Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Объем (количество) информации и её внутренняя организация – структура.
|
|
Об объёме и количестве информации речь пойдёт позднее, а по способу ее внутренней организации информацию делят на две группы:
1. Данные или простой, логически неупорядоченный набор сведений.
2. Логически упорядоченные, организованные наборы данных.
Упорядоченность достигается наложением на данные некоторой структуры (отсюда часто используемый термин — структура данных).
Знания и их свойства
Во второй группе выделяют особым образом организованную информацию — знания.
Знания (в отличие от данных) представляют информацию не о каком-то единичном и конкретном факте, а о том, как устроены все факты определённого типа.
Знания обладают свойствами:
Внутренняя интерпретируемость
Структурированность
Связанность
Активность
Все эти свойства знаний в конечном итоге обеспечивают возможность моделировать рассуждения человека в системах искусственного интеллекта.
Методы и модели оценки количества информации
Как и для характеристик вещества (вспомним массу, заряд, объем и т.д.), так и для характеристик информации имеются единицы измерения, что позволяет некоторой порции информации приписывать числа — количественные характеристики информации.
Способы измерения информации
На сегодняшний день наиболее известны следующие способы измерения информации:
Объёмный (самый простой и грубый),
Энтропийный (принят в теории информации и кодировании),
Алгоритмический (оценка сложности и размера соответствующей программы).
Объёмный способ измерения информации
Объем информации в сообщении — это количество символов в сообщении.
Поскольку, например, одно и то же число может быть записано многими разными способами (с использованием разных алфавитов), то этот способ чувствителен к форме представления (записи) сообщения.
Единицы измерения объёма
В вычислительной технике вся обрабатываемая и хранимая информация представлена в двоичной форме (с использованием алфавита, состоящего всего из двух символов 0 и 1).
Такая стандартизация позволила ввести две стандартные единицы измерения: бит и байт.
Бит — количество информации, которое может помещаться в один элемент памяти.
Байт — это восемь бит.
Энтропийный способ измерения количества информации
Этот способ измерения исходит из следующей модели. Получатель информации (сообщения) имеет определённые представления о возможных наступлениях некоторых событий. Эти представления в общем случае недостоверны и выражаются вероятностями Pi, с которыми он ожидает то или иное событие.
Общая мера неопределённости (энтропия) характеризуется некоторой математической зависимостью от совокупности этих вероятностей.
Количество информации в сообщении определяется тем, насколько уменьшится эта мера неопределённости после получения сообщения.
Формула Шеннона
Количество информации в сообщении, состоящем из N символов
H= - S P i log2 P i, где i изменяется от 1 до N,
P i - это вероятность i-ого символа.
P i = 1/Nпри равновероятных символах.
H=log2 N, где N - число возможных равновероятных символов в сообщении.
Формула Хартли
Используется для оценки количества информации H в сообщении, передаваемого по каналу связи числовым кодом.
Пусть m – основание системы счисления (число букв алфавита)
Пусть n – число разрядов в сообщении.
Тогда N = mn - число всевозможных кодовых комбинаций сообщения.
При равновероятном появлении любой кодовой комбинации количество информации, приобретённое получателем:
H=log2 N = log2 mn = n log2 m
Информативность сообщения
При условии полного априорного незнания получателем сообщения, передаваемого по каналу связи двоичным кодом, количество информации равно количеству символов в сообщении (числу разрядов), т.е. объёмный (V) и энтропийный (H) способ измерения дают один и тот же результат: H=V=n, бит
При наличии некоторой априорной информации, т.е. при не равновероятных символах в сообщении, всегда H< V=n.
Kинф = H/V, [0, 1] Для увеличения Kинф разрабатываются методы оптимального кодирования информации.
Алгоритмический способ измерения информации
Этот метод кратко можно охарактеризовать следующими рассуждениями.
Каждый согласится, что слово 0101…01 сложнее слова 00...0, а слово, где 0 и 1 выбираются из эксперимента — бросания монеты (где 0 — герб, 1 — решка), сложнее обоих предыдущих.
Понятие Машины Тьюринга
Так как имеется много разных вычислительных машин и разных языков программирования (разных способов задания алгоритма), то для определенности задаются некоторой конкретной вычислительной машиной, например, абстрактной машиной Тьюринга.
А предполагаемая количественная характеристика — сложность слова (сообщения) определяется как минимальное число внутренних состояний машины Тьюринга, требующиеся для его воспроизведения.
Основные понятия теории алгоритмов
В информатике алгоритмы рассматриваются в двух аспектах: теоретическом и прагматическом, тесно связанным с программированием.
Теория алгоритмов — раздел математики, изучающий общие свойства алгоритмов.
Понятие «алгоритм» сформировалось в математике в 20-х годах XX в. Началом систематической разработки теории алгоритмов можно считать 1936 г. и связывают это начало с публикацией работы А.А. Черча.
Алгоритмическая модель и её составляющие
Составляющими такой модели должны быть конкретный набор элементарных шагов, способы определения следующего шага. Каждый шаг должен быть элементарным и выполнимым, чтобы алгоритм понимался однозначно.
От модели также требуется простота и универсальность. Универсальность необходима для того, чтобы модель позволяла описать любой алгоритм.
Требование простоты важно для того, чтобы выделить необходимые элементы и свойства алгоритма и облегчить доказательства общих утверждений об этих свойствах.
Три основных класса алгоритмических моделей
Первый класс моделей основан на арифметизации алгоритмов.
Второй класс моделей основан на идее машинизации алгоритмов: он должен быть представлен так, чтобы его могла выполнять вычислительная машина.
Третий класс моделей алгоритмов оперирует конкретными алфавитами, здесь наиболее известная алгоритмическая модель— нормальные алгоритмы Маркова.
Первый. Предполагается, что любые данные можно закодировать числами, и как следствие — всякое их преобразование становится в этом случае арифметическим вычислением, алгоритмом в таких моделях является вычисление значения некоторой числовой функции, а его элементарные шаги — арифметические операции.
Последовательность шагов определяется двумя способами. Первый способ — суперпозиция, т.е. подстановка функции в функцию, а второй — рекурсия, т.е. определение значения функции через «ранее» вычисленные значения этой же функции. Функции, которые можно построить из целых чисел и арифметических операций с помощью суперпозиций и рекурсивных определений, называются рекурсивными функциями. Например: n! (n+1)
Второй. Основные составные части машины Тьюринга: (УУ) — управляющее устройство, 1 — лента, 2 - головка;
А = { а 1 ... а m}— алфавитмашины; Q= {q1… qn} — множество состояний машины (точнее, головки), среди которых выделяют начальное q1 и конечное qz
Третий. Для нормального алгоритма задается алфавит, над которым он работает, конечное множество допустимых подстановок и правила их применения:
1) проверить возможность подстановок в порядке возрастания их номеров, и если она возможна (левая часть подстановки обнаружена в исходном слове), произвести подстановку (заменив левую часть на правую);
2) если в примененной подстановке имеется символ «!», то
преобразования прекращаются, а если нет, то текущее состояние становится исходным и весь процесс начинается заново;
3) если ни одна подстановка не применима, то процесс преобразования завершен.
Описание машины Тьюринга
Машина Тьюринга состоит из трех частей: ленты, головки и управляющего устройства. Лента бесконечна в обе стороны и разбита на ячейки. В каждой ячейке может быть записан только один символ. Отсутствие символа в ячейке обозначается специальным «пустым» символом, например, «».
Головка всегда располагается над некоторой ячейкой ленты. Она может читать и писать символы, стирать их и перемещаться вдоль ленты как вправо так и влево.
Пример машинной модели (алгоритм сложения)
Пусть m и n неотрицательные целые числа произвольной длины.
Числа представляются счётно-импульсным кодом, т.е. количеством 1, равных m или, соответственно, n.
Необходимо построить алгоритм вычисления m+n.
Зададим алфавит машины Тьюринга:
А = { #, 1, 0 }, где
# - отсутствие символа в ячейке ленты
1 - символ кода числа
0 – символ разделения двух чисел
Начальная конфигурация q1 a1
Конечная конфигурация a2 qk
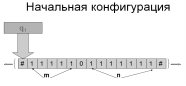
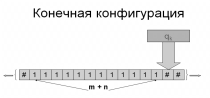 Покажем, что число 4 характеризует сложность алгоритма сложения и не зависит от длины входных данных. Для этого запишем набор команд машины Тьюринга и найдем необходимое число внутренних состояний машины.
Покажем, что число 4 характеризует сложность алгоритма сложения и не зависит от длины входных данных. Для этого запишем набор команд машины Тьюринга и найдем необходимое число внутренних состояний машины.
Команды машины: qiak > qjaldp
q1# > q1# R R – Right
q11 > q11 R
q10 > q21 R
q21 > q21 R
q2# > q3# L L – Left
q31 > q4# S S - Stop
Алгоритмы Маркова
зададим алгоритм преобразования исходного слова «СЛОН»
в слово «МУХА» по следующей цепочке:
«СЛОН» —» «СУОН» — > «МУОН» —> «МУХН» —» «МУХА».
Используя множество подстановок
1. Я - У 2. Л - У 3. С - М 4. В - Б 5. Р - Т 6. Т - Р! 7. О-Х 8. Н - А
Понятие алгоритмически неразрешимой задачи
Появление точного понятия алгоритма позволило сформулировать алгоритмически не разрешимые проблемы, т.е. задачи, для решения которых невозможно построить алгоритм. Задача называется алгоритмически неразрешимой, если не существует машины Тьюринга (или рекурсивной функции, или нормального алгоритма Маркова), которая её решает. Например, неразрешимой оказалась проблема распознавания эквивалентности алгоритмов: нельзя построить алгоритм, который по любым двум алгоритмам (программам) выяснял бы, вычисляют они одну и ту же функцию или нет. Знание основных неразрешимостей теории алгоритмов необходимо для специалиста по информатике. Оно предостережёт его от увлечения глобальными прожектами всеобщей алгоритмизации точно так же, как знание основных законов физики предостерегает от попыток создания вечного двигателя.
Раздел 3 (Лекции 4-5)
Системы счисления
В вопросах организации обработки информации на ЦВМ важное место занимают системы счисления, формы представления данных, специальное кодирование чисел.
Системой счисления называется совокупность приемов наименования и записи чисел.
Системы счисления различаются выбором алфавита, базисных чисел и правилами образования из них остальных чисел.
Алфавит систем счисления
Напомним, что алфавитом называется фиксированный конечный (упорядоченный) набор символов любой природы.
В современных системах счисления используется алфавит, включающий как арабские цифры 0, 1, 2, …9., так и буквы латинского алфавита, например, I, V, X, L, C, D, M и т.д.
Базисные числа систем счисления
В любой системе счисления каждому символу из набора алфавита – букве - приписывается базисное число. Например, в римской системе используются буквы I, V, X, L, С, D, М, которым соответствуют базисные числа 1, 5, 10, 50, 100, 500, 1000.
В 16-чной системе счисления используется алфавит, состоящий из 9 арабских цифр и 6 латинских букв: 0, 1, 2, 3, …9, A, B, C, D, E, F. Базисные числа 0, 1, 2, 3, …9, 10, 11, 12, …15.
Аддитивно-мультипликативные системы счисления
Системы счисления, в которых любое число получается путем умножения и сложения базисных чисел, называются аддитивно-мультипликативными.
Все известные позиционные системы счисления являются аддитивно-мультипликативными. Особенно отчетливо аддитивно-мультипликативный способ образования чисел из базисных выражен в числительных русского языка, например пятьсот шестьдесят восемь (т.е. пять сотен плюс шесть десятков плюс восемь).
Позиционные системы счисления
Для изображения (или представления) чисел в настоящее время используются в основном позиционные системы счисления.
Система называется позиционной, если числовое значение каждой буквы алфавита зависит не только от приписанного ей базисного числа, но и от ее положения (позиции) в слове, изображающем число.
Основание позиционной системы счисления
Число К единиц какого-либо разряда, объединяемых в единицу более старшего разряда, называют основанием позиционной системы счисления, а сама система счисления называется К-ичной.
Например, основанием десятичной СС является число К =10, троичной – число К =3, двоичной – число К =2, шестнадцатеричной – число К =16. В Древнем Вавилоне широко использовалась система счисления с основанием К =60.
Запись и изображение произвольного числа X в К-ичной позиционной системе счисления
Запись произвольного числа X в К-ичной позиционной системе счисления основывается на представлении этого числа в виде полинома:
где каждый коэффициент аi может быть одной из букв алфавита данной СС и изображается одним знаком.
Число X, представленное в К -ичной системе счисления, можно кратко записать писать в виде
аnаn-1...а1а0.а-1...а-т...
т.е. путем перечисления всех коэффициентов полинома с указанием позиционной точки.
Изображением числа X в К-ичной системе счисления является запись вида:
аnаn-1...а1а0.а-1...а -т... -к
где аi - любая буква алфавита данной системы счисления,
количество букв в К-ичной системе счисления равно К.
Упорядоченной последовательности букв алфавита приписываются базисные числа: последовательные целые числа от нуля до К-1 включительно, 0 ≤ |аi | ≤ К-1, поскольку только в этом случае любое число Х может быть представлено в виде полинома.
Двоичная система счисления
В современной вычислительной технике, в устройствах автоматики и связи широко используется двоичная система счисления. Это система счисления с наименьшим возможным основанием. В ней для изображения числа используются только две цифры: 0 и 1.
Двоичная система удобна потому, что:
простота технической реализации
простота арифметических операций
простота шифрования.
Система неудобна из-за громоздкости записи чисел. Однако для ЭВМ этот факт не имеет существенного значения
Арифметические операции в двоичной системе счисления

Постановка задачи перевода чисел из одной системы счисления в другую
При решении задач с помощью ЭВМ исходные данные обычно задаются в десятичной системе счисления; в этой же системе, как правило, нужно получить и окончательные результаты.
При рассмотрении правил перевода чисел из одной системы счисления в другую ограничимся только такими системами счисления, у которых базисными числами являются последовательные целые числа от 0 до Р-1 включительно, где Р — основание системы счисления.
Пусть известна запись числа Х в системе счисления с каким-либо основанием Р:
pnpn-1...p1p0.p-1...p-т...
где pi – известные буквы, 0 ≤ |pi | ≤ P-1.
Требуется найти запись этого же числа X в системе счисления с основанием Q:
qnqn-1...q1q0.q-1...q-т...
где qi – искомые буквы, 0 ≤ |qi | ≤ Q-1
Перевод целых чисел
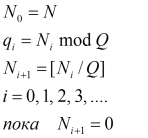
Перевод дробных чисел
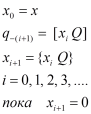
Понятие смешанной системы счисления
В ряде случаев числа, заданные в СС с основанием P, приходится изображать с помощью цифр другой СС с основанием Q, где Q < P.
Такая ситуация возникает, например, когда в ЭВМ, способной непосредственно воспринимать только двоичные числа, необходимо изобразить десятичные числа, с которыми мы привыкли работать.
В этих случаях используются смешанные системы счисления, в которых каждый коэффициент Р -ичного разложения числа записывается в Q -ичной системе.
В такой системе P называется старшим основанием, Q – младшим, а сама система называется
(Q-P)-ичной.
Условие однозначности записи чисел в смешанной системе счисления
Для того чтобы запись числа в смешанной системе счисления была однозначной, для представления любой Р-ичной цифры отводится одно и то же количество Q-ичных разрядов, достаточное для представления любого базисного числа Р-ичной системы.
Условимся изображать принадлежность числа к (Q - Р)-ичной системе счисления с помощью нижнего индекса (Q - Р) при данном числе, например
92510 = 1001 0010 0101(2 – 10)
Двоично-десятичная система
В смешанной двоично-десятичной системе счисления для изображения каждой десятичной цифры отводится 4 двоичных разряда.
Например, десятичное число х =729 в двоично-десятичной системе запишется в виде 0111 0010 1001. Здесь последовательные четверки (тетрады) двоичных разрядов изображают цифры
7, 2, 9 записи числа в десятичной системе.
Еще пример: 92510 = 1001 0010 0101(2 – 10)
Заметим, что 1001001001012 = 234110
Двоично-шестнадцатеричная система
Двоично-шестнадцатеричная система: 2E. 9 1 6 = 0010 1110.1001(2-16)
Свойство смешанных систем и использование его в практических целях
Особого внимания заслуживает случай, когда Р = Ql, где / — целое положительное число.
В этом случае запись какого-либо числа в смешанной системе тождественно совпадает с изображением этого числа в системе счисления с основанием Q (что не имеет места в двоично-десятичной системе в общем случае).
Двоично-восьмеричная система 57.58 =101 111.101 (2-8) = 101111.101 2
Двоично-шестнадцатеричная система 2E. 9 1 6 = 0010 1110.1001(2-16) = 101110.10012
Двоично-четверичная система 232.34= 10 11 10. 11 (2-4) = 101110.11 2
Рассмотренное выше свойство используется на практике для сокращенной записи чисел, заданных в системе счисления с небольшим основанием.
Для этого в исходной записи числа разряды объединяются вправо и влево от точки в группы длиной l (добавляя в случае необходимости левее старшей или правее младшей значащих цифр соответствующее количество нулей), и каждая такая группа записывается одной цифрой другой системы, основание которой равно соответствующей степени l исходного основания.
Цели кодирования информации
Цели кодирования информации
Формирование представления информации называется ее кодированием. В более узком смысле под кодированием понимается
переход от исходного представления информации, удобного для восприятия человеком, к представлению, удобному для хранения, передачи и обработки. В этом случае обратный переход к исходному представлению называется декодированием.
При кодировании информации ставятся следующие цели:
удобство физической реализации;
удобство восприятия;
высокая скорость передачи и обработки;
экономичность, т.е. уменьшение избыточности сообщения;
надёжность, т.е. защита от случайных искажений;
сохранность, т.е. защита от нежелательного доступа к информации.
Эти цели часто противоречат друг другу
Назначение памяти ЭВМ
Для записи, хранения и выдачи по запросу информации, обрабатываемой с помощью ЭВМ, предназначено запоминающее устройство (или память) ЭВМ: информация в памяти ЭВМ записывается в форме цифрового двоичного кода.
Количество информации, которое может помещаться в один элемент памяти (0 или 1), называемое битом, очень мало и не несёт смысловой нагрузки.
Машинное слово
Однако если соединить несколько таких элементов в ячейку, то тогда можно сохранить в запоминающем устройстве столько информации, сколько потребуется. Последовательность битов, рассматриваемых аппаратной частью ЭВМ как единое целое, называется машинным словом.
Ёмкость памяти
Так как оперативная память ЭВМ состоит из конечной последовательности машинных слов, а машинное слово — из конечной последовательности битов, то объем представляемой в ЭВМ информации ограничен ёмкостью памяти, а числовая информация в ЭВМ может быть представлена только с определённой точностью, зависящей от архитектуры памяти данной ЭВМ.
Свойства числовой системы ЭВМ
Рассмотрим слово 0000, представляющее десятичное число 0. В результате увеличения содержимое этого слова станет равным 0001, что соответствует десятичному числу 1. Продолжая последовательно увеличивать 4-битовые слова, придём к ситуации, когда, увеличивая слово 1111 (которое представляет десятичное число 15), получим в результате слово 0000, поскольку 111+1 = 0000 (15+1=0), при этом получили неверную арифметическую операцию и вернулись в исходное состояние.
Это произошло из-за того, что слово памяти может состоять только из конечного числа битов. Таким образом, числовая система ЭВМ является конечной и цикличной.
Числовая система ЭВМ без знака и со знаком
Введём основные понятия на примере 4-битовых машинных слов. Такой размер слова обеспечивает хранение десятичных чисел только от 0 до 15 и поэтому не представляет практического значения. Однако они менее громоздки, а основные закономерности, обнаруженные на примере 4-битовых слов, сохраняют силу для машинного слова любого размера (8, 16, 32, 64, 128 – битовых).
Предположим, что процессор ЭВМ способен увеличивать (прибавлять 1) и дополнять (инвертировать) 4-битовые слова.
Например, результатом увеличения слова 1100 является 1101, а результатом дополнения этого слова является 0011.
Ситуации, приводящей к неверному арифметическому результату, можно избежать, если битовую конфигурацию 1111 принять за код для числа -1. Тогда 1110 интерпретируется как -2; 1101 как -3 и т.д. до 1000 как -8.
Тем самым получили другую числовую систему ЭВМ — со знаком, содержащую как положительные, так и отрицательные числа. В этой системе половина четырехбитовых конфигураций, начинающаяся с единицы, интерпретируется как отрицательные числа, а другая половина, начинающаяся с 0, как положительные числа или нуль.
Поэтому старший бит числа (третий по счету, если нумерацию битов начинать с нуля справа налево) называется знаковым битом.
Операция дополнения до двух

Контроль правильности выполнения арифметических операций с помощью индикаторов переноса и переполнения
Рассмотрим более подробно ситуацию, приводящую при увеличении четырехбитового числа (т.е. прибавления к нему 1) к неверному арифметическому результату, возникшую из-за конечности числовой системы ЭВМ.
В числовой системе без знака эта проблема возникает при увеличении слова 1111, при этом имеет место перенос единицы из знакового бита. В случае системы чисел со знаком перенос из старшего бита даёт верный результат: 1111 + 0001 = 0000 (что правильно: -1 + 1 = 0). Но в этой системе увеличение слова 0111 приводит к ошибочной ситуации: 0111 + 1 = 1000 (7 + 1 = - 8), при этом имеет место перенос в знаковый бит.
В процессоре ЭВМ (точнее в АЛУ, в котором выполняются арифметические операции) содержатся два индикатора — индикатор переноса и индикатор переполнения. Каждый индикатор содержит 1 бит информации и может быть процессором установлен (в этом случае ему придается значение, равное 1) или сброшен (равен 0).
Индикатор переноса указывает на перенос из знакового бита, а индикатор переполнения — на перенос в знаковый бит. Таким образом, после завершения операции, в которой происходит перенос в старший бит, процессор устанавливает индикатор переполнения, если такого переноса нет, то индикатор переполнения сбрасывается. Индикатор переноса обрабатывается аналогичным образом.
Операция вычитания положительных чисел
Операцию вычитания можно свести к операции сложения в силу того, что
А - В = А + (- В).
Таким образом, необходимо над вычитаемым произвести операцию дополнения до двух и сложить его с уменьшаемым.
Коды представления чисел в ЭВМ
Прямой код 0101 5
Обратный код 1010
Дополнительный код 1011 - 5
Таким образом, использование кодов позволяет операцию алгебраического сложения машинных слов свести к операции арифметического сложения.
Раздел 4 (Лекция 6)
Представление символьной информации в ЭВМ
Символьная информация обрабатывается в памяти ЭВМ в форме цифрового кода.
Например, можно обозначить каждую букву числами, соответствующими ее порядковому номеру в алфавите: А - 01, Б - 02, В - 03, Г - 04,..., Э - 30, Ю - 31, Я - 32. Точно так же можно договориться обозначать точку числом 33, запятую - 34
Так как в ЭВМ используются двоичные коды, то обозначения букв надо перевести в двоичную систему. Тогда буквы будут обозначаться следующим образом: А - 000001, Б - 000010, В - 000011, Г - 000100,..., Э - 011110, Ю - 011111, Я - 100000.
При таком кодировании любое слово можно представить в виде последовательности кодовых групп, составленных из 0 и 1.
Например, код слова «БАБА» имеет вид: 000010 000001 000010 000001
Требования к построению схем преобразования
Между множествами символов и кодов должно иметь место взаимно-однозначное соответствие, т.е. разным символам должны быть назначены разные цифровые коды, и наоборот.
Из соображений наглядности и легкости запоминания целесообразно множества символов, упорядоченных по кому-либо признаку (например, лексико - графическому), кодировать также с помощью упорядоченной последовательности чисел.
Другим важным моментом при организации кодировки символьной информации является эффективное использование оперативной памяти
(28=256 поэтому слова в 1 байт достаточно)
Распространенные схемы кодирования
BCD (Binary-Coded Decimal) – двоично-десятичный код используется для представления чисел, при котором каждая десятичная цифра записывается своим четырехбитовым двоичным эквивалентом
EBCDIC (Extended Binary-Coded Decimal Interchange Code) – расширенный двоично-десятичный код обмена информацией, который преобразует как числовые, так и буквенные строки.
Эти коды могут оказаться полезными, когда нужно преобразовать строку числовых знаков, например, строку из числовых знаков «565» в число 565, над которым затем будут производиться арифметические действия.
Код ASCII
ASCII (American Standard Code for Information Interchange) – американский стандартный код обмена информации. Этот код генерируется некоторыми внешними устройствами (принтером, АЦПУ) и используется для обмена данными между ними и оперативной памятью ЭВМ.
Стандарт: диапазон 0-127 (00-7F) международный стандарт кодировки управляющих символов и букв латинского алфавита. Расширение стандарта: диапазон 128-255 (80-FF) для кодов псевдографики и букв национальных алфавитов.
КОИ-7 – отечественная версия кода ASCII (двоичный семибитовый код обмена информацией), которая совпадает с ним, за исключением букв русского алфавита
Кодирование графической информации
В середине 50-х годов для больших ЭВМ, которые применялись в научных и военных исследованиях, впервые в графическом виде было реализовано представление данных. В настоящее время широко используются компьютерные технологии обработки графической информации.
Широкое применение получила специальная область информатики, которая изучает методы и средства создания и обработки изображений с помощью программно-аппаратных вычислительных комплексов, - компьютерная графика.
Без нее трудно представить уже не только компьютерный, но и вполне материальный мир, так как визуализация данных применяется во многих сферах человеческой деятельности. В качестве примера можно привести опытно-конструкторские разработки, медицину (компьютерная томография), научные исследования и др.
Особенно интенсивно технология обработки графической информации с помощью компьютера стала развиваться в 80-х годах
Качество кодирования
При кодировании изображения происходит его пространственная дискретизация. Все изображение разбивается на отдельные точки, каждому элементу ставится в соответствие код его цвета.
Качество кодирования будет зависеть от следующих параметров: размера точки и количества используемых цветов. Чем меньше размер точки, а, значит, изображение составляется из большего количества точек, тем выше качество кодирования. Чем большее количество цветов используется (т. е. точка изображения может принимать больше возможных состояний), тем больше информации несет каждая точка, а, значит, увеличивается качество кодирования.
Виды представления графических изображений (растровое, векторное, фрактальное, 3D графика)
Создание и хранение графических объектов возможно в нескольких видах - в виде векторного, фрактального или растрового изображения.
Отдельным видом считается 3D (трехмерная) графика, в котором сочетаются векторный и растровый способы формирования изображений. Она изучает методы и приемы построения объемных моделей объектов в виртуальном пространстве. Для каждого вида используется свой способ кодирования графической информации.
Растровая графика
Самый простой способ представления изображения в цифровом виде состоит в том, чтобы каждый элемент изображения (точку) описать отдельно. Описание точки это описание ее цвета. Все изображения, представленные таким способом, называют растровыми. Фотографии, произведения живописи, картинки с плавными переходами цветов обычно представляются в компьютере как растровые изображения.
Точность передачи изображения зависит от количества точек и их размера. После разбиения рисунка на точки, начиная с левого угла, двигаясь по строкам слева направо, можно кодировать цвет каждой точки. Принято точку называть пикселем (происхождение связано с английской аббревиатурой " picture element" - элемент рисунка).
Объем растрового изображения определяется умножением количества пикселей на информационный объем одной точки, который зависит от количества ее возможных цветов.
Так как яркость каждой точки и ее линейные координаты можно выразить с помощью целых чисел, то можно сказать, что этот метод кодирования позволяет использовать двоичный код для того чтобы обрабатывать графические данные.
Векторная графика
Векторное изображение - это графический объект, состоящий из элементарных отрезков и дуг. Базовым элементом изображения является линия. Как и любой объект, она обладает свойствами: формой (прямая, кривая), толщиной., цветом, начертанием (пунктирная, сплошная). Замкнутые линии имеют свойство заполнения (или другими объектами, или выбранным цветом). Все прочие объекты векторной графики составляются из линий.
Так как линия описывается математически как единый объект, то и объем данных для отображения объекта средствами векторной графики значительно меньше, чем в растровой графике. Информация о векторном изображении кодируется как обычная буквенно-цифровая и обрабатывается специальными программами.
К программным средствам создания и обработки векторной графики относятся следующие: Corel Draw, Adobe Illustrator, а также векторизаторы (трассировщики) - специализированные пакеты преобразования растровых изображений в векторные.
Фрактальная графика
Фрактальная графика основывается на математических вычислениях, как и векторная. Но в отличии от векторной ее базовым элементом является сама математическая формула. Это приводит к тому, что в памяти компьютера не хранится никаких объектов и изображение строится только по уравнениям. При помощи этого способа можно строить простейшие регулярные структуры, а также сложные иллюстрации, которые имитируют ландшафты.
Системы кодирования цветных изображений: HSB, RGB и CMYK
Применяют несколько систем кодирования: HSB, RGB и CMYK. Первая система проста, интуитивно понятна и удобна для человека, вторая наиболее удобна для компьютера, а последняя система CMYK - для типографий.
Использование этих систем кодирования связано с тем, что световой поток может формироваться излучениями, представляющими собой комбинацию " чистых" спектральных цветов: красного, зеленого, синего или их производных.
Различают аддитивное цветовоспроизведение (характерно для излучающих объектов). В качестве примера такого объекта можно привести электронно-лучевую трубку монитора.
И субтрактивное (вычислительное) цветовоспроизведение (характерно для отражающих объектов). В качестве примера объекта этого типа можно привести полиграфический отпечаток.
Система RGB
Известно, что любой цвет можно представить в виде комбинации трех цветов: красного (Red, R), зеленого (Green, G), синего (Blue, B). Другие цвета и их оттенки получаются за счет наличия или отсутствия этих составляющих.
Данная цветовая модель является аддитивной, то есть любой цвет можно получить сочетанием основных цветов в различных пропорциях. При наложении одного компонента основного цвета на другой яркость суммарного излучения увеличивается.
Если совместить все три компоненты, то получим ахроматический серый цвет, при увеличении яркости которого происходит приближение к белому цвету.
При 256 градациях каждого цвета (точка изображения кодируется 3 байтами – 24-х битный цвет) минимальные значения RGB (0, 0, 0) соответствуют черному цвету, а белому - максимальные с кодами (255, 255, 255).
Чем больше значение байта цветовой составляющей, тем этот цвет ярче. Например, темно-синий кодируется тремя байтами (0, 0, 128), а ярко-синий (0, 0, 255).
Система CMYK
Эта цветовая модель используется при выводе изображений на печать. Каждому из основных цветов ставится в соответствие дополнительный цвет (дополняющий основной до белого). Получают дополнительный цвет за счет суммирования пары остальных основных цветов. Дополнительным цветом
для красного является голубой (Cyan, C) = зеленый + синий = белый - красный, для зеленого - пурпурный (Magenta, M) = красный + синий = белый - зеленый, для синего - желтый (Yellow, Y) = красный + зеленый = белый - синий.
Причем принцип декомпозиции произвольного цвета на составляющие можно применять как для основных, так и для дополнительных, то есть любой цвет можно представить или в виде суммы красной, зеленой, синей составляющей или же в виде суммы голубой, пурпурной, желтой составляющей.
В этой системе используют еще черный цвет (BlacК, так как буква В уже занята синим цветом, то обозначают буквой K). Это связано с тем, что наложение друг на друга дополнительных цветов не дает чистого черного цвета.
Система HSB
Эта система характеризуется тремя компонентами: оттенок цвета (Hue) (длина волны), насыщенность цвета (Saturation) (амплитуда волны) и яркость цвета (Brightness) (освещенность).
Можно получить большое количество произвольных цветов, регулируя эти компоненты. Эту систему применяют в графических редакторах, в которых изображения создаются, а не обрабатываются уже готовые.
Эта система хорошо согласуется с моделью восприятия цвета человеком, недостаток ее в том, что ее необходимо преобразовывать в систему RGB, если ее планируется использовать в качестве экранной иллюстрации, или CMYK, для печатной иллюстрации.
Обычно в таких редакторах значение цвета выбирается как вектор, выходящий из центра окружности. Направление вектора задается в угловых градусах и определяет цветовой оттенок. Насыщенность цвета определяется длиной вектора, а яркость цвета задается на отдельной оси, нулевая точка которой имеет черный цвет. Точка в центре соответствует белому (нейтральному) цвету, а точки по периметру - чистым цветам.
Режимы представления цветной графики (полноцветный, индексный)
Различают режимы представления цветной графики:
а) полноцветный (True Color);
б) High Color;
в) индексный.
При полноцветном режиме для кодирования яркости каждой из составляющих используют 256 кодов яркости (восемь двоичных разрядов), то есть на кодирование цвета одного пикселя (в системе RGB) надо затратить 8*3=24 разряда. Это позволяет однозначно определять 16, 5 млн. цветов. Что довольно близко к чувствительности глаза человека.
При кодировании с помощью системы CMYK для представления цветной графики надо иметь 8*4=32 двоичных разряда.
Режим High Color - это кодирование при помощи 16-разрядных двоичных чисел. При этом режиме значительно уменьшается диапазон кодируемых цветов (65 636 цветов – 16-ти битный цвет).
При индексном режиме кодирования цвета можно передать всего лишь 256 цветовых оттенков. Каждый цвет кодируется при помощи восьми бит данных.
Понятно, что 256 оттенков цвета не передают весь диапазон цветов, доступный человеческому глазу, поэтому подразумевается, что к графическим данным прилагается палитра (справочная таблица), без которой воспроизведение будет неадекватным: море может получиться красным, а листья - синими.
Сам код точки растра в данном случае означает не сам по себе цвет, а только его номер (индекс) в палитре. Отсюда и название режима - индексный.
Кодирование звуковой информации
Еще древнегреческий философ и ученый - Аристотель, исходя из наблюдений, объяснял природу звука, полагая, что звучащее тело создает попеременное сжатие и разрежение воздуха.
Так, колеблющаяся струна то разряжает, то уплотняет воздух, а из-за упругости воздуха эти чередующиеся воздействия передаются дальше в пространство - от слоя к слою, возникают упругие волны. Достигая нашего уха, они воздействуют на барабанные перепонки и вызывают ощущение звука.
На слух человек воспринимает упругие волны, имеющие частоту где-то в пределах от 16 Гц до 20 кГц (1 Гц - 1 колебание в секунду). В соответствии с этим упругие волны в любой среде, частоты которых лежат в указанных пределах, называют звуковыми волнами или просто звуком.
Аналого-цифровое преобразование звука
Звуковые волны при помощи микрофона превращаются в аналоговый переменный электрический сигнал.
Аналого-цифровой преобразователь (АЦП) – это устройство, которое переводит сигнал в цифровую форму. В упрощенном виде принцип работы АЦП заключается в следующем: через определенные промежутки времени измеряется амплитуда сигнала и далее сохраняется в памяти последовательность чисел, несущих информацию об изменениях амплитуды.
Термином семпл (Sample) называют как промежуток времени между двумя измерениями амплитуды аналогового звукового сигнала, так и последовательность цифровых данных, которые получили путем аналого-цифрового преобразования звука.
Сам процесс преобразования называют семплированием, на русском техническом языке это обычная дискретизация.
Важными параметрами семплирования являются два: частота и разрядность. Частота - количество измерений амплитуды аналогового сигнала в секунду. Разрядность указывает с какой точностью сохраняются изменения амплитуды аналогового сигнала.
Именно от разрядности зависит достоверность восстановления формы волны.
Значения разрядности для звука
Обычно используют 8, 16-битное или 24-битное представление значений амплитуды.
8-битное кодирование, позволяет достичь точность изменения амплитуды аналогового сигнала до 1/256 от динамического диапазона цифрового устройства. Применяют в мультимедийных приложениях, где не требуется высокое качество звука.
Если использовать 16-битное кодирование для представления значений амплитуды звукового сигнала, то точность измерения возрастет в 256 раз. Используется при записи компакт-дисков.
В качественных преобразователях принято использовать 24-битное кодирование сигнала, что позволяет получать высококачественную оцифровку звука.
Форматы данных в ЭВМ
Данные, обрабатываемые ЭВМ, делятся на три группы:
1.логические коды,
2.числа с фиксированной запятой,
3.числа с плавающей запятой.
Представление логических кодов и структура разрядной сетки
Логическими кодами могут быть представлены символьные величины, числа без знака и битовые величины
Логические коды могут размещаться в отдельных байтах и в словах
Для их представления используются все разряды: для байта от 0-го до 7-го, для слова из 2 байт – от 0-го до 15-го, причем старший разряд всегда содержит 0.
Числа без знака имеют диапазон представления от 000 до 3778 – для байта, от 000000 до 1777778 – для слова
Представление чисел в формате с фиксированной запятой и особенности данного формата
Структура разрядной сетки:
Особенности данного формата:
1.Переполнение разрядной сетки
При выполнении операций над числами, представленными в формате с фиксированной запятой, они масштабируются таким образом, чтобы каждое число лежало в интервале (-1, +1)
При этом необходимо следить за тем, чтобы в результате операций результат не получился большим, чем 2k-1, где k – число разрядов, отведенных для представления чисел в памяти ЭВМ
Такая опасность есть при выполнении операций сложения и деления, когда возможен случай переполнения разрядной сетки: результат по модулю > 1.
2.Появление машинного нуля
Опасность представляют также операции вычитания и умножения. При вычитании может получиться так, что разность станет числом меньшим, чем представляется в машине, и результат исчезнет. При многократном умножении (из-за того, что умножаются числа, меньшие единицы) может произойти то же самое.
Поэтому при использовании формата представления чисел с фиксированной запятой приходится следить также за случаями, связанными с появлением машинного нуля.
3.Накопление абсолютной погрешности
Неизбежным при использовании такого формата является процесс накопления абсолютной погрешности вычислений из-за перемасштабирования, при котором цифры младших разрядов (а именно в них накапливается абсолютная погрешность) передвигаются в старшие разряды.
Все перечисленные выше недостатки привели к тому, что в универсальных ЭВМ представление чисел с фиксированной запятой практически перестало применяться.
Оно сохраняется в специализированных ЭВМ, где диапазон изменения чисел заранее проанализирован, а также в некоторых микропроцессорах и микро–ЭВМ.
4.Аппаратная реализация арифметических операций с числами в формате с фиксированной запятой намного проще, чем с числами в формате с плавающей запятой.
5.При этом существуют ЭВМ как с дробной арифметикой (n=0), так и
с целочисленной (m=0).
Представление чисел в формате с плавающей запятой
Любое вещественное число x, представленное в системе счисления с основанием K, можно записать в виде:
где m – мантисса, p – характеристика (или порядок) числа.
Если |m|< 1, то запись числа называется нормализованной слева.
 Запись числа называют нормализованной справа, если после запятой в мантиссе стоит не нуль
Запись числа называют нормализованной справа, если после запятой в мантиссе стоит не нуль
Процедура нормализации справа
В ЭВМ с целью минимизации погрешности при вычислениях и эффективного использования памяти применяют процедуру нормализации справа.
В дальнейшем под нормализацией записи числа будем понимать нормализацию справа: после запятой в мантиссе стоит не нуль.
Структура разрядной сетки
Выполнение арифметических операций над числами, представленными в формате с плавающей запятой
При выполнении арифметических операций над числами, представленными в формате с плавающей запятой, надо отдельно выполнять их для порядков и мантисс.
При алгебраическом сложении чисел надо сначала уравнять порядки слагаемых и мантиссы сложить.
При умножении порядки надо складывать, а мантиссы перемножать.
При делении из порядка делимого вычитают порядок делителя, а над мантиссами совершают обычную операцию деления.
Сравнение форматов чисел с фиксированной и плавающей запятой
Понятно, что арифметические операции с числами в формате с плавающей запятой намного сложнее таких же операций для чисел в формате с фиксированной запятой.
Но зато плавающая запятая позволяет производить операции масштабирования автоматически в процессоре ЭВМ, что избавляет от накопления абсолютной погрешности при вычислениях (хотя не избавляет от накопления относительной погрешности).
Раздел 5 (Лекция 7)
Общая характеристика процесса восприятия информации
Восприятие информации - процесс преобразования сведений, поступающих в техническую систему или живой организм из внешнего мира, в форму, пригодную для дальнейшего использования. Благодаря восприятию информации обеспечивается связь системы с внешней средой. Восприятие информации необходимо для любой информационной системы.
|
|