Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Архитектура БД Oracle.
|
|
СУБД Oracle является максимально переносимой – она доступна на всех распространенных платформах (более 50). Физическая реализация СУБД Oracle имеет различия для разных ОС (например, реализация поддержки фоновых процессов в Unix-системах отличается от реализации их в Windows), но логическая архитектура СУБД Oracle практически не зависит от платформы.

Рис. Структура экземпляра и БД
База данных и экземпляр.
Прежде всего, рассмотрим понятия «базы данных» и «экземпляра» в терминах Oracle.
База Данных Oracle – набор физических файлов ОС, в которых хранятся данные.
Экземпляр – набор процессов Oracle и область SGA, связанные с базой данных.
Экземпляр (instance) всегда связан с какой-то одной базой данных (БД). БД может обслуживаться более чем одним экземпляром (см. Oracle Real Application Clusters). Экземпляр – согласовательное звено между БД и ОС, он является своеобразным «стартером» для БД в целом. Запуск экземпляра предваряет открытие БД. Экземпляр не содержит постоянных данных, за это отвечают файлы БД. Если не используется технология Oracle Real Application Clusters, то между БД и экземпляром имеется отношение один к одному: одному экземпляру соответствует один набор файлов БД.
Процессы и потоки Windows.
Процесс (process) – механизм ОС Windows, осуществляющий запуск и выполнение приложений (в других ОС синонимом процесса являются задание (job) или задача (task)). В Windows процесс создается, когда запускается приложение. В общем случае процесс выполняется в собственной области памяти.
Поток или нить (thread) – индивидуальная ветвь внутри процесса, выполняющая конкретные программные инструкции. Внутри процесса возможна одновременная работа множества потоков, что обеспечивает реализацию многозадачности (хотя это не каноническая многозадачность, а псевдо-многозадачность).
Каждый экземпляр СУБД Oracle запускается в виде сервиса (службы) ОС, который представляет собой прописанный в реестре процесс ОС, внутри которого уже процессы Oracle (фоновые, серверные) реализуются как потоки этого сервиса (он называется oracle.exe – по имени приложения, его запустившего).
Замечание:
При рассмотрении данного вопроса важно не путать процессы ОС как механизм собственно ОС и внутренние процессы (серверные, фоновые) Oracle, реализуемые через потоки процесса ОС ‘oracle.exe’.
Режимы работы сервера.
Обычно СУБД Oracle при подключении пользователя создает новый процесс. Каждый сеанс получает в свое распоряжение отдельный, или выделенный серверный процесс (dedicated server process) сервера Oracle.
Возможна и другая конфигурация, когда небольшое число специальных разделяемых серверных процессов (shared server processes) вместе с процессами-диспетчерами обслуживают одновременно большое число пользовательских сессий, сохраняя общее количество процессов на уровне экземпляра низким. Этот режим называют режимом разделяемых серверов (Oracle Shared Server - OSS), в версии 8i он назывался режимом многопоточного сервера (Multi Threaded Server - MTS).
Режим OSS хорош для систем OLTP, где много пользовательских подключений и выполняются частые, но короткие транзакции. Для хранилищ данных лучше использовать режим выделенных серверов.
В большинстве случаев рекомендуется использовать режим OSS (особенно для Web-приложений, когда поддерживается одновременная работа большого числа пользователей). Режим работы с выделенными серверами иногда требуется для специфических операций, например, останова экземпляра, поэтому часто в СУБД Oracle 10gиспользуют возможность подключения как через выделенные серверные процессы, так и через разделяемые (более подробно см. главу «Настройка OSS»).
Основные компоненты архитектуры экземпляра БД
При рассмотрении архитектуры СУБД Oracle выделяют 3 основных компонента архитектуры:
- Структуры памяти
- Файлы
- Физические процессы.
Структуры памяти
В СУБД Oracle 10gпамять – один из главных ресурсов. Она используется для хранения:
- программного кода;
- информации о работающих сессиях;
- информации, необходимой на стадии выполнения программ (например, текущее состояние курсора, из которого извлекаются строки);
- информации о ресурсах, разделяемых процессами Oracle (например, о блокировках);
- кэшированных данных для быстрого доступа.
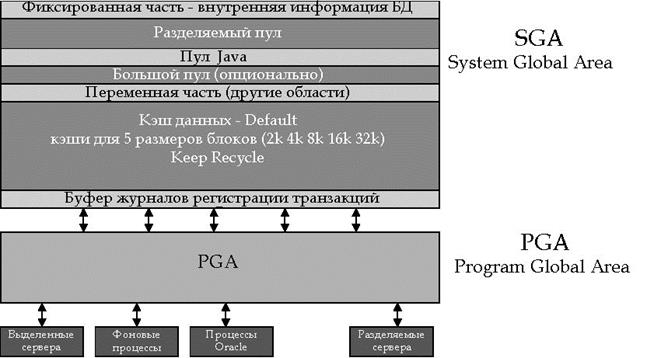
Рисунок 1. Архитектура памяти экземпляра
Основные структуры памяти экземпляра БД Oracle:
- Системная глобальная область (System Global Area (SGA)), которая разделяется всеми серверными и фоновыми процессами и содержит в себе следующие основные подобласти:
- Кэш данных (Database buffer cache);
- Буфер регистрации транзакций (Redo log buffer);
- Разделяемый пул (Shared pool);
- Большой пул (Large pool);
- Пул Java.
- Программная глобальная область (Program Global Areas (PGA)), частная для каждого фонового или серверного процесса. Для каждого процесса – своя PGA. PGA никогда не входит в состав SGA, а выделятся отдельно. Общий объем PGA для всех процессов часто называется суммарным объемом PGA (aggregated PGA memory).
В этой области содержатся:
- Область памяти сессии (session memory), содержащая информацию о соединении и другую, связанную с сессией управляющую информацию. В режиме OSS эта область разделяема.
- Частная область SQL (private SQL area). Каждая сессия, выполняющая SQL-выражения, содержит эту область. Она делится, в свою очередь, на:
- Постоянную область (persistent area), содержащую, курсоры и связываемые (bind) данные. Освобождается по закрытии курсора.
- Область времени выполнения (run-time area). Используется только в течение выполнения SQL-выражения.
- Выделяют еще рабочие области SQL (SQL work area) как часть области времени выполнения, предназначенные для обработки ресурсоемких операций (сортировки, группировки (в т.ч. с итогами), хэш-соединения, обработка битмап-индексов). Часто рабочую область называют областью сортировки (sort area), если рассматривается выполнение в ней неких сортировок, или хэш-областью (hash area), если рассматривается выполнение в ней некого хэш-соединения. Но речь идет об одном понятии – рабочей области SQL. Размер рабочей области SQL может быть настроен.
Частная область SQL является частью PGA, если установлено соединение через выделенный сервер. Если же соединение установлено через разделяемый сервер, то часть частной области SGA располагается в SGA.
Помимо частных областей SQL, Oracle позволяет всем пользовательским процессам обращаться к разделяемым областям SQL (shared SQL area), являющихся частью библиотечного кэша в разделяемом пуле (см. далее в этой главе).
Выделяется также глобальная область пользователя (User Global Area - UGA) – область памяти, связанная с сеансом. В случае работы в режиме выделенных серверных процессов UGA располагается в PGA, в случае режима OSS – в SGA. Эта область хранит состояние сеанса, поэтому он должен иметь к ней постоянный доступ. В режиме OSS UGA находится в SGA, т.к. доступ к ней должен быть обеспечен для всех сеансов, которые поочередно используют разделяемые сервера (подробнее см. главу «Настройка OSS»).
Кэш данных
Кэш данных – разделяемая область SGA, которая хранит копии блоков данных, считанные из файлов данных. Все пользовательские сессии имеют одновременный доступ к кэшу данных. Все данные, которые пользователь получает как результат выполнения какого-то SQL-выражения берутся из кэша данных.
Кэш данных предназначен для минимизации операций физического ввода-вывода (когда для получения нужных данных необходимо выполнять дополнительные дисковые операции) в пользу увеличения операций логического ввода-вывода (когда необходимые данные извлекаются из памяти). Физический ввод-вывод намного дороже логического.
При этом любой доступ к данным является логическим: только из памяти – строго логический, а ввод-вывод с диска является и физическим и логическим.
Кэш данных организован с использованием двух списков:
- Списка измененных блоков (write list);
- Списка частоты использования блоков (LRU-MRU list, (LRU – least recently used), давно использовавшийся, (MRU – most recently used), недавно использовавшийся);
Список измененных блоков содержит т.н. «грязные блоки» (dirty blocks), т.е. те, которые были изменены пользовательскими транзакциями, но еще не были записаны на диск.
Пользователи обращаются к разным блокам данных с разной частотой. Список частоты использования блоков предназначен для определения блоков, которые будут сохранены в кэше, а которые будут вытеснены из него для других блоков. В какой-то момент происходит обращение к тем или иным данным со стороны пользователей. Если необходимые данные не были обнаружены в кэше, происходит их считывание из файлов данных в кэш, откуда они передаются пользовательской сессии. При этом группа считанных блоков помещается в MRU часть списка. Когда данные помещаются в кэш впервые, как правило, они вытесняют некоторые блоки, которые к этому моменту «устарели», т.е. к которым реже всего обращались среди всех блоков в кэше данных. Эти «устаревшие» блоки расположены в LRU-части списка. Именно подобные блоки будут вытесняться новыми. Если вытесняемые блоки находятся еще и в списке измененных блоков, то перед вытеснением из кэша они обязательно будут записаны на диск (за это отвечают фоновые процессы DBW n).
Таким образом, чем чаще идет обращение к некоторым данным, тем выше вероятность того, что они будут обнаружены в кэше (произойдет т.н. попадание в кэш – cache hit), и будут извлечены из него очень быстро, без ресурсоемких дисковых операций.
Не все свежесчитанные данные помещаются сразу в MRU-часть списка. Исключение составляют случаи полного сканирования таблиц (full table scan - FTS), когда обрабатывается большое число строк, причем известно, что активного обращения к этим строкам потом не будет. Эти блоки помещаются в LRU-часть списка.
Поскольку одно из основных назначений любой СУБД – обеспечение быстрого доступа к данным, то размер кэша данных должен быть достаточным для хранения большого числа блоков данных. Как правило, кэш данных – самая большая часть SGA. Размер основного кэша данных указывается с помощью параметра инициализации DB_CACHE_SIZE.
Буфер регистрации транзакций (буфер повтора, редо-буфер)
Редо-буфер – часть SGA, в которой хранится информация об изменениях, произошедших в БД. Эти изменения вызываются транзакциями в БД (операции INSERT, UPDATE, DELETE, CREATE, ALTER, DROP), которые инициируют пользователи. Данные в нем никогда не сохраняются надолго, и время от времени (в зависимости от активности пользователей в БД), сбрасываются в файлы регистрации транзакций (журналы повтора, редо-логи) с помощью фонового процесса LGWR. Данные из редо-буфера могут быть использованы для восстановления БД в случае необходимости.
Разделяемый пул.
Разделяемый пул состоит из следующих основных областей:
- библиотечного кэша (library cache);
- кэша словаря данных (data dictionary cache);
- буфера параллельных вычислений;
- управляющих структур (например, набор символов БД);
|
|