Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
МВК с разделенной памятью.
|
|
Если в каждом вычислительном узле использовать только “собственную” оперативную память, то не будет ограничений на “масштабирование” такой системы и, соответственно, на количество параллельно выполняемых ветвей (процессов) решаемой задачи, выполняемых в узлах системы. В то же время общее время решения задачи может существенно зависеть от эффективности передачи данных между ветвями (процессами) через объединяющую процессоры коммуникационную систему.
Естественно, что размещение программ и данных задачи по вычислительным узлам и организация передач данных (поддерживаемых операционной системой) между узлами вызывает определенные затруднения при программировании решения задачи.
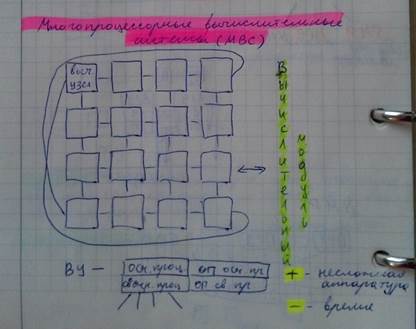
Описанные системы образуют подкласс MPP (Massively Parallel Processor). Многие из них содержат тысячи и десятки тысяч процессоров. Имеется много различных топологий объединения процессоров в MPP- системах: “линейка”, “ кольцо”, “решетка”, многомерные “торы”, “гиперкуб”, “полный граф” соединений и др.
Представляет интерес сравнение двух последних указанных топологий: гиперкуба и полного графа соединений. Гиперкуб ранга n имеет число вершин (вычислительных узлов), равное 2 в степени n. Отношение числа связей (объемов оборудования) гиперкуба к полному графу при одинаковом числе узлов при росте величины n определяет существенное преимущество гиперкуба. Максимальная длина “транзита” данных в гиперкубе (число проходимых связей при передаче сообщения) равна n (в полном графе она всегда равна 1). Эта величина (соответственно и время передачи данных) растет не столь быстро по сравнению с ростом объема оборудования для полного графа. Поэтому во многих случаях реальные MPP – системы строились по топологии гиперкуба.
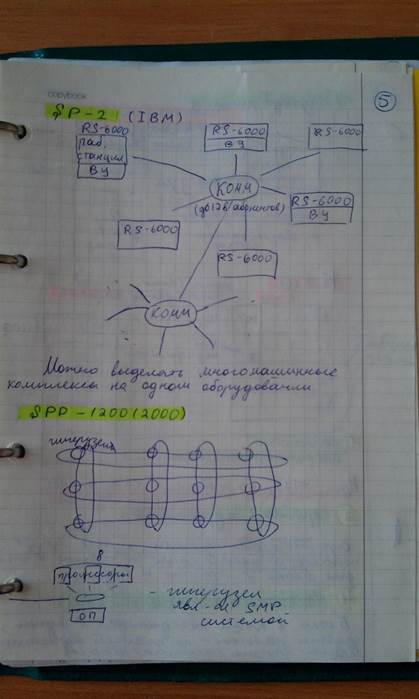
Примерами MPP–систем являются системы IBM RS/6000 SP2, Intel PARAGON/ASCI Red, CRAY T3E, Hitachi SR8000.
Успешным оказалось построение фирмой IBM MPP–системы с использованием центрального коммутатора (система IBM RS/6000 SP2). К нему подсоединяются до 128 вычислительных узлов, в качестве которых использовались рабочие станции RS6000 (без внешних устройств и, соответственно, оборудования связи с ними или с полным комплектом оборудования для обеспечения ввода информации в систему и вывода результатов вычислений). Такое гибкое решение позволяло также реализовать в системе с одним коммутатором как многопроцессорные, так и многомашинные подсистемы.
Другим интересным примером организации MPP – системы являются созданные под руководством академика Левина Владимира Константиновича отечественные системы МВС-100 и МВС-1000 (различаются лишь типом используемого процессора), вычислительные модули которых состоят из 16 узлов, соединяемых по топологии “решетка” с дополнительными двумя связями между противоположными “угловыми” узлами. Каждый узел содержит основной вычислительный процессор и его оперативную память, а также “связной” процессор с собственной памятью, обеспечивающий в узле прием-передачу данных. Свободные связи узлов используются для соединения вычислительных модулей друг с другом и подключения к системе «внешних» компьютеров.
Решение проблемы ввода-вывода информации в многопроцессорных вычислительных системах любого типа (SMP, NUMA, MPP) осуществляется за счет подключения к системе внешних (дополнительных) компьютеров, обеспечивающих выполнение этой функции, с соответствующим согласованием работы их системного программного обеспечения с системным программным обеспечением мультипроцессора.
Следует отметить, что одной из первых в мире MPP–систем была разработанная в Киеве в Институте кибернетики им. В.М.Глушкова “макроконвейерная ЭВМ” (ЕС-2701), в которой вычислительные узлы на базе стандартных процессоров ЕС ЭВМ (на них выполнялись основные вычисления) объединялись через систему коммутаторов с так называемыми специальными “логическими” узлами, в которых выполнялись части программы решения задачи, обеспечивающие управление процессом ее решения.
В MPP-системах Cray T3E и Cray T3D процессорные узлы объединены в топологии трехмерного тора. Каждая элементарная связь между двумя узлами - это два однонаправленных канала передачи данных, что допускает одновременный обмен данными в противоположных направлениях.
MPP-системы строятся и на базе векторно-конвейерных процессоров (параллельные векторные системы - PVP). К этому подклассу относится линия векторно-конвейерных компьютеров CRAY: CRAY J90/T90, CRAY SV1, CRAY X1, системы NEC SX-4/SX-5, серия Fujitsu VPP.
В некоторых MPP–системах виртуальная память, предоставляемая задаче и используемая процессором вычислительного узла лишь в физической памяти этого узла, может быть отражена в оперативных памятях многих узлов. При возникновении в каком-либо узле потребности в конкретной части виртуальной памяти задачи эта часть передается по внутрисистемным коммуникациям в физическую оперативную память данного узла.
 (спасибо Тиме(((=)
(спасибо Тиме(((=)
|
|