в ASCII-кодировке занимает один байт, и признаком окончания такой строки является байт с нулевым значением. С учетом этой информации можно решить нашу задачу без вычисления реальной длины строки:
if (string[constant] == 0).
Такая реализация не потребует сравнения каждого байта строки с нулем до нахождения совпадения, а лишь проверит, является ли концом строки интересующий нас символ.
Еще один распространенный пример неоптимальных вычислений - умножение, деление и проверка кратности числам, равным степени двойки. Например, чтобы умножить целое число на 8, достаточно просто выполнить поразрядный сдвиг влево на три разряда. А чтобы получить ближайшее снизу число, кратное 16, достаточно выполнить следующий код:
C = 123;
Num = c & ~15;
В результате переменная Num получит значение 112. Данная реализация не требует взятия остатка от деления заданной константы на 16 и последующего вычитания его из этой константы.
Однако бывают ситуации, когда необходимо использовать медленную команду, и замена ее на более быстродействующие команды невозможна. В таком случае необходимо по возможности сопроводить ее работу командами без зависимостей по данным, которые могли бы выполняться в это же время.
3.2.4 Оптимизация работы с памятью
Оперативная память является основным хранилищем данных для большинства программ. От того, насколько быстро из памяти будут считаны для данные для дальнейшей обработки, а также записаны результаты вычислений зависит быстродействие программы в целом. Быстродействие современной динамической памяти существенно возросло, однако взаимодействие с ней все же проигрывает по скорости работе со статической памятью или регистрами процессора. Так, например, в 2008 году время доступа к динамической памяти составляло примерно 50-70 наносекунд при цене 20-75 долларов за гигабайт объема. Для статической памяти же скорость доступа на порядок выше и составляет 0, 5-2, 5 наносекунды при цене 2000-5000 долларов за гигабайт [7].
В связи с этим в компьютерах создана иерархия памяти, согласно которой самая дорогая и быстродействующая память используется в регистрах и кэше процессора, а более медленная, но объемная применяется в качестве оперативной памяти.
Кэш представляет собой дополнительный уровень иерархии памяти между процессором и оперативной памятью [7]. Он применяется для сокращения латентности оперативной памяти. В современных процессорах существует 3 уровня кэша. Кэш первого уровня меньше всех по объему, но самый быстрый. Кэш второго уровня больше первого, но и медленнее. И, наконец, самый медленный и одновременно самый большой – это кэш третьего уровня.
Когда приложение обращается к области памяти для чтения или записи данных, процессор, прежде всего, ищет данные в кэше. Если данные найдены, то обращение идет к данным в кэше, а не в основной оперативной памяти. В противном случае возникнет промах кэша, и произойдет обращение к данным в основной памяти с занесением их в кэш.
Кэш работает по принципу пространственной и временной локальности [5]. Пространственная локальность проявляется тогда, когда совместно используются области памяти, находящиеся друг с другом. Обычно программа обращается к смежным областям памяти: например, если произошло обращение к байту с номером x, то скорее всего далее программа обратится к байту с номером x+1 и так далее. Поэтому при промахе кэша, в него заносится не один байт, требуемый из основной памяти в текущем обращении, а линейка байтов, равная размеру строки кэша [5]. Такой способ работы с кэшем является оптимальным, так как однократная передача данных для линейки кэша происходит быстрее, чем побайтовая передача.
Кроме того, предполагается, что приложения обращаются периодически к одним и тем же областям данных. Это называется принципом временной локальности. При обращении программы к памяти, когда кэш уже полностью заполнен, а требуемые данные в нем отсутствуют, должна произойти замена одной из строк кэша и, в соответствии с принципом временной локальности, для замены будет выбрана область, к которой дольше других не производилось обращений.
Обычно предварительная выборка данных в кэш производится аппаратно, однако на уровне команд процессора есть возможность запросить выборку некоторой области программно. Данная команда называется prefetchh [8]. У нее существует четыре подвида, позволяющих выбирать область данных в кэш различного уровня или же непосредственного в буфер прямого доступа к памяти.
В случае записи данных существует возможность так же миновать шаг записи в кэш. Это обеспечивается командами процессора movntdq, movntdqa и другими [8]. При этом запись происходит в специальные буферы WC-памяти, или памятью с объединением записи (Write combining, WC) [5]. Этот тип памяти используется в случаях, когда очередность и срочность записи не важны, а важна производительность. Однако, при использовании команд некэшируемой записи, следует убедиться, что записываемые данные не будут вскоре использоваться, так как они удаляются из кэша.
Механизм кэширования накладывает и еще одну особенность на расположение данных в памяти – адреса доступа к данным должны быть выровнены [5]. Если некая части переменной находятся на двух разных строках кэша, то необходимо будет считать обе и объединить части переменной воедино.
Кроме того, выравнивания адресов памяти требуют и SIMD-команды, в противном случае возникнет необработанное исключение.
3.3 Технология SIMD
3.3.1 Общее описание
Данная технология предоставляет возможность выполнить одно действие над несколькими единицами однотипных данных, используя всего одну команду Ассемблера.
Начало реализации данного направления было положено с появлением технологии MMX™ [5]. В рамках данной технологии регистры процессора были дополнены восемью 64-разрядных регистров и новыми командами для работы с ними. В связи с этим появилось понятие упакованного и скалярного режимов. В упакованном режиме операция применяется к отдельным элементам данных, упакованным в операндах источника и приемника. В скалярном же режиме операция применяется только к младшему элементу данных источника и приемника [5].
С появлением процессоров Pentium III появилось развитие технологии SIMD в виде SSE-команд. Затем были добавлены наборы команд SSE2, SSE3 и SSE4. В набор регистров процессора были добавлены 128-битные регистры, позволяющие обрабатывать данные как целого, так и вещественного типов в упакованном и скалярном режимах.
В настоящее время, в зависимости от компилятора, существует до четырех способов применения данных команд [5]:
· библиотеки классов С++;
· внутренние команды компилятора;
· ассемблер (подставляемый и непосредственный);
· автоматическая векторизация.
Наиболее интересными с точки зрения программиста представляются два последних способа.
Использование автоматической векторизации существенно облегчает разработку прикладных программ. Исходный код программы, написанной на языке Си, не нужно изменять, что сохраняет простоту отладки и понимания кода. Ответственность за использование всей полноты преимуществ технологии SIMD и всех ее нововведений возлагается на компилятор. Очевидно, такой подход усложняет разработку компилятора, и он оказывается не всегда способным выделить SIMD-команды из последовательного кода [5].
Применение непосредственного ассемблера позволяет использовать весь набор команд процессора. Кроме того, существую компиляторы ассемблера (например, NASM), позволяющие создавать кроссплатформенный код (в отличие от подстановочного ассемблера). Функции, написанные на ассемблере, легко интегрируются в программу на языке Си.
Стоит отметить, что процедуру на ассемблере труднее отладить и понять. Еще одним недостатком является и то, что с появлением новых наборов команд, код придется частично или полностью переписывать с целью получения преимуществ нововведений. Учитывая эти недостатки, непосредственное применение ассемблера оправдано только в приложениях, где требования к производительности максимально высоки и автоматическая векторизация не оказывается достаточно эффективной.
3.3.2 Основные особенности применения технологии
Технология SIMD предусматривает несколько аспектов, призванных обеспечить максимально эффективное ее использование.
Прежде всего, это выравнивание данных. Для семейства команд, начиная с SSE, данные должны быть выровнены на 16-байтную границу [5]. Это существенно повышает скорость выполнения команд. Существуют и эквивалентные команды, позволяющие работать с данными без предварительного выравнивания, однако обычно их латентность существенно больше. Для объявления выровненных данных в некоторых компиляторах (в частности, MS VC) предусмотрена специальная директива: __declspec (align (база, смещение)). Например, объявление выровненного на 16-байтную границу массива целых чисел можно представить следующим образом:
__declspec(align(16)) int a[N];
Для независимости от компилятора можно обеспечить выравнивание простыми средствами языка Си. Например, память под 128 целочисленных элементов можно выделить следующим образом [5]:
Int *pBuf, *pBufOrig;
pBufOrig = (int *) malloc (128*sizeof(int) + 15);
pBuf = (int*)(((int)pBufOrig + 15) & ~0x0f);
В данном примере сначала выделяется память под массив pBufOrig без выравнивания. Затем значение указателя на выделенную область памяти выравнивается и заносится в новый указатель. При этом следует учитывать, что при окончании использования массива необходимо освобождать память для указателя pBufOrig, в противном случае произойдет утечка памяти.
Следующим важным аспектом является организация данных, позволяющая максимально использовать упакованный режим в технологии SIMD.
Рассмотрим задачу скалярного перемножения восьми векторов, каждый из которых состоит из четырех вещественных чисел одинарной точности:
__declspec(align(16)) float A[4], B[4], C[4], D[4], W[4], X[4], Y[4], Z[4];
__declspec(align(16)) float Res[4];
for(int i=0; i< 4; i++)
{
Res[0] += A[i]*W[i];
Res[1] += B[i]*X[i];
Res[2] += C[i]*Y[i];
Res[3] += D[i]*Z[i];
}
В данном примере нам потребуется выполнить 16 операций умножения, и 16 операций сложения.
В технологии SIMD можно легко поместить сразу один вектор в регистр, а также перемножить два вектора между собой, но возникает сложность при получении суммы вычисленных произведений. Для устранения этой проблемы, данные лучше реорганизовать так, чтобы вектор A состоял только из элементов A [0], B [0], C [0], D [0], вектор B состоял только из элементов A [1], B [1], C [1], D [1], вектор C состоял только из элементов A [2], B [2], C [2], D [2] и, наконец, вектор D должен состоять из элементов A [3], B [3], C [3], D [3]. Аналогичным же образом нужно переупорядочить и элементы векторов W, X, Y, Z. В результате преобразований получим новые векторы AM, BM, CM, DM, WM, XM, YM и ZM. Теперь мы сможем за 4 операции умножения и 4 операции сложения получить искомый результат. Приведем пример реализации на Ассемблере:
movaps xmm0, AM
movaps xmm1, WM
mulps xmm0, xmm1
movaps xmm1, BM
movaps xmm2, XM
mulps xmm1, xmm2
movaps xmm2, CM
addps xmm0, xmm1
movaps xmm1, YM
mulps xmm2, xmm1
movaps xmm1, DM
addps xmm0, xmm2
movaps xmm2, ZM
mulps xmm1, xmm2
addps xmm0, xmm1
movaps Res, xmm0
В итоге в массиве Res мы получили результат произведения каждого из исходных векторов. В данном фрагменте мы постарались обойтись минимальным количеством регистров, а также учесть пропускную способность команд и чередовать различные команды, независимые по данным.
Помимо правильной организации данных, необходимо еще и правильно выбрать тип данных. К примеру, если бы мы в предыдущем примере работали с вещественными числами двойной точности, то таким же количеством команд мы бы смогли обработать только два вектора из двух элементов. Таким образом, выбор минимального по размеру типа данных (который удовлетворяет условиям и ограничениям задачи) обеспечивает максимально возможный параллелизм [5].
Может возникнуть такая ситуация, когда переход на тип данных меньшего размера снижает качество (точность) вычислений. При этом степень ухудшения качества бывает сложно оценить теоретически. В этом случае может быть целесообразной реализация двух вариантов процедуры и выбор оптимальной по критериям «параллелизм» и «качество результата» уже в результате непосредственного тестирования.
В заключение необходимо отметить, что не всегда применение технологии SIMD удается применить максимально эффективно, как это получилось в нашем примере. Иногда поставленная задача не допускает возможности реорганизации структуры данных, а также изменения их типов без серьезных изменений в алгоритме. Некоторые алгоритмы в принципе плохо поддаются распараллеливанию. Все это, а также пренебрежение освещенными ранее способами оптимизации снижает рост производительности.
3.4 Использование многопоточности
3.4.1 Общие принципы многопоточности
В настоящее время в процессорах компании Intel® применяется несколько типов организации параллельного выполнения задач [5]:
· технология SIMD (см. выше);
· гиперпоточность;
· многоядерность.
Технология гиперпоточности позволяет одному ядру процессора одновременно выполнять команды двух программных потоков [5]. В многоядерных процессорах устанавливается несколько исполнительных ядер, что также дает возможность выполнять команды различных задач параллельно [5].
Многие современные процессоры поддерживают все три упомянутых выше способа организации параллелизма. Однако, как и в случае с технологией SIMD, использование преимуществ гиперпоточности и многоядерности требует особого подхода при написании программного обеспечения.
Параллелизм на уровне команд становится возможным только в том случае, если можно выделить независимые участки программы. Обычно, работа по выделению таких участков кода ложится на программиста. При этом вновь может потребоваться реорганизация данных для обеспечения независимости различных потоков. В совокупности процесс создания многопоточной программы (алгоритма) из однопоточной называется декомпозицией по заданиям и данным [5].
Параллелизм на уровне заданий часто встречается в пользовательских приложениях для настольных компьютеров. К примеру, во время работы в текстовом редакторе параллельно осуществляется проверка орфографии, резервное сохранение документа и тому подобное. Могут выполняться и одинаковые задания, но над разными данными. К примеру, сервер вещания видеосигнала может передавать клиентам один и тот же видеоряд, но в разном разрешении.
Параллелизм на уровне данных применяется в программах, обрабатывающих большие массивы однородных данных. К примеру, конвертация видеокадра из одного цветового пространства в другое может быть представлена в виде конвертации отдельных частей изображения, разделенного по вертикали. Соединение результатов конвертации для каждой параллельной ветви в данном примере дает полный видеокадр в измененном цветовом пространстве.
При разработке параллельных программ необходимо стремиться к равномерной загруженности каждого параллельного потока [5]. Неравномерность может быть следствием плохой декомпозиции задачи, недостаточного устранения зависимостей между потоками, либо недостатками конкретной реализации многопоточности, приводящей к большим накладным расходам.
3.4.2 Способы программной организации многопоточности
Некоторые компиляторы способны сами обеспечить параллелизм в результате анализа кода. Однако часто компилятору не удается извлечь непосредственно из кода всю информацию для правильной организации многопоточности. Поэтому чаще всего используется многопоточный прикладной программный интерфейс [5].
В настоящее время существует две категории многопоточных прикладных программных интерфейсов (МППИ) [5]:
· высокоуровневые, например, OpenMP;
· низкоуровневые, например, POSIX- или Win32-потоки.
При помощи высокоуровневых МППИ разработчик указывает компилятору при помощи специальных директив, всю необходимую информацию: какие участки следует выполнять параллельно, какие переменные при этом должны быть независимыми и тому подобное. Такой подход более удобен для прикладного программиста, однако цена этого – утрата некоторых средств контроля и, возможно, некоторой доли производительности [5]. Поточные библиотеки же предоставляют разработчику полный контроль над управлением и синхронизацией потоков, что одновременно приводит к необходимости ручной проработки всех деталей реализации многопоточности [5]. Можно провести аналогию многопоточных программных интерфейсов и языков программирования: при использовании ассемблера, вместо высокоуровневого языка, вы получаете больший контроль над реализацией, прирост производительности, но вместе с тем возрастает и сложность разработки такой программы.
3.4.3 Основные аспекты оптимизации многопоточности
При организации многопоточности в уже имеющемся однопоточном приложении необходимо, прежде всего, выделить наиболее затратные по вычислениям участки кода. Именно их стоит подвергать разбиению на потоки.
Если же программная система еще находится в стадии проектирования, то стоит обратить внимание на трудоемкость выбранных алгоритмов на разных участках. В любом случае, стоит стремиться выделить ограниченное количество потоков, но при этом максимально загруженных работой [5]. Это будет эффективнее, так как нивелирует накладные расходы на обеспечение жизненного цикла потока.
В то же время необходимо соблюсти баланс нагрузки на потоки. В случае чрезмерной загруженности одного из потоков, и недостаточной нагрузки на остальные могут возникнуть дополнительные трудности с синхронизацией – потокам с меньшей нагрузкой придется ожидать более загруженные. При обнаружении неравномерности нагрузки на потоки необходимо выяснить причину этого и по возможности устранить.
Дополнительным средством оптимизации может служить определение числа эффективно выполняемых потоков для конкретного компьютера, которое эквивалентно числу ядер процессора с учетом гиперпоточности. Таким образом, зная информацию о аппаратных границах эффективной многопоточности, можно настраивать работу программы под конкретный компьютер, избегая как излишней нагрузки на потоки, так и создания слишком большого числа потоков.
4 ПОСТАНОВКА ЗАДАЧИ
Необходимо исследовать возможные способы оптимизации фильтра масштабирования видео. По результатам исследования осуществить оптимизацию фильтра, а также предложить пути возможного совершенствования и доработки.
Требуется также осуществить перенос фильтра на платформу Windows 64 bit.
При оптимизации необходимо также учесть возможный переход на операционные системы семейства Unix и Mac OS.
5 ХОД ВЫПОЛНЕНИЯ ПРАКТИКИ
Выполнение задания по практике начато с ознакомления с основами технологии DirectShow. Проведено ознакомление со всеми свойствами, доступными пользователю фильтра масштабирования видео. Получены навыки тестирования и отладки фильтров.
Осуществлено ознакомление с исходным кодом программы. В качестве приоритетных участков программы для оптимизации выделены фрагменты, реализующие непосредственное масштабирование, что подтверждено замерами времени выполнения различных частей программы.
Оптимизация программы с применением многопоточности уже осуществлена. Замену алгоритмов масштабирования в фильтре на более быстродействующие на данном этапе решено не производить в связи с перспективой их успешной оптимизации. На основании проведенных исследований в качестве эффективного средства оптимизации методов масштабирования, являющихся одновременно самыми затратными по времени участками фильтра, выбран перевод критических участков кода на Ассемблер с применением технологии SIMD. В соответствии с требованиями компании Элекард, работоспособность фильтра не должна зависеть от поддержки процессором технологии SIMD. Для сохранения работоспособности фильтра и одновременного осуществления оптимизации критических участков кода было решено создать две версии оптимизации. Первая версия будет реализована на Ассемблере без применения векторных команд и оптимизирована. Во второй версии необходимо обеспечить максимальное быстродействие на процессорах с поддержкой векторных вычислений. Для реализации аппаратной независимости работоспособности фильтра реализован блок проверки модели процессора и поддержки им векторного расширения набора команд. В зависимости от результатов проверки, производится выбор версии оптимизированных участков для использования в работе фильтра.
В рамках данной практики реализованы версии процедур масштабирования на Ассемблере без применения векторных команд, произведена их отладка и тестирование. В качестве используемого компилятора выбран NASM, как позволяющий получить кроссплатформенный код, не нуждающийся в значительных модификациях при переносе на другую операционную систему. По результатам тестирования данная реализация показала свою эффективность и принята к использованию в фильтре. Результаты сравнительного тестирования полученной реализации для различных методов масштабирования приведены в таблице 5.1.
Таблица 5.1 – Результаты оптимизации методов масштабирования с применение Ассемблера без технологии SIMD.
| Метод Ускорение | Sharp | Precise | Lanczos |
| Прирост производительности, % | 54.6 | 38.6 |
ЗАКЛЮЧЕНИЕ
В ходе прохождения преддипломной практики было осуществлено ознакомление с различными методами оптимизации программ, а также технологией мультимедиа фильтров DirectShow. Получены навыки работы с фильтрами, их отладки и тестирования. Приобретены навыки участия в ознакомлении и модернизации реального коммерческого фильтра обработки видеоданных. Произведена частичная оптимизация фильтра масштабирования видео в соответствии с результатами исследований, согласованных с компанией Элекард. Намечены шаги по дальнейшей оптимизации и доработке фильтра. В качестве таковых решено выделить:
1. Реализовать версию критических по времени выполнения процедур на Ассемблере с применением технологии SIMD.
2. Исследовать возможность замены блока конверсии форматов видео на более совершенную реализацию. По возможности, осуществить замену с выполнением требуемых для этого модификаций.
3. Осуществить перенос фильтра на платформу Windows 64 bit и дополнительная оптимизация с учетом особенностей данной системы.
Список использованных источников
1. Макаров В.В. Телекоммуникации России: состояние, тенденции и пути развития - М.: Ириас, 2007. – 296 с.
2. Шифрис Г. В. Использование предварительного масштабирования для повышения качества видеопотока [Текст] / Г. В. Шифрис // Технические науки: проблемы и перспективы: материалы междунар. заоч. науч. конф. (г. Санкт-Петербург, март 2011 г.). / Под общ. ред. Г. Д. Ахметовой — СПб.: Реноме, 2011. — С. 195-205.
3. Есенин С.А. DirectX и Delphi: разработка графических и мультимедийных приложений. – СПб.: БХВ-Петербург, 2006. -512 с.: ил.
4. Wilhelm Burger, Mark J Burge. Principles of Digital Image Processing. Core Algorithms – London: Springer, 2009 - 329 pages.
5. Ричард Гербер, Арт Бик, Кевин Смит, Ксинмин Тиан. Оптимизация ПО. Сборник рецептов – СПб.: Питер, 2010. – 352 с.
6. Intel 64 and IA-32 Architectures Optimization Reference Manual. [Электронный ресурс]: Intel Corporation, 2007. Order Number: 248966-016. – Режим доступа: https://www.intel.com/content/dam/doc/manual/64-ia-32-architectures-optimization-manual.pdf
7. Паттерсон Д. и Хэннесси Д. Архитектура компьютера и проектирование компьютерных систем. 4-е изд. – СПб.: Питер, 2012. - 784 с.
8. Intel 64 and IA-32 Architectures Software Developer’s Manual. Volume 2B: Instruction Set Reference M-Z. [Электронный ресурс]: Intel Corporation, 2011. Order number 253667. – Режим доступа: https://www.intel.com/content/dam/www/public/us/en/documents/manuals/64-ia-32-architectures-software-developer-vol-2b-manual.pdf
|
|