Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Листинг 10. Использование макроса для итерации по списку
|
|
| struct list_head* position; list_for_each (position, & mylinkedlist) { printk (" surfing the linked list next = %p and prev = %p\n", position-> next, position-> prev); } |
Исходный код в листинге 11 суммирует всю информацию, представленную в этой статье. В нем демонстрируется реализация связного списка с помощью макроса define_list, принимающего на вход два параметра - имя списка и тип элемента. Также в листинге 11 объявлены уже знакомые и новые inline-функции, обеспечивающие функциональность связного списка. В методе main объявленные методы и структуры используются для создания связного списка из пяти элементов и последующей итерации по нему.
Листинг 11. Пример объявления и использования связного списка
| #include < stdbool.h> #include < stdio.h> #include < stdlib.h> /* объявление списка */struct list_head { struct list_head *next, *prev; }; /* статический inline-метод для инициализации списка */static inline void INIT_LIST_HEAD(struct list_head *list){ list-> next = list; list-> prev = list; } /* статический inline-метод для вставки элемента в список */static inline void __list_add(struct list_head *new, struct list_head *prev, struct list_head *next){ next-> prev = new; new-> next = next; new-> prev = prev; prev-> next = new; } /* статический inline-метод для добавления элементов в конец списка */static inline void list_add_tail(struct list_head *new, struct list_head *head){ __list_add(new, head-> prev, head); } #undef offsetof#ifdef __compiler_offsetof#define offsetof(TYPE, MEMBER) __compiler_offsetof(TYPE, MEMBER)#else#define offsetof(TYPE, MEMBER) ((size_t) & ((TYPE *)0)-> MEMBER)#endif #define container_of(ptr, type, member) ({ \ const typeof(((type *)0)-> member) *__mptr = (ptr); \ (type *)((char *)__mptr – offsetof(type, member)); }) #define list_entry(ptr, type, member) \ container_of(ptr, type, member) /* реализация связного списка с необходимой функциональностью */#define define_list(name, type) \ struct name##_head { \ struct list_head _private; \ }; \ \ static inline type *name##_head_first(struct name##_head *head) { \ return list_entry(head-> _private.next, type, name); \ } \ \ static inline type *name##_next(const type *node) { \ return list_entry(node-> name.next, type, name); \ } \ \ static inline bool name##_is_last(struct name##_head *head, const type *node) { \ return & head-> _private == & node-> name; \ } \ \ static inline void name##_init(struct name##_head *head) { \ INIT_LIST_HEAD(& head-> _private); \ } \ \ static inline void name##_add_tail(struct name##_head *head, type *new) { \ list_add_tail(& new-> name, & head-> _private); \ } /* объявление элемента списка */struct node { struct list_head node_list; char *string; }; /* объявление связного списка с заданным именем и нужным типом элементов */define_list(node_list, struct node); struct node *new_node(const char *string){ struct node *ret = malloc(sizeof struct node); ret-> string = string; return ret; } /* метод main */int main(int argc, char *argv[]){ /* создание и инициализация списка */ struct node_list_head head; node_list_init(& head); /* добавление элементов в конец списка */ node_list_add_tail(& head, new_node(" 1")); node_list_add_tail(& head, new_node(" 2")); node_list_add_tail(& head, new_node(" 3")); node_list_add_tail(& head, new_node(" 4")); node_list_add_tail(& head, new_node(" 5")); /* итерация по списку, начиная с первого элемента */ for (struct node *i = node_list_head_first(& head);! node_list_is_last(& head, i); i = node_list_next(i)) { printf(" node: %s\n", i-> string); } return 0; } |
В начало
Заключение
В данной статье рассматривались связные списки, которые относятся к наиболее важным структурам данных, использующихся в современном программировании. В статье рассматривались как теоретические аспекты со связными списками (задача Иосифа Флавия), так и практическая реализация связных списков в ядре ОС Linux. Для теоретической задачи была разработана реализация на двух различных языках программирования: Си и Python. Однако практическая задача была решена с помощью языка Си, так как в нем имеются такие возможности, как inline-функции и макросы, благодаря использованию которых можно значительно увеличить скорость работы приложения.
Связные списки и сортировка
Введение
В данной статье будут разбираться наиболее популярные алгоритмы сортировки: пузырьковая сортировка, быстрая сортировка и сортировка слиянием. В конце статьи будет выполнено сравнительное тестирование производительности этих трех алгоритмов при работе со связными списками.
Типы сортировок
Сортировка – это процесс перестановки объектов конечного множества в определенном порядке, предназначенный для облегчения последующего поиска элементов в уже отсортированном множестве. Для сортировки можно использовать огромное множество алгоритмов, поэтому часто требуется выполнить сравнительный анализ нескольких алгоритмов, чтобы определить оптимальный выбор для конкретной задачи.
Методы сортировки обычно разделяются на две категории: сортировка массивов и сортировка файлов, также называемые внутренней и внешней сортировкой, так как массивы располагаются во внутренней памяти, а файлы во внешней. Важнейшее требование к алгоритмам для сортировки массивов и связных списков - экономное расходование памяти, поэтому использование дополнительных массивов для сортировки считается дурным тоном.
Основным критерием для классификации алгоритмов сортировки является их быстродействие. При сортировке выполняются два типа операций - сравнение ключей и перестановка элементов (в случае со связными списками - переназначение указателей). Если в массиве n элементов, то алгоритм считается хорошим, если число перестановок равно произведению числа элементов массива n на логарифм этого числа log(n). Например, стандартная пузырьковая сортировка требует числа перестановок, равного квадрату от n.
Методы сортировки можно разбить на три основных класса:
- сортировка включениями;
- сортировка выбором;
- сортировка обменом.
Принцип, лежащий в основе первого класса, заключается в том, что массив разбивается на две половины - итоговую и входную. Берется элемент из входной половины и вставляется в итоговую в порядке сортировки. Число перестановок элементов в общем случае равно квадрату от n.
В случае сортировки выбором алгоритм таков: берется минимальный элемент массива и ставится в начало массива, и т.д. Число перестановок элементов в общем случае меньше, чем в первом случае, и будет равно произведению числа элементов массива на логарифм от этого числа. Быстрая сортировка относится ко второму классу.
В начало
Пузырьковая сортировка
Первым будет рассматриваться алгоритм пузырьковой сортировки, который требует порядка n*n перестановок, поэтому является не самым удачным выбором. В функции llist_bubble_sort, приведенной в листинге 1, выполняется вложенная итерация по списку, с помощью которой реализуется алгоритм пузырьковой сортировки для языка Си.
Листинг 1. Реализация пузырьковой сортировки на языке Си
| #include < stdio.h> #include < stdlib.h> #define MAX 10 struct lnode { int data; struct lnode *next; } *head, *visit; void llist_add(struct lnode **q, int num); void llist_bubble_sort(void); void llist_print(void); int main(void) { struct lnode *newnode = NULL; int i = 0; for(i = 0; i < MAX; i++) { llist_add(& newnode, (rand() % 100)); } head = newnode; printf(" до пузырьковой сортировки: \n"); llist_print(); printf(" после пузырьковой сортировки: \n"); llist_bubble_sort(); llist_print(); return 0; } void llist_add(struct lnode **q, int num) { struct lnode *tmp; tmp = *q; if(*q == NULL) { *q = malloc(sizeof(struct lnode)); tmp = *q; } else { while(tmp-> next! = NULL) tmp = tmp-> next; tmp-> next = malloc(sizeof(struct lnode)); tmp = tmp-> next; } tmp-> data = num; tmp-> next = NULL; } void llist_print(void) { visit = head; while(visit! = NULL) { printf(" %d ", visit-> data); visit = visit-> next; } printf(" \n"); } void llist_bubble_sort(void) { struct lnode *a = NULL; struct lnode *b = NULL; struct lnode *c = NULL; struct lnode *e = NULL; struct lnode *tmp = NULL; while(e! = head-> next) { c = a = head; b = a-> next; while(a! = e) { if(a-> data > b-> data) { if(a == head) { tmp = b -> next; b-> next = a; a-> next = tmp; head = b; c = b; } else { tmp = b-> next; b-> next = a; a-> next = tmp; c-> next = b; c = b; } } else { c = a; a = a-> next; } b = a-> next; if(b == e) e = a; } }} |
В листинге 2 приведена реализация пузырьковой сортировки на языке Python с использованием стандартных списков, встроенных в Python.
Листинг 2. Реализация пузырьковой сортировки на языке Python
| import random lista = [] for i in range (0, 10): lista.append (int (random.uniform (0, 10))) print listadef bubble_sort (lista): swap_test = False for i in range (0, len (lista) - 1): for j in range (0, len (lista) - i - 1): if lista[j] > lista[j + 1]: lista[j], lista[j + 1] = lista[j + 1], lista[j] swap_test = True if swap_test == False: break bubble_sort (lista) print lista |
В листинге 3 приведен исходный код пузырьковой сортировки для Python, но уже на основе связных списков.
Листинг 3. Пузырьковая сортировка с использованием связных списков
| import random class Node: def __init__(self, value = None, next = None): self.value = value self.next = next def __str__(self): return 'Node ['+str(self.value)+']' class LinkedList: def __init__(self): self.first = None self.last = None self.length = 0 def add(self, x): if self.first == None: self.first = Node(x, None) self.last = self.first elif self.last == self.first: self.last = Node(x, None) self.first.next = self.last else: current = Node(x, None) self.last.next = current self.last = current def __str__(self): if self.first! = None: current = self.first out = 'LinkedList [ ' +str(current.value) +' ' while current.next! = None: current = current.next out += str(current.value) + ' ' return out + ']\n' return 'LinkedList []' def BubbleSort(self): a = Node(0, None) b = Node(0, None) c = Node(0, None) e = Node(0, None) tmp = Node(0, None) while(e! = self.first.next): c = a = self.first b = a.next while a! = e: if a and b: if a.value > b.value: if a == self.first: tmp = b.next b.next = a a.next = tmp self.first = b c = b else: tmp = b.next b.next = a a.next = tmp c.next = b c = b else: c = a a = a.next b = a.next if b == e: e = a else: e = a L = LinkedList() for i in range (0, 10): L.add (int (random.uniform (0, 10))) print LL.BubbleSort()print L |
Как можно увидеть, код в листинге 3 очень похож на код на языке Си, приведенный в листинге 1, поскольку в Python работа со ссылками на объекты реализована практически так же, как и в языке Си.
В начало
Быстрая сортировка
В данном разделе будет рассмотрен алгоритм быстрой (quicksort) сортировки двусвязного списка, на основе рекурсивной функции QuickSortList, представленной в листинге 4. Данная функция работает следующим образом:
- выполняется итерация по списку;
- в ходе итерации определяется максимальное значение, которое записывается в конец массива;
- выполняется следующая итерация, но без только что найденного максимума и т.д.
Листинг 4. Реализация быстрой сортировки на языке Си
| #include < stdio.h> // элемент двусвязного спискаtypedef struct _tagIntegerList{ int nInteger; struct _tagIntegerList *pPrev; struct _tagIntegerList *pNext; } IntegerList; // указатели на первый и последний элементы спискаIntegerList *g_pFirstItem = NULL; IntegerList *g_pLastItem = NULL; // добавление в списокvoid AddListItem(int nInteger){ IntegerList *pItem = new IntegerList; pItem-> nInteger = nInteger; if (g_pFirstItem == NULL) { g_pFirstItem = g_pLastItem = pItem; pItem-> pNext = pItem-> pPrev = NULL; } else { g_pLastItem-> pNext = pItem; pItem-> pPrev = g_pLastItem; g_pLastItem = pItem; pItem-> pNext = NULL; }} // удалениеvoid RemoveAllItems(){ IntegerList *pDelItem, *pItem = g_pFirstItem; while (pItem! = NULL) { pDelItem = pItem; pItem = pItem-> pNext; delete pDelItem; } g_pFirstItem = g_pLastItem = NULL; } // вывод содержимого списка в консольvoid PrintList(){ IntegerList *pItem = g_pFirstItem; while (pItem! = NULL) { printf(" %d ", pItem-> nInteger); pItem = pItem-> pNext; } printf(" \n"); } // быстрая сортировкаvoid QuickSortList(IntegerList *pLeft, IntegerList *pRight){ IntegerList *pStart; IntegerList *pCurrent; int nCopyInteger; // сортировка окончена - выход if (pLeft == pRight) return; // установка двух рабочих указателей - Start и Current pStart = pLeft; pCurrent = pStart-> pNext; // итерация по списку слева направо while (1) { // элемент с максимальным значением помещается в начало списка if (pStart-> nInteger < pCurrent-> nInteger) { nCopyInteger = pCurrent-> nInteger; pCurrent-> nInteger = pStart-> nInteger; pStart-> nInteger = nCopyInteger; } if (pCurrent == pRight) break; pCurrent = pCurrent-> pNext; } // переключение First и Current - максимум попадает в правый конец списка nCopyInteger = pLeft-> nInteger; pLeft-> nInteger = pCurrent-> nInteger; pCurrent-> nInteger = nCopyInteger; // сохранение Current IntegerList *pOldCurrent = pCurrent; // рекурсия pCurrent = pCurrent-> pPrev; if (pCurrent! = NULL) { if ((pLeft-> pPrev! = pCurrent) & & (pCurrent-> pNext! = pLeft)) QuickSortList(pLeft, pCurrent); } pCurrent = pOldCurrent; pCurrent = pCurrent-> pNext; if (pCurrent! = NULL) { if ((pCurrent-> pPrev! = pRight) & & (pRight-> pNext! = pCurrent)) QuickSortList(pCurrent, pRight); }} int main (){ AddListItem(100); AddListItem(12); AddListItem(56); AddListItem(67); PrintList(); QuickSortList(g_pFirstItem, g_pLastItem); PrintList(); RemoveAllItems(); return 0; } |
В начало
Сортировка слиянием
При сортировке слиянием (mergesort) массив разбивается на две части, каждая часть сортируется отдельно, а потом обе части сливаются. Практически это можно объяснить на следующем примере.
- колода карт делится на две части, и каждая часть сортируется по отдельности, чтобы наверху оказалась самая маленькая карта;
- из двух верхних карт выбирают меньшую и перекладывают ее в результирующую колоду;
- процесс повторяется, пока не кончатся карты в обеих половинах;
- если в одной половине карты закончатся раньше, тогда все карты, оставшиеся в другой половине, просто перекладываются в результирующую колоду.
Считается, что этот алгоритм был придуман Джоном фон Нейманом в 1945 году. Недостатком сортировки слиянием считается то, что она требует O(n) памяти.
Листинг 5. Реализация сортировки слиянием на языке Си
| struct node { int number; struct node *next; }; struct node *addnode(int number, struct node *next) { struct node *tnode; tnode = (struct node*)malloc(sizeof(*tnode)); if(tnode! = NULL) { tnode-> number = number; tnode-> next = next; } return tnode; } int Length(struct node* head) { int count = 0; struct node* current = head; while (current! = NULL) { count++; current = current-> next; } return(count); } void FrontBackSplit(struct node* source, struct node** frontRef, struct node** backRef) { int len = Length(source); int i; struct node* current = source; if (len < 2) { *frontRef = source; *backRef = NULL; } else { int hopCount = (len-1)/2; for (i = 0; i< hopCount; i++) { current = current-> next; } // исходный список разбивается на два подсписка *frontRef = source; *backRef = current-> next; current-> next = NULL; }} struct node* SortedMerge(struct node* a, struct node* b) { struct node* result = NULL; if (a==NULL) return(b); else if (b==NULL) return(a); if (a-> number < = b-> number) { result = a; result-> next = SortedMerge(a-> next, b); } else { result = b; result-> next = SortedMerge(a, b-> next); } return(result); } void MergeSort(struct node** headRef) { struct node* head = *headRef; struct node* a; struct node* b; // вырожденный случай – длина списка равно 0 или 1 if ((head == NULL) || (head-> next == NULL)) { return; } FrontBackSplit(head, & a, & b); MergeSort(& a); // рекурсивная сортировка подсписков MergeSort(& b); *headRef = SortedMerge(a, b); } |
В начало
Сравнение различных алгоритмов
После изучения различных алгоритмов сортировки можно выполнить их сравнительное тестирование. В качестве исходной позиции будет использоваться односвязный список длиной в 50000 элементов, при этом ключ в элементе может иметь значение от 0 до 100. Элементы вставляются в произвольном порядке, и исходный список может иметь следующий вид:
| 0 10 10 2 9 7 2 3 4 5 2 2 10 1 1..... |
А после сортировки список должен иметь следующий вид:
| 0 1 1 2 2 2 2 3 4 5 7 9 10 10 10..... |
В ходе теста будут фиксироваться три временных отметки: запуск программы, начало и конец сортировки. Наибольший интерес будет представлять время, непосредственно затраченное на сортировку. В листинге 6 приведен исходный код функции main для оценки производительности пузырьковой сортировки.
Листинг 6. Оценка производительности пузырьковой сортировки на языке Си
| int main(void) { time_t start, time2, end; volatile long unsigned t; start = time(NULL); struct lnode *newnode = NULL; int i = 0; for(i = 0; i < MAX; i++) { llist_add(& newnode, (rand() % 100)); } head = newnode; printf(" до пузырьковой сортировки: \n"); time2 = time(NULL); printf(" на подготовку потребовалось %f секунд.\n", difftime(time2, start)); printf(" после пузырьковой сортировки: \n"); llist_bubble_sort(); end = time(NULL); printf(" на сортировку потребовалось %f секунд.\n", difftime(end, time2)); return 0; } |
В листинге 7 приведен исходный код для проверки производительности быстрой сортировки.
Листинг 7. Оценка производительности быстрой сортировки на языке Си
| int main (){ time_t start, time2, end; volatile long unsigned t; start = time(NULL); for(int i = 0; i < 50000; i++) { AddListItem((rand() % 100)); } time2 = time(NULL); printf(" на подготовку потребовалось %f секунд.\n", difftime(time2, start)); QuickSortList(g_pFirstItem, g_pLastItem); end = time(NULL); printf(" на сортировку потребовалось %f секунд.\n", difftime(end, time2)); return 0; } |
В случае с сортировкой слиянием главная проблема связана с увеличением стека при рекурсии, так как при увеличении длины списка свыше 50000 элементов могут возникнуть ошибки. Функция main для сортировки слиянием показана в листинге 8.
Листинг 8. Оценка производительности сортировки слиянием на языке Си
| int main(void) { time_t start, time2, end; volatile long unsigned t; start = time(NULL); struct node *head; int i; head = NULL; for(i = 0; i < 100; i++) { head = addnode((rand() % 100), head); } time2 = time(NULL); printf(" на подготовку потребовалось %f секунд.\n", difftime(time2, start)); MergeSort(& head); end = time(NULL); printf(" на сортировку потребовалось %f секунд.\n", difftime(end, time2)); return 0; } |
Стоит учесть, что этот тест не претендует на звание «абсолютной истины», так как речь идет о конкретной реализации, применяемой на конкретной системе. Наихудший результат, как и ожидалось, показала пузырьковая сортировка, которой на то, чтобы упорядочить связный список из 50000 элементов, потребовалось более 30 секунд. Быстрая сортировка справилась с этой же задачей за 10 секунд. А самой производительной оказалась сортировка слиянием, выполнив задачу еще быстрее, чем быстрая сортировка. Также тест выявил следующие закономерности.
- Наибольшее число перестановок требуется пузырьковой сортировке, затем идет быстрая сортировка, и меньше всего перестановок требуется для сортировки слиянием.
- При увеличении длины списка отношение числа перестановок в пузырьковой сортировке к числу перестановок в быстрой сортировке растет не в пользу первой, то есть при увеличении размера списка производительность пузырьковой сортировки начинает снижаться.
- Сортировка слиянием имеет самые лучшие показатели по числу перестановок. Аналогичное соотношение числа перестановок для быстрой сортировки и сортировки слиянием при увеличении длины списка изменяется в пользу быстрой сортировки: чем больше список, тем меньше это соотношение, хотя и остается больше единицы.
Заключение
Как было показано в данной статье, при использовании различных алгоритмов для сортировки связных списков можно добиться очень высокой производительности, невзирая на большой размер списка. Однако конечный результат зависит от целого комплекса факторов: эффективного использования памяти, глубины рекурсии, производительности целевой системы и т.д.
Деревья
Работа со структурами данных в языках Си и Python: Часть 5. Деревья
Введение
Начиная с этой статьи мы переходим от связных списков к изучению деревьев. Это не случайно, так оба эти типа структур данных построены на основе рекурсии. Фактически, связные списки являются подвидом деревьев, называемым вырожденным деревом. В данной статье будут рассмотрены общие принципы построения деревьев и различные варианты обхода узлов дерева.
Основные принципы
Первое появление концепции дерева в математике зафиксировано в середине 19-го века, а затем деревья стали использоваться в самых разных областях, например, в теории электрических цепей или химической изометрии. Использование древовидных структур в информационных технологиях началось с приложений для манипулирования алгебраическими формулами в 60-ых годах прошлого века, примерно тогда же появились традиционные алгоритмы для обхода деревьев.
В общем смысле, дерево - это иерархическая структура, хранящая коллекцию объектов. Деревья широко применяются в компьютерных технологиях, и самым близким примером является файловая система, представляющая собой иерархическую структуру из файлов и каталогов. Дерево (англ. tree) — это непустая коллекция вершин и ребер, удовлетворяющих определенным требованиям. Вершина (англ. vertex) — это объект, называемый также узлом (англ. node) по аналогии со списками, который может иметь имя и содержать другую информацию. Ключевое свойство дерева — между любыми двумя узлами существует только один путь, соединяющий их. Если между какой-либо парой узлов существует более одного пути или если между какой-либо парой узлов путь отсутствует, то подобная структура называется графом, а не деревом. Несвязанный набор деревьев называется лесом (англ. forest).
Для определения узлов существуют следующие сложившиеся термины:
- root - узел, расположенный в корне дерева;
- siblings - узлы, имеющие одного и того же родителя;
- ancestor или parent – родительский узел;
- descendant – дочерний узел;
- size – размер узла, равный количеству дочерних узлов плюс один.
В рамках данной статьи будут обсуждаться деревья с произвольным количеством дочерних узлов. Упорядоченное (англ. ordered) дерево — это дерево с определенным корневым узлом, в котором также определен порядок следования дочерних узлов для каждого узла.
Деревья можно разделить на следующие категории:
- деревья без корня;
- деревья с корнем;
- упорядоченные деревья;
- м-арные и бинарные деревья.
На рисунке 1 показано, как оглавление книги можно представить в виде дерева. В показанном примере корневой узел имеет три поддерева – три главы, каждая из которых в свою очередь имеет свои подразделы.
Рисунок 1. Пример древовидной структуры

Путь (англ. path) - это последовательность узлов, которые нужно пройти, чтобы из корневого узла попасть в какой-либо дочерний узел. Длина пути равна числу узлов минус один. Высота (англ. height) - это путь от корня до наиболее удаленного узла. Например, на рисунке 1 высота поддерева часть № 1 равна единице, часть № 2 - двум, а высота поддерева часть № 3 равна нулю, так как оно не имеет дочерних узлов. Дочерние узлы обычно принять считать слева направо, но это можно делать в различном порядке. На рисунке 2 приведен пример дерева и результат использования трех различных подходов для обхода узлов.
Рисунок 2. Пример древовидной структуры

- preorder – сверху-вниз-слева-направо: F, B, A, D, C, E, G, I, H;
- inorder – слева-вверх-вниз-вправо: A, B, C, D, E, F, G, H, I;
- postorder – обратное движение от детей к родителям: A, C, E, D, B, H, I, G, F.
Если сравнить древовидные структуры со связными списками, то станет понятно, что наибольшую сложность при работе с деревьями представляют динамические операции, такие как вставка и удаление узлов. Например, при удалении узла из бинарного дерева необходимо решить проблему наличия двух дочерних и одного родительского узла.
В начало
Рекурсивная реализация алгоритмов для обхода дерева
В листинге 1 приведен псевдокод для трех описанных ранее алгоритмов обхода дерева, основанный на использовании рекурсии. В рамках рассматриваемой реализации было внесено ограничение, что у любого узла не может быть более трех дочерних узлов.
Листинг 1. Псевдокод алгоритмов для обхода дерева
| preorder(node) print node.value if node.left ≠ null then preorder(node.left) if node.middle ≠ null then preorder(node.middle) if node.right ≠ null then preorder(node.right) inorder(node) if node.left ≠ null then inorder(node.left) print node.value if node.middle ≠ null then inorder(node.middle) if node.right ≠ null then inorder(node.right) postorder(node) if node.left ≠ null then postorder(node.left) if node.middle ≠ null then postorder(node.middle) if node.right ≠ null then postorder(node.right) print node.value |
В листинге 2 приведен пример обхода 3-нарного дерева (где каждый узел может иметь не более трех дочерних элементов) с помощью различных алгоритмов, реализованных на языке Си. Дерево из 10 узлов будет сформировано в методе main, а затем к нему будут применены три варианта обхода, которые будут приведены в отдельном листинге.
Листинг 2. Реализация дерева на языке Си
| #include < stdio.h> #include< stdlib.h> //структура для описания узла дереваstruct tree { int data; struct tree *lchild, *mchild, *rchild; }; struct tree *my_insert(struct tree *p, int n, int dir); void inorder(struct tree *p); void preorder(struct tree *p); void postorder(struct tree *p); int main() { int x, y, i; struct tree *root; struct tree *node_2, *node_3, *node_5; struct tree *node_8, *node_9, *node_6, *node_10, *node_4, *node_7; //создание дерева root = NULL; root = my_insert(root, 1, 0); node_2 = my_insert(root, 2, 0); node_3 = my_insert(root, 3, 1); node_4 = my_insert(root, 4, 2); node_5 = my_insert(node_3, 5, 0); node_8 = my_insert(node_5, 8, 0); node_9 = my_insert(node_5, 9, 2); node_6 = my_insert(node_3, 6, 2); node_10 = my_insert(node_6, 10, 1); node_7 = my_insert(node_4, 7, 1); //выполнение обхода дерева различными способами preorder(root); printf(" \n"); inorder(root); printf(" \n"); postorder(root); return 0; } |
В листинге 3 приведен исходный код функции для вставки узлов в дерево. Данная функция принимает на вход три параметра: указатель на вставляемый узел, значение вставляемого узла и направление вставки — влево, в середину или вправо.
Листинг 3. Функция для вставки узлов в дерево
| struct tree * my_insert(struct tree *p, int n, int dir) { struct tree *temp; temp = (struct tree *)malloc(sizeof(struct tree)); temp-> data = n; temp-> lchild = temp-> rchild=NULL; if(p==NULL) { return temp; } else { if(dir ==0) // влево { p-> lchild = temp; return temp; } else if(dir ==1) // посередине { p-> mchild = temp; return temp; } else // вправо { p-> rchild = temp; return temp; } } } |
В листинге 4 приведен исходный код функций, реализующих различные варианты обхода дерева.
Листинг 4. Функции для обхода узлов дерева
| void inorder(struct tree *p){ if(p! =NULL) { inorder(p-> lchild); printf(" %d ", p-> data); inorder(p-> mchild); inorder(p-> rchild); }} void preorder(struct tree *p){ if(p! =NULL) { printf(" %d ", p-> data); preorder(p-> lchild); preorder(p-> mchild); preorder(p-> rchild); }} void postorder(struct tree *p){ if(p! =NULL) { postorder(p-> lchild); postorder(p-> mchild); postorder(p-> rchild); printf(" %d ", p-> data); }} |
В листинге 5 приведена реализация алгоритмов обхода дерева на языке Python. В нем объявляются два класса — один для узлов и другой для самого дерева. В конструкторе класса Tree для наглядности объявляются ссылки на узлы.
Листинг 5. Реализация обхода дерева на языке Python
| //класс, представляющий узелclass node: def __init__(self, data = None, lchild = None, mchild = None, rchild = None): self.data = data self.lchild = lchild self.mchild = mchild self.rchild = rchild def __str__(self): return 'Node ['+str(self.value)+']' //класс, представляющий деревоclass Tree: def __init__(self): self.root = None self.node_2 = None self.node_3 = None self.node_4 = None self.node_5 = None self.node_6 = None self.node_7 = None self.node_8 = None self.node_9 = None self.node_10 = None //функция для добавления элементов в дерево def my_insert(self, root_node, data, dir): temp = node(0, None, None, None) temp.data = data if root_node == None: return temp else: if dir == 0: root_node.lchild = temp return temp elif dir == 1: root_node.mchild = temp return temp else: root_node.rchild = temp return temp //рекурсивные функции для обхода дерева def inorder(self, noda): if noda! =None: self.inorder(noda.lchild); print(" %d " % noda.data) self.inorder(noda.mchild) self.inorder(noda.rchild) def preorder(self, noda): if noda! =None: print (" %d " % noda.data) self.preorder(noda.lchild); self.preorder(noda.mchild) self.preorder(noda.rchild) def postorder(self, noda): if noda! =None: self.postorder(noda.lchild); self.postorder(noda.mchild) self.postorder(noda.rchild) print (" %d " % noda.data) //создание дереваt = Tree()t.root = t.my_insert(t.root, 1, 0)t.node_2 = t.my_insert(t.root, 2, 0); t.node_3 = t.my_insert(t.root, 3, 1); t.node_4 = t.my_insert(t.root, 4, 2); t.node_5 = t.my_insert(t.node_3, 5, 0); t.node_8 = t.my_insert(t.node_5, 8, 0); t.node_9 = t.my_insert(t.node_5, 9, 2); t.node_6 = t.my_insert(t.node_3, 6, 2); t.node_10 = t.my_insert(t.node_6, 10, 1); t.node_7 = t.my_insert(t.node_4, 7, 1); //обход дереваt.preorder(t.root); t.inorder(t.root); t.postorder(t.root); |
В начало
Нерекурсивная реализация обхода дерева
Дерево можно обойти, и не используя рекурсию, причем это можно сделать любым из трех способов: inorder, preorder и postorder. Для этого можно использовать стандартный стек, работающий по принципу LIFO (последним пришел, первым ушел), в который будут записываться узлы по мере их прохождения. В качестве примера также будет использоваться три-нарное дерево.
Листинг 6. Нерекурсивный обзор дерева на языке Си
| #include < stdio.h> #include< stdlib.h> #include < iostream> #include < stack> using namespace std; struct tree { int data; struct tree *lchild, *mchild, *rchild; }; /* * функции для итеративного обхода дерева */void iterativeInorder(tree* root) { stack< tree*> nodeStack; tree *_root, *curr = root; _root = root; for (;;) { if (curr! = NULL) { nodeStack.push(curr); curr = curr-> lchild; continue; } if (nodeStack.size() == 0) { if(_root! = NULL) { curr = _root-> rchild; _root = NULL; continue; } else return; } curr = nodeStack.top(); nodeStack.pop(); cout < < curr-> data < < " "; if(curr-> mchild! = NULL) curr = curr-> mchild; else curr = curr-> rchild; }} void iterativePreorder(tree* root) { stack< tree*> nodeStack; tree *_root, *curr = root; _root = root; for (;;) { while (curr! = NULL) { cout < < curr-> data < < " "; nodeStack.push(curr); curr = curr-> lchild; } if (nodeStack.size() > 0) { curr = nodeStack.top(); nodeStack.pop(); if(curr-> mchild! = NULL) curr = curr-> mchild; else curr = curr-> rchild; } else { if(_root! = NULL) { curr = _root-> rchild; _root = NULL; continue; } else return; } }} void iterativePostorder(tree* root) { tree *curr = root; stack< tree*> s1, s2; s1.push(curr); tree *tmp=NULL; while (s1.size() > 0) { tmp = s1.top(); s1.pop(); s2.push(tmp); if (tmp-> lchild) s1.push(tmp-> lchild); if (tmp-> mchild) s1.push(tmp-> mchild); if (tmp-> rchild) s1.push(tmp-> rchild); } while(s2.size() > 0) { tmp = s2.top(); s2.pop(); cout < < tmp-> data < < " "; }} /* * функция для добавления узлов в дерево */struct tree * my_insert(struct tree *p, int n, int dir) { struct tree *temp; temp = (struct tree *)malloc(sizeof(struct tree)); temp-> data = n; temp-> lchild = temp-> rchild=NULL; if(p==NULL) { return temp; } else { if(dir ==0) // влево { p-> lchild = temp; return temp; } else if(dir ==1) // посередине { p-> mchild = temp; return temp; } else // вправо { p-> rchild = temp; return temp; } }} int main() { int x, y, i; struct tree *root; struct tree *node_2, *node_3, *node_5, *node_8; struct tree *node_9, *node_6, *node_10, *node_4, *node_7; root = NULL; root = my_insert(root, 1, 0); node_2 = my_insert(root, 2, 0); node_3 = my_insert(root, 3, 1); node_4 = my_insert(root, 4, 2); node_5 = my_insert(node_3, 5, 0); node_8 = my_insert(node_5, 8, 0); node_9 = my_insert(node_5, 9, 2); node_6 = my_insert(node_3, 6, 2); node_10 = my_insert(node_6, 10, 1); node_7 = my_insert(node_4, 7, 1); iterativeInorder(root); printf(" \n"); iterativePreorder(root); printf(" \n"); iterativePostorder(root); return 0; } |
В начало
Формы представления дерева
Одной из форм представления дерева является обычный массив. Пусть T - дерево, узлы в котором пронумерованы от 1 до n. Простейшей формой представления дерева T может быть линейный массив A, в котором каждый элемент массива A[i] представляет собой указатель на узел или его родителя.
Если i и j - два узла, и узел j является родителем для узла i, то
| A[i] = j |
Для идентификации корневого узла, указатель на его родителя можно сделать нулевым, как показано ниже:
| A[i] = 0 |
Каждый узел может иметь только одного родителя. Одновременно с массивом A можно завести массив L, в котором будут храниться метки для узлов. На рисунке 3 дерево представлено в виде массива родителей для каждого узла. Однако при использовании такого представления остается неясным, в каком порядке идут дочерние узлы.
Рисунок 3. Представление дерева в виде массива

Еще один возможный вариант представления деревьев – это использование связного списка, содержащего все узлы дерева, при этом дочерние узлы хранятся вместе с родительским, как показано на рисунке 4.
Рисунок 4. Представление дерева в виде списка

На этом рисунке показан общий массив узлов, пронумерованный от 1 до 10. У отдельных узлов из этого списка есть дочерние узлы, которые в общем списке помечены точками. Но так как массив имеет фиксированный размер, то в такое дерево нельзя вставить новый узел.
В начало
Виды деревьев
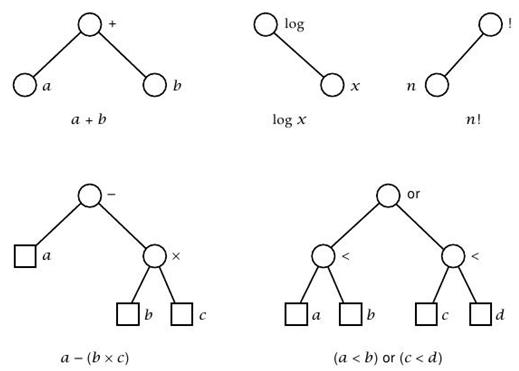
Дерево выражений (англ. expression tree) - это разновидность бинарного дерева, предназначенная для отображения арифметических или логических выражений, при этом операнды размещаются в листьях, как показано на рисунке 5.
Рисунок 5. Примеры использования дерева выражений
В узлах так называемого triply linked дерева, кроме ссылок на левый и правый дочерний узлы, хранится и ссылка на родительский узел, как показано на рисунке 6.
Рисунок 6. triply linked дерево

На рисунке 7 представлены еще два интересных варианта дерева – кольцевое дерево и дерево, не имеющее корня.
Рисунок 7. Необычные варианты деревьев

В начало
Заключение
Теория деревьев является одной из самых востребованных и популярных научных дисциплин в области информационных технологий. Древовидные структуры подходят для решения большого круга задач в самых различных отраслях знания. В компьютерных технологиях деревья являются ключевым компонентом для создания алгоритмов хранения, поиска и обработки информации. Любой программист должен уметь работать с подобными структурами данных, тем более, что как было показано в этой статье, для этого используются стандартные и хорошо зарекомендовавшие себя алгоритмы.
|
|