Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Иванов Петр 4 5 3
|
|
Требуется написать как можно более эффективную программу (укажите используемую версию языка программирования, например, Borland Pascal 7.0), которая будет выводить на экран фамилии и имена трех худших по среднему баллу учеников. Если среди остальных есть ученики, набравшие тот же средний балл, что и один из трех худших, то следует вывести и их фамилии и имена.
Как правильно понимать условие?
1) как и в предыдущей задаче, данные «подаются на вход программе», то есть, их можно читать с помощью операторов read (readln), предполагая, что кто-то вводит эти данные с клавиатуры вручную
2) «количество учеников не меньше 10, но не превосходит 100», здесь только вторая часть – полезная информация, она намекает на то, что придется все введенные данные одновременно держать в памяти, выделив массив (или массивы) размером 100 элементов
3) сказано, что фамилия имеет длину не более 20 символов, а имя – не более 15; здесь, по сути, важно лишь то, что фамилия и имя (вместе) занимают меньше 255 символов, то есть, «влезут» в стандартное ограничение (255 символов) для типа string в классических версиях Паскаля
4) после фамилии и имени записаны три оценки (а не одно число, как в прошлой задаче), причем по условию нас НЕ интересуют эти числа, а интересует только средний балл каждого ученика;
5) важно! средний балл – это вещественное число (может иметь дробную часть), тут уже стоит задуматься: все задачи обычно составляются так, чтобы они решались «хорошо», в то же время операции с дробными числами (почти) всегда выполняются с ошибками, поскольку большинство вещественных чисел нельзя точно (стандартными методами) представить в памяти реального компьютера
6) следующий шаг к правильному решению: поскольку число оценок у всех учеников одинаковое, средний балл для каждого это сумма его оценок, деленная на 3; поэтому вместо среднего балла мы можем сравнивать суммы баллов – целые числа!
7) требуется вывести фамилии и имена (баллы не нужны!) трех худших учеников, причем их может быть и больше, если несколько «худших» набрали одинаковую сумму баллов
8) если бы требовался один худший – все решается поиском по массиву; первая идея – найти самого худшего (1 проход), затем – 2-ого с конца (еще 1 проход), и, наконец, 3-его (всего три прохода по массиву)
9) это не лучший вариант (на экзамене будут сняты баллы) по двум причинам:
o в таком методе решения три прохода по массиву, а в самом деле достаточно одного (см. далее), значит, программа неэффективна
o непонятно, что делать в том случае, если худших – больше трех (в предельном случае – вообще все!) – за это также снимут баллы (программа работает не для всех вариантой входных данных)
10) возникает следующий вариант – отсортировать массив про возрастанию суммы (и, следовательно, среднего балла), одновременно переставляя имена и фамилии, а затем вывести самых худших, которые после сортировки окажутся в начале массива
11) этот вариант тоже плох, потому что программа неэффективна; «школьные» алгоритмы сортировки (метод «пузырька», метод выбора) имеют сложность 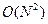 , а надо попытаться найти метод со сложностью
, а надо попытаться найти метод со сложностью 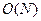
Решение (общий подход):
1) сначала составим программу в самом общем виде на псевдокоде, чтобы определить ее основные блоки, а потом будем их постепенно «расшифровывать» через операторы языка программирования:
{ читаем все данные и запоминаем их }
{ находим три худших результата }
{ выводим фамилии и имена тех, чей результат меньше или
равен «третьему худшему» }
2) до того, как начать писать «нормальный» код, нужно определить, как хранить данные; в данном случае нужно запомнить несколько данных по каждому ученику, их удобнее объединить в запись с двумя полями (фамилия-имя и сумма баллов); таких записей нужно выделить в памяти не менее 100 (по условию), то есть, массив из 100 элементов:
const LIM=100;
var Info: array[1..LIM] of record
name: string;
sum: integer;
End;
Чтение данных:
3) после того, как мы прочитали фактическое число учеников N, в цикле считываем и расшифровываем информацию о них, сохраняя все данные в структурах
for i: =1 to N do begin
{ считываем строку данных }
Info[i].name: = { фамилия и имя };
Info[i].sum: = { сумма баллов };
End;
4) здесь, в принципе, можно использовать тот же подход, что и в первой задаче – читаем строку целиком, затем «разбираем» ее на части с помощью стандартных функций – однако, для разнообразия, мы используем другой подход – будем читать информацию посимвольно, то есть, считывая по одному символу в переменную c типа char;
5) сначала в поле name очередной структуры записываем пустую строку '' (в которой нет ни одного символа, длина равна нулю)
Info[i].name: = ''; { пустая строка }
6) затем считываем символы фамилии и сразу приписываем их в конец поля name:
Repeat
|
|