Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Метод квадратичного рехеширования.
|
|
Отличается от линейного тем, что шаг перебора
элементов не линейно зависит от номера попытки найти свободный элемент
a = (h(key) + c*i 2) mod N
Благодаря нелинейности такой адресации количество кластеров уменьшается.
Методом цепочек называется метод, в котором для разрешения коллизий во все
записи вводятся указатели, используемые для организации списков цепочек
переполнения. В случае возникновения коллизии при заполнении таблицы в список для
требуемого адреса хеш-таблицы добавляется еще один элемент.
Поиск в хеш-таблице с цепочками переполнения осуществляется следующим
образом. Сначала вычисляется адрес по значению ключа. Затем осуществляется
последовательный поиск в списке, который связан с вычисленным адресом.
Процедура удаления из таблицы сводится к поиску элемента и его удалению из
цепочки переполнения.

20)  Рекурсивные типы данных: определение, примеры.
Рекурсивные типы данных: определение, примеры.
Пусть описан тип-запись, и одним из полей этой записи является указатель. В этот указатель можно записать адрес, по которому данная запись располагается, либо, что более интересно адрес другой записи того же типа. Это позволяет при помощи указателей создать структуру данных, называемую связанным списком.
Пример описания такой структуры данных:
| type PListElement = ^TListElement; TListElement = record < Произвольные поля записи> NextElement: PListElement; End; |
Здесь сначала описывается тип – указатель PListElement на запись типа TListElement. Затем идет описание самого типа записи, одно из полей которой имеет тип PListElement.
Вообще говоря, каждый элемент подобной структуры может содержать сколько угодно указателей на элементы того же типа, что позволяет формировать не только списки, но также деревья и графы.
Деревья:
type refnode=^node;
node=record inf: integer;
left, right: refnode
End;
Графы:
Type refnode=^node;
refarc=^arc;
node=record {список вершин}
id: integer; {номер вершины}
infnode: integer; {вес}
next: refnode; {указатель на следующую вершину в списке}
arclist: refarc {указатель на список дуг}
End;
arc=record {список дуг определенной вершины}
infarc: integer; {вес}
next: refarc; {указатель на следующую дугу, исходящую из данной вершины}
adj 1: refnode {указатель на вершину, в которую ведет данная дуга}
End;
[ЛАБРИС 19: 23: 00]
> > говоришь определение. говоришь что рек типы используют для описания деревьев и списков, например мы на паскале задрили, вот так вот описывали + интересно заметить, что паскаль поддерживает только косвенную рекурсию в описании типа
21) 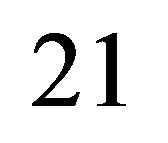 Операции над линейными списками: создание списков, включение элементов в списки (различные способы). Виды связных списков.
Операции над линейными списками: создание списков, включение элементов в списки (различные способы). Виды связных списков.
Работа с динамическими величинами связана с использованием еще одного типа данных — ссылочного типа. Величины, имеющие ссылочный тип,
называют указателями.
Указатель содержит адрес поля в динамической памяти, в которой хранится величина определенного типа. Сам указатель располагается в статической памяти.
Выделение памяти:
Память под динамическую величину, связанную с указателем, выделяется
в результате выполнения стандартной процедуры NEW. Формат обращения к
этой процедуре:
NEW(< указатель>);
Освобождение памяти
Стандартная процедура, позволяющая освобождать память от данных, потребность в которых отпала:
DISPOSE(< указатель>);
Например, если динамическая переменная P^ больше не нужна, то оператор:
DISPOSE(P) удалит ее из памяти.
Списком называется структура данных, каждый элемент которой с помощью указателя связывается со следующим элементом.
В односвязном списке каждый элемент состоит из двух различных по
назначению полей: содержательного поля (поле данных) и служебного поля
(поля указателя), где хранится адрес следующего элемента списка. Поле
указателя последнего элемента списка содержит нулевой указатель (Nil),
свидетельствующий о конце списка.
type reference=^element;
element=record
inf: integer;
next: reference;
end;
Элементы списка создаются во время работы программы по мере
необходимости. Также динамически между элементами устанавливаются и
разрушаются связи.
Если указатель ссылается только на следующее звено списка (как
показано на рисунке и в объявленной выше структуре), то такой список
называют однонаправленным, если на следующее и предыдущее звенья —
двунаправленным списком.
Если указатель в последнем звене установлен не в Nil, а ссылается на
заглавное звено списка, то такой список называется кольцевым. Кольцевыми
могут быть и однонаправленные, и двунаправленные списки.
Стек – это линейный список, в котором все включения и исключения (и
обычно всякий доступ) делаются в одном конце списка (в голове списка
Очередь – это линейный список, в один конец которого добавляются
элементы, а с другого конца исключаются, элементы удаляются из начала
списка, а добавляются в конце списка – как обыкновенная очередь в магазине.
Принцип работы очереди: «первый пришел - первый вышел».
включение элемента в список
Иногда требуется включить новый элемент после
или перед указанным элементом списка (наиболее простым является вставка
после указанного элемента):
procedure After(point: reference; x: integer);
var p: reference;
begin
if point< > nil then
begin
new (p);
p^.inf: =x;
p^.next: =point^.next;
point^.next: =p;
end;
end;
Вставка перед указанным (ссылкой point) элементом является более сложной, т.к. не можем двигаться по списку в направлении, обратном ссылкам. Требуется начать с головы списка и двигаться по ссылкам до элемента point, после чего вставить перед ним новый элемент:
procedure Before (var head: reference; point: reference;
x: integer);
var p, here: reference;
begin
new (p);
p^.inf: =x;
if point=head then
begin
p^.next: =point;
head: =p
end
else
begin
here: =head;
while here^.next < > point do
here: =here^.next;
here^.next: =p;
p^.next: =point;
end;
end;
22)  Операции над линейными списками: удаление элементов списков, поиск элементов в списках, сравнение списков.
Операции над линейными списками: удаление элементов списков, поиск элементов в списках, сравнение списков.
Удаление элемена this из списка
procedure StrikeOff(var head: reference; this: reference);
var p: reference;
begin
if this=head then
head: =this^.next
else
begin
p: =head;
while p^.next< > this do
p: =p^.next;
p^.next: =this^.next;
end;
dispose(this);
end;
Уничтожение списка
Процедура во время прохождения по списку освобождает память
поэлементно, начиная с головы.
procedure DestroyList(head: reference);
var p: reference;
begin
while head < > nil do
begin
p: =head^.next;
dispose(next);
head: =p;
end;
end;
Поиск элемента в списке
function Search (head: reference; x: integer): reference;
var run: Boolean;
begin
run: =true;
while (head< > nil) and run do
if head^.inf=x then
run: =false
else
head: =head^.next;
Search: =head;
end;
Рекурсивный вариант процедуры не требует вспомогательной
переменной:
function SearchR (head: reference; x: integer): reference;
var run: Boolean;
begin
if head=nil then SearchR: =nil
else
if head^.inf< > x then
SearchR: =SearchR(head^.next, x)
else SearchR: =head;
end;
Сравнение списков:
Задача решается синхронным проходом по двум линейным спискам и
сравнением информационных полей элементов разных списков, находящихся
на одинаковом расстоянии от начала. Если какая-то пара не совпадает или
списки имеют разную длину, то они считаются различными.
function CompList (head1, head2: reference): Boolean;
var run: Boolean;
begin
run: =true;
while(head1< > nil)and(head2< > nil) and run do
if head1^.inf< > head2^.inf then run: =false
else
begin
head1: =head1^.next;
head2: =head2^.next;
end;
CompList: = (head1=nil)and(head2=nil) and run
end;
23)  Операции над бинарными деревьями: включение вершин в дерево. Обход деревьев, подсчет числа вершин в дереве. Подсчет числа вершин, удовлетворяющих заданному условию.
Операции над бинарными деревьями: включение вершин в дерево. Обход деревьев, подсчет числа вершин в дереве. Подсчет числа вершин, удовлетворяющих заданному условию.
Дерево состоит из элементов, обычно называемых вершинами или узлами, и связей между вершинами, называемыми дугами или ссылками.
Дерево имеет два свойства:
• оно связно: из корня нужно пройти по дугам к каждой вершине;
• оно не содержит циклов, т.е. замкнутых последовательностей
вершин и дуг.
Бинарное (двоичное) дерево - это дерево, каждая
вершина которого имеет не более двух поддеревьев (левое и правое).
В двоичном дереве поиска для каждого узла выполняется правило: в
левом поддереве содержатся только ключи, имеющие значения, меньшие,
чем значение данного узла, а в правом поддереве содержатся только ключи,
имеющие значения, большие, чем значение данного узла.
Тип данных:
type refnode=^node;
node=record inf: integer;
left, right: refnode
end;
Вставка элемента в дерево
Procedure Include(var root: refnode; x: integer);
Begin
if root = nil then
Begin
new(root);
With root^ do
Begin
left: = nil;
right: = nil;
inf: = x;
end;
end
else if x< root^.inf then Include(root^.left, x)
else if x> root^.inf then Include(root^.right, x);
{Иначе ничего не делаем, т.к. значение х уже
существует}
End;
Обходы дерева:
Прямой обход дерева
- вывести значение, находящиеся в корне
- аналогичным образом пройти левое поддерево
- аналогичным образом пройти правое поддерево
Procedure Browser1 (root: refnode);
Begin
if root< > nil then
Begin
Write(root^.inf);
Browser1 (root^.left);
Browser1 (root^.right)
End;
End;
Обратный обход дерева
Левое-> корень-> правое
Procedure Browser2 (root: refnode);
Begin
if root< > nil then
Begin
Browser2 (root^.left);
Write(root^.inf);
Browser2 (root^.right)
End;
End;
Концевой обход дерева
Левое – правое – корень
Procedure Browser3 (root:
refnode);
Begin
if root< > nil then
Begin
Browser3 (root^.left);
Browser3 (root^.right)
Write(root^.inf);
End;
End;
Подсчет числа вершин + удовлетворяющих условию
С помощью прямого обхода найдем общее количество вершин в переменной i и количество вершин кратных 2 в переменной j. i и j объявлены вне процедуры.
var i, j: integer;
Procedure Browser1 (root: refnode);
Begin
if root< > nil then
Begin
inc(i);
if root^.inf mod 2=0 then inc(j);
Browser1 (root^.left);
Browser1 (root^.right)
End;
End;
24)  Операции над бинарными деревьями: удаление вершины дерева.
Операции над бинарными деревьями: удаление вершины дерева.
При удалении вершины со значением поля inf=x из дерева надо рассмотреть три возможных варианта
1. Узла со значение, равным х, нет.
2. Узел со значением х имеет не более одного потомка.
Если вершина является конечной или из нее выходит только одно ребро, то нужно изменить соответствующую ссылку у предшествующей вершины:

Если удаляемый узел имеет только одного " сына", то его значение
можно заменить значением этого " сына"
3. Узел со значением х имеет двух потомков.
Если у удаляемого элемента 2 " сына", заменяем его элементом с
наименьшим значением среди потомков правого " сына" (или элементом с
наибольшим значением среди потомков левого " сына")
Процедура Delete выполняет все описанные действия, используя
вспомогательную процедуру del.
procedure Delete (var root: refnode; x: integer);
var q: refnode;
procedure del(var r: refnode);
begin
if r^.right< > nil then del(r^.right)
else begin
q^.inf: =r^.inf;
q: =r;
r: =r^.left;
end
end;
begin
if root=nil then write(“Такой вершины в дереве нет”)
else if x< root^.inf then Delete(root^.left, x)
else if x> root^.inf then Delete(root^.right, x)
else
begin {удаляем вершину, на которую указывает root}
q: =root;
if q^.right=nil then
root: =q^.left
else
if q^.left=nil then
root: =q^.right
else
del(q^.left);
dispose(q);
end;
end;
25)  Понятие сбалансированности бинарного дерева. Привидение дерева к АВЛ сбалансированному виду: виды и формулы поворотов.
Понятие сбалансированности бинарного дерева. Привидение дерева к АВЛ сбалансированному виду: виды и формулы поворотов.
Идеальное дерево - дерево, в котором все вершины располагаются на h уровнях: корень - на 1-м, две вершины на 2-м, четыре - на 3-м. Новая вершина может быть помещена только на h+1 уровень. Количество операций при поиске и вставке в деревьях этого вида O(h) или O(log n).
Вырожденное дерево - дерево, которое представляет собой линейный список элементов, упорядоченных по возрастанию или убыванию информационных полей, количество операций при поиске и вставке O(n).
Бинарное дерево назовем идеально сбалансированным, если для каждой его
вершины количество вершин в левом и правом поддереве различаются не более
чем на 1
Бинарное дерево поиска называется сбалансированным по высоте, если для
каждой его вершины высота ее двух поддеревьев различается не более, чем на 1.
Деревья, удовлетворяющие этому условию, часто называют АВЛ-деревьями
Есть 4 варианта нарушения балансировки:
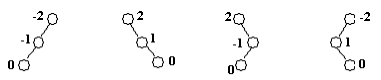
· LL-поворот
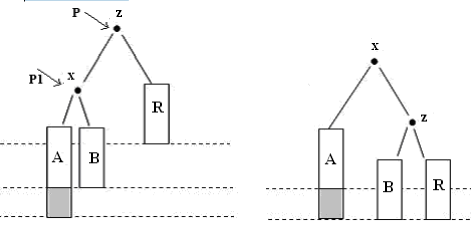
Надо преобразовать дерево t в новую форму: (A x B) z R ⇒ A x (B z R)
p1: = p^.left;
p^.left: = p1^.right;
p1^.right: = p;
p: = p1;
· RR-поворот
Симметричная ситуация имеет место, если новая вершина включается в
поддерево R дерева t=A x (b z R). В этом случае преобразование балансировки
будет обратным: A x (B z R) ⇒ (A x B) z R
p1: = p^.right;
p^.right: = p1^.left;
p1^.left: = p;
p: = p1;
· LR-поворот

Преобразование (A x (C y D)) z R ⇒ (A x C) y (D z R)
Фрагмент программы:
p1: = p^.left;
p2: = p1^.right;
p1^.right: = p2^.left;
p2^.left: = p1;
p^.left: = p2^.right;
p2^.right: = p;
p: = p2;
· RL-поворот
Двукратный (двойной) R-L-поворот выполняется, когда «перевес» идет по
пути R-L от узла с нарушенной балансировкой. Выполняется преобразование:
A x ((C y D) z R) ⇒ (A x C) y (D z R).
Фрагмент программы:
p1: = p^.right;
p2: = p1^.left;
p1^.left: = p2^.right;
p2^.right: = p1;
p^.right: = p2^.left;
p2^.left: = p;
p: = p2;
26) 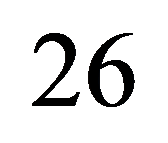 Анализ сложности алгоритмов работы с бинарными деревьями.
Анализ сложности алгоритмов работы с бинарными деревьями.
27)  Деревья со многими потомками. Специальные виды деревьев: деревья формул, Б-деревья, 2-3 деревья, красно-черные деревья.
Деревья со многими потомками. Специальные виды деревьев: деревья формул, Б-деревья, 2-3 деревья, красно-черные деревья.
Деревья со многими потомками:
У таких деревьев от вершины может быть сколько угодно потомков. Возможный тип представления:
type refnode=^node
node = record
inf: integer;
a1: refnode;
a2: refnode;
a3: refnode;
...
an: refnode;
end;
Деревья формул:
Дерево-формула это бинарное дерево, построенное из строки, в которой записано какое-то алгебраическое выражение.
Пример такого дерева:
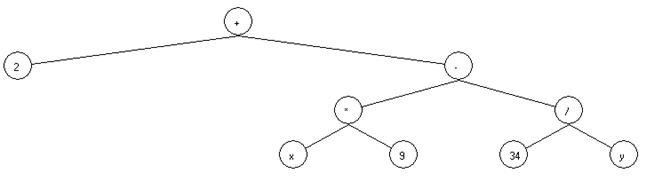
В каждом его листе хранится либо переменная, либо число, а во всех остальных вершинах, которые не являются листами могут хранится арифметические операции.
Описание типа:
Type pnode=^node;
Node=record
data: string;
Left, right, parent: pnode
End;
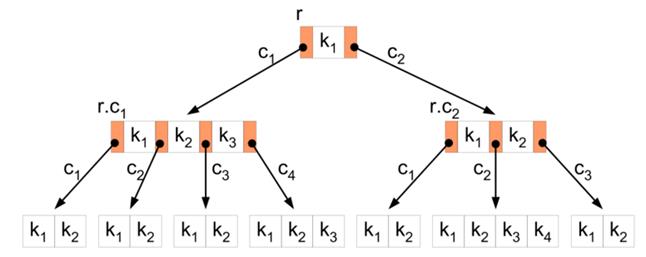
Б – деревья
Структура данных, дерево поиска. С точки зрения внешнего логического представления, сбалансированное, сильно ветвистое дерево во внешней памяти.
Сбалансированность означает, что длина любых двух путей от корня до листов различается не более, чем на единицу.
Ветвистость дерева — это свойство каждого узла дерева ссылаться на большое число узлов-потомков.
|
|