Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Архитектура микропроцессоров Intel P6 и Р7. Конвейеризация вычислительных процессов, использование кэш-памяти программ и данных, предсказание ветвлений и спекулятивное выполнение.
|
|
Процессоры семейства Р6, продолжая общую линию микропроцессоров Intel 80x86, имеют ряд архитектурных и структурных особенностей по сравнению с предыдущими моделями микропроцессоров фирмы Intel. Наиболее характерными из этих особенностей являются:
• гарвардская структура с разделением потоков команд и данных с помощью введения отдельных внутренних блоков кэш-памяти для хранения команд и данных, а также шин для их передачи;
• суперскалярная архитектура, обеспечивающая одновременное выполнение нескольких команд в параллельно работающих исполнительных устройствах;
• динамическое исполнение команд, реализующее изменение последовательности команд (выполнение команд с опережением — спекулятивное выполнение), использование расширенного регистрового файла (переименование регистров), эффективное предсказание ветвлений;
• двойная независимая шина, содержащая отдельную шину для обращения к кэш-памяти 2-го уровня (выполняется с тактовой частотой процессора) и системную шину для обращения к памяти и внешним устройствам (выполняется с тактовой частотой системной платы).
Процессоры семейства Р6 имеют следующие характеристики:
• 32-разрядная внутренняя структура;
• использование системной шины с 36 разрядами адреса и 64 разрядами данных;
• раздельная внутренняя кэш-память 1-го уровня (L1) для команд и данных емкостью по 16 Кбайт;
• поддержка общей кэш-памяти команд и данных 2-го уровня (L2) емкостью до 2 Мбайт;
• конвейерное исполнение команд с реализацией 12 ступеней конвейера;
• предсказание направления программного ветвления с высокой точностью;
• ускоренное выполнение операций с плавающей точкой;
• приоритетный контроль при обращении к памяти (защищенный режим);
• поддержка реализации мультипроцессорных систем;
• наличие внутренних средств, обеспечивающих самотестирование, отладку и мониторинг производительности.
Конвейерная обработка представляет собой процесс, при кото- ром сложные действия разделяются на более короткие стадии. Их параллельное выполнение позволяет более полно использовать об- рабатывающие ресурсы конвейера.
В процессорах Р6 реализован конвейер команд с 12 ступенями их выполнения.
При прохождении семи первых ступеней (до блока изменения последовательности ROB) сохраняется исходный порядок следования команд, на трех исполнительных ступенях последовательность команд может быть нарушена, две заключительные ступени обеспечивают запись полученных результатов в память или регистры с восстановлением исходного порядка их следования. Такое восстановление выполняется буферным блоком MOB при записи результатов в память или блоками изменения последовательности и распределения команд (ROB и RS) при записи результатов в регистр (блок RRF).
Последовательная работа конвейера команд нарушается при поступлении команд условных переходов, так как в случае выполнения условия перехода, которое проверяется в исполнительном устройстве, потребуется перезагрузка конвейера — очистка всех предыдущих ступеней и выборка команды из новой ветви программы. Чтобы сократить или исключить потери времени, связанные с перезагрузкой длинного 12-ступенчатого конвейера, используется блок предсказания ветвлений. Его основной частью является ассоциативная память, называемая буфером адресов ветвлений (ВТВ — Branch Target Buffer), в которой хранятся 512 адресов ранее выполненных переходов. Кроме того ВТВ содержит четыре бита предыстории ветвления, которые указывают, выполнялся ли переход при четырех предыдущих выборках данной команды. При поступлении очередной команды условного перехода указанный в ней адрес сравнивается с содержимым ВТВ. Если этот адрес не содержится в ВТВ, то есть ранее не производились переходы по данному адресу, то предсказывается отсутствие ветвления. В этом случае продолжается выборка и декодирование команд, следующих за командой перехода. При совпадении указанного в команде адреса перехода с каким-либо из адресов, хранящихся в ВТВ, производится анализ предыстории. В процессе анализа определяется чаще всего реализуемое направление ветвления, а также выявляются чередующиеся переходы. Если предсказывается выполнение ветвления, то выбирается и загружается в конвейер команда, размещенная по предсказанному адресу. Одновременно в блоке выборки-декодирования сохраняется декодированная следующая команда. Если после анализа условия ветвления выясняется, что предсказание было неправильным, эта декодированная команда поступает из УУ в исполнительное устройство, обеспечивая сокращение потерь времени на перезагрузку конвейера.
Используемый алгоритм предсказания ветвлений ориентирован на достаточно частое повторение обращения к процедуре, которая обеспечивается определенной ветвью программы. При этом рекомендуется более часто используемые процедуры располагать в ветвях, следующих непосредственно за командой перехода, чтобы сократить время перезагрузки конвейера при ошибочно предсказанных ветвлениях. По имеющимся оценкам данный алгоритм обеспечивает вероятность правильного предсказания ветвлений на уровне 90%.
Обмен с основной памятью при использовании кэш-памяти производится с помощью пакетных циклов обращения, которые позволяют за один цикл переслать содержимое целой строки кэш-памяти (32 байта). Внешняя 64-разрядная шина данных позволяет выполнить такую пересылку за 5 тактов машинного времени: первый такт служит для установки адреса строки, а в течении следующих четырех тактов идет передача данных. При этом необходимые сигналы управления обменом устанавливаются только один раз (в начале цикла), а изменение младших разрядов адреса в тактах передачи осуществляется автоматически основной памятью.
При формировании адресов обеспечивается обращение к заданному сегменту памяти. Каждый сегмент может делиться на страницы, размещаемые в различных разделах адресного пространства. Блоки трансляции адреса обеспечивают формирование физических адресов команд и данных при использовании страничной организации памяти. При этом для сокращения времени трансляции используется внутренняя буферная память TLB (Translation Look-aside Buffer), которая хранит базовые адреса наиболее часто используемых страниц.
Спекулятивное выполнение инструкций - это способность процессора исполнить инструкции в порядке, отличном (как правило, с опережением) от порядка во входном потоке инструкций (что определяется кодом исполняемой программы), но завершить и возвратить (commit) результаты исполнения инструкций в порядке, соответствующем оригинальному входному потоку инструкций.
10. Организация вода – вывода данных в микропроцессорных системах.
В ЭВМ применяются три режима ввода/вывода:
· программно-управляемый ВВ (называемый также программным или нефорсированным ВВ),
· ВВ по прерываниям (форсированный ВВ)
· и прямой доступ к памяти.
Первый из них характеризуется тем, что инициирование и управление ВВ осуществляется программой, выполняемой процессором, а внешние устройства играют сравнительно пассивную роль и сигнализируют только о своем состоянии, в частности, о готовности к операциям ввода/вывода.
Во втором режиме ВВ инициируется не процессором, а внешним устройством, генерирующим специальный сигнал прерывания. Реагируя на этот сигнал готовности устройства к передаче данных, процессор передает управление подпрограмме обслуживания устройства, вызвавшего прерывание. Действия, выполняемые этой подпрограммой, определяются пользователем, а непосредственными операциями ВВ управляет процессор.
Наконец, в режиме прямого доступа к памяти, который используется, когда пропускной способности процессора недостаточно, действия процессора приостанавливаются, он отключается от системной шины и не участвует в передачах данных между основной памятью и быстродействующим ВУ.
Заметим, что во всех вышеуказанных случаях основные действия, выполняемые на системной магистрали ЭВМ, подчиняются двум основным принципам.
1. В процессе взаимодействия любых двух устройств ЭВМ одно из них обязательно выполняет активную, управляющую роль и является задатчиком, второе оказывается управляемым, исполнителем. Чаще всего задатчиком является процессор.
2. Другим важным принципом, заложенным в структуру интерфейса, является принцип квитирования (запроса - ответа): каждый управляющий сигнал, посланный задатчиком, подтверждается сигналом исполнителя. При отсутствии ответного сигнала исполнителя в течение заданного интервала времени формируется так называемый тайм-аут, задатчик фиксирует ошибку обмена и прекращает данную операцию.
Программно-управляемый ввод/вывод
Данный режим характеризуется тем, что все действия по вводу/выводу реализуются командами прикладной программы. Наиболее простыми эти действия оказываются для " всегда готовых" внешних устройств, например индикатора на светодиодах. При необходимости ВВ в соответствующем месте программы используются команды IN или OUT. Такая передача данных называется синхронным или безусловным ВВ.
Однако для большинства ВУ до выполнения операций ВВ надо убедиться в их готовности к обмену, т.е. ВВ является асинхронным. Общее состояние устройства характеризуется флагом готовности READY, называемым также флагом готовности/занятости (READY/BUSY). Иногда состояния готовности и занятости идентифицируются отдельными флагами READY и BUSY, входящими в слово состояния устройства.
Процессор проверяет флаг готовности с помощью одной или нескольких команд. Если флаг установлен, то инициируются собственно ввод или вывод одного или нескольких слов данных. Когда же флаг сброшен, процессор выполняет цикл из 2-3 команд с повторной проверкой флага READY до тех пор, пока устройство не будет готово к операциям ВВ (рис.10.1.). Данный цикл называется циклом ожидания готовности ВУ и реализуется в различных процессорах по-разному.
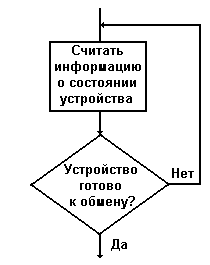
Рис. 10.1. Цикл программного ожидания готовности внешнего устройства
Основной недостаток программного ВВ связан с непроизводительными потерями времени процессора в циклах ожидания. К достоинствам следует отнести простоту его реализации, не требующей дополнительных аппаратных средств.
|
|