Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Обобщенная структурная схема микропроцессоров поколения Intel Core II
|
|
Поступивший в широкую продажу микропроцессор архитектуры Sandy Bridge, первенец поколения процессоров Intel Core II, представляет собой четырёхъядерный 64-битный процессор с изменяемой (out-of-order) последовательностью исполнения команд, поддержкой двух потоков данных на ядро (технология Hyper Threading), исполнением четырёх команд за такт; с интегрированным графическим ядром и интегрированным контроллером памяти DDR3; с новой кольцевой шиной, производство которого налажено на линиях с соблюдением норм современного 32-нм технологического процесса Intel.
Еще одной особенностью микроархитектуры Sandy Bridge является поддержка набора инструкций Intel AVX (Advanced Vector Extensions). Intel AVX представляет собой новый набор трех- и четырех-операндных векторных команд, предусматривающий 256-битные векторные вычисления с плавающей запятой на базе SIMD (Single Instrucion, Multiple Data).
Микропроцессоры Intel Core II на базе микроархитектуры Sandy Bridge поставляются в новом 1155 контактном корпусе типа LGA1155. Для них используется специальный чипсет Intel 6 Series.
Напомним, что микропроцессоры предыдущего поколения микроархитектуры Westmere состояли из двух кристаллов: на одном располагались процессорные ядра с использованием технологии 32-нм, а на другом кристалле, с 45-нм технологией, размещались графическое ядро GPU (Grafic Processor Unit), контроллер памяти IMC (Integrated Memory Controller), контроллеры шин QPI (Quick Path Interface), функциональный блок контроля мощности PCU (Power Control Unit) и кэш-память третъего уровня L3.
Достигнутый к настоящему времени уровень интеграции позволил разработчикам архитектуры Sandy Bridge разместить все элементы микропроцессора на одном кристалле, отказавшись от шины QPI и используя новую кольцевую шину. При этом на кристалле размещено 995 млн. транзисторов. Заметим, также, что процессоры Sandy Bridge способны тактировать память также и на частотах 1600, 1800 и даже 2133 МГц.
Структуру микропроцессора Sandy Bridge в первом приближении можно разбить на следующие основные элементы: процессорные ядра, графическое ядро, кэш-память L3, которая при этом получила название кэш-памяти последнего уровня LLC (Last Level Cache) и так называемый «Системный агент» (System ‘Agent). Все элементы микропроцессора связываются в единую систему с помощью шинных интерфейсов (см. рис XI.3). При этом заметим, что вся кэш-память МП архитектуры Sandy Bridge работает на частоте процессора.
.
Внутренняя кольцевая шина межсоединений
В предыдущей микроархитектуре Nehalem для этой цели использовались шины QPI (QuickPath Interconnect), реализуя обычную перекрестную топологию. Однако что было достаточно удобно и эффективно при распределении компонентов микропроцессора на двух отдельных кристаллах, стало неэффективным при внедрении 32-нм технологического процесса и размещении всех компонентов процессора на одном кристалле. Увеличение производительности процессора, степени интеграции кристалла, повышение требования к пропускной способности внутренних межкомпонентных соединений привело к использованию новой внутренней шинной топологии микропроцессоров Sandy Bridge. В связи с этим разработчики решили обратиться к кольцевой топологии 256-битной межкомпонентной шины (Ring Bus), но в которой, кстати, за основу взята новая версия технологии QPI, используемой в микропроцессорах архитектуры Nehalem.
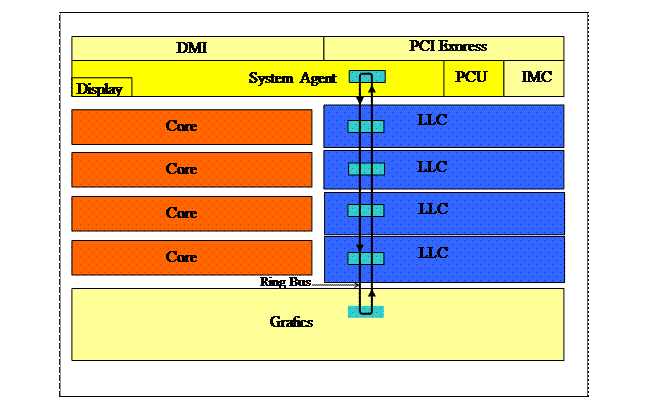
Рис X.3 Схема размещения компонентов и кольцевой шины в микропроцессоре
микроархитектуры Intel Core II.
Обозначения на рисунке:
DMI (Direct Media Interface) – локальная шина «точка-точка», обеспечивающая скоростной обмен информацией с «южным» мостом чипсета до 2 Гбайт/с.
PCI Express (Pe’ripheral Com’ponent 'Intercon’nect) – высокоскоростная последовательная шина расширения.
IMC (Integrated Memory Cont’roller) – интегрированный в процессор контроллер памяти.
LLC (Last Level Cache) – кэш L3.
Core – ядро процессора.
Grafics – графический процессор.
Display – модуль видеовыхода.
PCU – (Power Cont`rol Unit) – блок управления энергопотреблением
Таким образом, кольцевая шина микропроцессоров поколения Intel Core II служит для обмена данными между шестью компонентами кристалла микропроцессора: четырьмя процессорными ядрами, графическим ядром, кэш-памятью третьего уровня L3 (LLC) и системным агентом (System agent). Она состоит из четырех 32-байтных колец: шины данных (Data Ring); шины запросов (Request Ring); шины мониторинга состояния (Snoop Ring) и шины подтверждения (Acknowledge Ring). Для предотвращения конфликтов между процессорными ядрами и графикой предусмотрен специальный трассировочный механизм. Обработка запросов происходит на тактовой частоте процессорных ядер, (в том числе и обмен информацией с кэш-памятью L3), а сама производительность кольцевой шины оценивается на уровне 96 Гбайт в секунду на соединение при тактовой частоте 3 ГГц, что фактически в четыре раза превышает показатели процессоров Intel предыдущего поколения.
Кольцевая топология и организация шин обеспечивает минимальную временную задержку при обработке запросов, максимальную производительность и отличную масштабируемость технологии для версий кристаллов с различным количеством ядер и других компонентов процессора. По словам представителей корпорации Intel, в перспективе к используемой кольцевой шине может быть подключено до 20 процессорных ядер на одном кристалле. Наибольшее влияние кольцевая шина оказывает влияние на производительность в графических приложениях.
Кэш-память последнего уровня
Кэш-память последнего уровня LLC, объёмом до 8 Мбайт, разбита на четыре сегмента, и каждое процессорное ядро имеет прямой доступ к «своему» сегменту. Благодаря кольцевой шине, к которой эта кэш-память подсоединена, произошло снижение задержек обращения к ней и перевод ее работы на частоту процессора. При этом каждый сегмент кэш-памяти L3 предоставляет половину ширины своей шины для связи с кольцевой шиной данных и имеет собственный независимый контроллер доступа к ней. Этот контроллер отвечает за обработку запросов по размещению физических адресов. Кроме того, он постоянно взаимодействует с «системным агентом» по выяснению неудачных обращений к кэш-памяти этого уровня, контроля межкомпонентного обмена данными и некэшируемых обращений.
«Системный агент» (System Agent)
«Системный агент» (System Agent) – понятие, которое разработчики микроархитектуры Sandy Bridge ввели вместо понятия Uncore (Неядро), используемое в микроархитектуре Nehalem, включает в себя те компоненты микропроцессора, которые не могут быть сгруппированы с исполнительными ядрами. Фактически System Agent выполняет функцию «Северного моста» ChipSet. В состав системного агента входят: двухканальный контроллер памяти модулей DDR3, поддерживающий скорость передачи до 1333 Мбайт/с; 16 линий PCI Express второго поколения (PCIe× 16); локальный последовательный интерфейс DMI (Direct Media Interface), обеспечивающий связь с «южным мостом» чипсета со скоростью до 2 Гбайт/с, модуль медиа-обработки и видеовыхода, а также улучшенный блок управления энергопотребления PCU (Power Control Unit), реализующий технологию Turbo Boost второго поколения.
Напомним, что технология Turbo Boost – это технология динамической подстройки тактовых частот, ядер процессоров фирмы Intel, а также напряжения их питания, в зависимости от уровня загрузки и температуры процессора. При этом, управление это осуществляется исходя из критерия достижения наилучшей энергоэффективности процессора. Появление технологии Turbo Boost (Turbo Mode) возникло в связи с тем, что в многоядерных микропроцессорах далеко не все имеющиеся ресурсы используются даже современными версиями приложений. Многие программы, не слишком приспособленные для реализации в многоядерных системах, могут использовать лишь одно ядро одновременно, не загружая остальные. А поскольку TDP (Thermal Design Power) кристалла рассчитывается исходя их наихудшего случая, когда все ядра загружены максимально, то технология Turbo Boost использует возникающий резерв по теплоотдаче и перераспределяет тактовые частоты и даже иногда изменяет напряжение питания ядер, но так, чтобы в целом максимальное энергопотребление кристалла не превышало критического. Причем используемый PCU управляет и графическим ядром, однако отдельно от основных исполнительных ядер.
Предусмотрен и специальный экономичный ждущий режим для кольцевой шины, когда она не нагружена, а для кэш-памяти L3 применяется традиционная технология отключения неиспользуемых транзисторов, которая уже использовалась в микропроцессорах архитектур Intel Core.
Модули видеовыхода и мультимедийного аппаратного декодирования также входят в число элементов системного агента. В предыдущих процессорных микроархитектурах аппаратное декодирование реализовывалось графическим ядром. При микроархитектуре Sandy Bridge используется отдельный, значительно более производительный и экономичный модуль. И только в особых случаях сжатия мультимедийных данных используются возможности шейдерных блоков (теневых блоков, блоков подсветки) графического ядра, которое в этих случаях работает совместно с кэш-памятью LLC.
Судя по всему, кэш-память L3 (LLC) разработчики также включают в состав «системного агента», хотя об этом прямо не говорится.
Графическое ядро (Grafics – GPU)
Отличием графического ядра микропроцессоров архитектуры Sandy Bridge от микропроцессоров предыдущей архитектуры является в первую очередь то, что оно интегрировано в тот же кристалл, изготавливаемый по технологии 32 нм, что и все остальные компоненты процессора. Кроме того, оно отличается тем, что управление его производительностью и температурным режимом осуществляется не программным путем с помощью специального драйвера, а «системным агентом» на аппаратном уровне. В связи с этим, процессы изменения напряжения питания, тактовой частоты, производительности и энергопотребления встроенной графики реализуются в более широких пределах и с такой же высокой эффективностью, что и изменение параметров ядер процессора.
В целом, по заявлению представителей фирмы Intel, исполнительные блоки графического процессора обладают удвоенной пропускной способностью, по сравнению с предыдущим поколением интегрированной графики, а производительность вычислений с трансцендентными числами (тригонометрия, натуральные логарифмы и т.д.) за счёт акцента на использовании аппаратных вычислительных возможностей модели вырастает в 4-20 раз.
Заметим, что хотя физически модуль обработки медиа располагается, при архитектуре Sandy Bridge, в составе «системного агента», т.е. вне графического процессора, обработка медиа-данных при кодировании (сжатии) мультимедийных потоков осуществляется совместно с исполнительными блоками графического процессора. (Однако декодирование мультимедийных потоков осуществляется в «системном агенте» полностью аппаратным путем, в специальном модуле, обеспечивающим высокую производительность). Поэтому, несмотря на то, что интегрированная графика, как правило, в настоящее время уступает по производительности автономным видеокартам, тестирование поступивших в продажу микропроцессоров с архитектурой Sandy Bridge показало, что если исключить игровые приложения, используемая структура графики весьма перспективна.
Процессорные ядра
Обычно, структуру ядра современных процессоров рассматривают как состоящие из трех основных частей:
· Кэш L1данных и команд, причём в микроархитектуре Sandy Bridge в состав ядра включают и кэш-память второго уровня (кэш L2);
· Предпроцессор (Front End), в котором осуществляются операции выборки инструкций из кэш-памяти и продвижение их к исполнительным блокам;
· Постпроцессор (Back End), называемый также блоком исполнения команд (Execution Engine), в котором осуществляется собственно исполнение инструкций.
Инструкции Х86 выбираются из 8 канального, 32 килобайтного кэш L1 команд и загружаются в предпроцессор 16 байтными блоками, то есть за каждый такт из кэш-памяти загружается 16 байтный блок команд.
Блок-схема процессорного ядра Sundy Bridge изображена на рис.XI.4.
Обозначения на рисунке:
ALU (Arithmetic Logic Unit) – арифметико–логическое устройство.
Load – функциональное устройство загрузки данных
Store – функциональное устройство сохранения данных.
Store Address – функциональное устройство, осуществляющее передачу в память адресной информации.
Store Data – функциональное устройство, осуществляющее передачу в память данных.
AVX FP Blend –реализация команд, обеспечивающих гладкую стыковку отрезков в машинной графике.
AVX FP MUL –реализация команд умножения векторов с плавающей запятой.
AVX FP ADD – реализация команд сложения векторов с плавающей запятой.
AVX FP shuffle – реализация команд перетасовки векторов с плавающей запятой.
AVX FP bool – реализация операций с булевыми функциями.
VI ADD – (Vector Integer ADD) – реализация команд сложения векторов целых чисел.
VI MUL – реализация команд умножения векторов целых чисел.
VI shuffle – реализация команд перетасовки векторов целых чисел.
DIV – реализация команд деления.
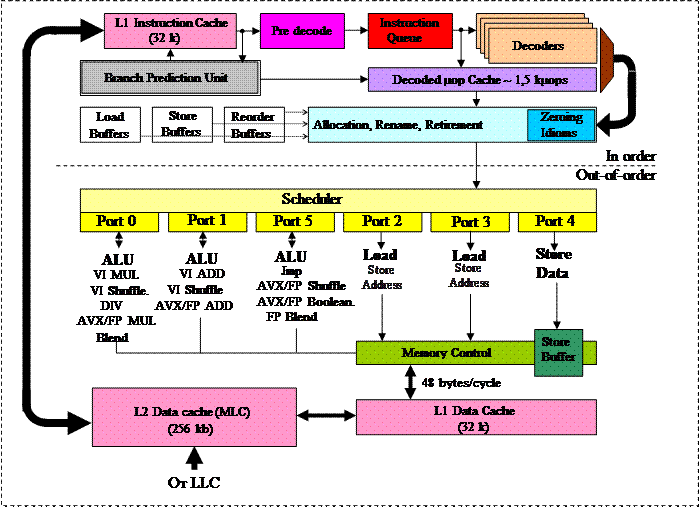
Рис XI.4 Блок схема процессорного ядра Sandy Bridge
Блок предсказания ветвлений
Блок предсказания ветвлений Sandy Bridge, по сравнению с предшествовавшей ей микроархитектурой Nehalem, существенно улучшен. Например, буфер блока предсказания ветвлений (Branch Target Buffer, BTB) вмещает в два раза больше адресов результатов ветвления и вдвое большую историю комбинаций команд. Кроме того, увеличены размеры области хранения истории ветвлений, в том числе предсказанных и выполненных. Этим удалось существенно снизить количество неудачных предсказаний ветвлений и таким образом как увеличить производительность процессора, за счет уменьшения времени вынужденного простоя для сброса конвейера с обработанными впустую инструкциями, так и уменьшить потребление энергии, затраченной зря на обработку неудачных ветвлений.
Декодирование
Кэш L1 инструкций, как это было уже упомянуто, представляет собой восьмиканальную (8-ми входовую) множественно-ассоциативную кэш-память емкостью 32 килобайт с размером строки (блока) равной 16 байт. После выборки из кэш-памяти с помощью блока упреждающей выборки команд, который располагается в модуле предсказания ветвлений (Branch Prediction Unit), строка инструкций Х86 подается на ступень предварительного декодирования (Pre decoder). Дело в том, что инструкции Х86 имеют переменную длину (от одного до 15 байт), а у блоков, которыми информация загружается из кэш памяти, длина фиксирована. Предварительное декодирование заключается в том, что этот сплошной блок кодов, размером в 16 байт каждый, разбивается на отдельные инструкции Х86, и заносятся в буфер очереди команд (Instruction Queue). При предварительном декодировании команд нужно определять границы между отдельными командами. Информация о размерах команд хранится в кэш памяти инструкций L1 в специальных полях (по 3 бита информации на каждый байт инструкций). Процедура предварительного декодирования позволяет поддерживать постоянный темп основного декодирования независимо от длины и структуры команд.
Таким образом, перед собственно декодированием команд производится выделение команд из общего блока. Введение же буфера очереди команд позволяет уменьшить простои конвейера из-за конфликтов по управлению (за счет задержек при выборке команд из памяти). При этом формирование очереди команд осуществляется со скоростью до шести инструкций за такт.
Из буфера очереди команд, работающей по принципу FIFO, инструкции поступают на 4 блока основного декодирования (Decoders), работающих параллельно. Блоки декодирования преобразуют инструкции Х86 разной длины в упорядоченный поток равномерных микрокоманд, которые определяют так называемые микрооперации (мкоп, micro-op, μ ops), т.е. понятные для данного процессора примитивы. От оперативности работы декодеров, от их согласованности с блоком предсказания ветвлений и «умения» заполнять конвейер непосредственно зависит бесперебойность потока микроопераций, загрузка конвейера и, в конечном счете, производительность микропроцессора.
В принципе, длина одной инструкции системы команд Х86 может достигать 15 байт. Однако средняя длина команд составляет 4 байта. Поэтому в среднем в каждом блоке загружаются 4 команды, которые при использовании четырёхканального декодера одновремённо декодируются за один такт. Естественно, декодирование четырёх инструкций за такт возможно только в том случае, если в одном 16-байтном блоке содержится не менее четырёх инструкций. Однако существуют инструкции и длиннее 4 байт, и при загрузке нескольких таких команд в одном блоке эффективность декодирования снижается.
Этот четырехканальный декодер включает в себя три простых декодера, предназначенных для декодирования простых инструкций (сложения, вычитания, сравнения, логических операций и др., без выборки операндов из памяти) в одну микрокоманду, реализующую одну простую микрооперацию, и один сложный, способный декодировать одну (более сложную) инструкцию в четыре микрокоманды.Однако в любом случае декодеры, вне зависимости от поступающих инструкций выдают на выходе не более четырех микрокоманд за такт. При этом отметим, что все микрокоманды на выходе декодеров, имеют одинаковую фиксированную длину.
Сами все эти декодеры реализуются в аппаратном исполнении.
Система обнаружения программных циклов
При проведении выборки программных инструкций необходимо отметить использование усовершенствованного блока обнаружения программных циклов LSD (Loop Stream Detector), емкость которого по сравнению с процессорами Intel Core, увеличилась с 18 до 28 записей, что дает возможность отслеживать и распознавать циклы, содержащие до 28 инструкций. Суть его работы заключается в том, что, обнаружив цикл небольшой длины (до 28 микрокоманд, а таковых циклов большинство), он сохраняет, входящие в его состав микрокоманды в специальном буфере, откуда они и выбираются, если цикл выполняется многократно. Технология LSD позволяет избежать повторов в выполнении таких операций как предсказание ветвлений (Branch Prediction), выборка (Fetch), а при архитектурах Nehalem и Sandy Bridge, также и декодирования (Decode). Дело в том, что сам этот блок (буфер) в процессорах Nehalem и Sandy Bridge располагается после декодера, что увеличивает эффективность работы LSD. Эффективность его работы, при этом, увеличивается именно за счет того, что он имеет дело не с инструкциями из кэш памяти в своем первозданном виде, а с микрокомандами после декодера.

Рис. XII.5 Расположение модуля Loop Stream Detector в процессоре
c микроархитектурой Sandy Bridge
Таким образом, при обнаружении программного цикла инструкций в цикле пропускают фазы предсказания ветвлений в программе (Branch Prediction), выборки (Fetch) и декодирования (Decode), а сами команды генерируются и поступают на дальнейшие ступени конвейера непосредственно из Loop Stream Detector (рис XII.5). С одной стороны, это позволяет снизить энергопотребление ядра процессора, а с другой – обойти фазу выборки команд и детектирования.
Если же в цикле насчитывается более 28 инструкций, то инструкции будут каждый раз проходить все стандартные шаги.
Кэш L0
Одним из наиболее важных нововведений микроархитектуры Sandy Bridge является вновь введенный кэш декодированных микроопераций (Decoded μ op Cache), или кэш L0. Он может хранить 1536 микрокоманд (что эквивалентно примерно 6-килобайтному КЭШу Х86 инструкций), с возможностью параллельного ввода и вывода одновременно шести микрокоманд. Кэш L0 кэширует на выходе декодеров все предварительно декодированные микрокоманды. Как только поступает на обработку новая инструкция, блок упреждающей выборки первым делом производит сверку с кэш L0, и в случае обнаружения совпадений, загрузка конвейера четырьмя микрокомандами за такт в обход декодеров осуществляется уже из кэш L0. Таким образом, в этом случае нет необходимости снова проводить выборку и декодирование.
Естественно, что эффективность использования кэш L0 во многом зависит от эффективности работы блока предсказания ветвлений (Branch Prediction Unit, BPU). Незадействованные и простаивающие устройства декодеров, достаточно сложные и поэтому потребляющие довольно много энергии в это время автоматически отключаются от источника питания. Если же кэш декодированных микрокоманд оказывается невостребованным, он переводится в режим экономии энергии, а декодеры продолжают обычную работу по выборке и декодированию инструкций. Кэш L0 в какой-то мере можно считать частью кэш L1, в который он, кстати, интегрирован, но отдельной и очень быстрой его частью. По словам представителей фирмы Intel, при работе с большинством приложений, вероятность удачного попадания в кэш декодированных микрокоманд весьма велика и может достигать 80%.
Блок переименования и распределения дополнительных регистров.
Сформированный поток микрокоманд поступает в блок переименования, распределения и переупорядочения (Rename/Allocate/Retirement), а конкретно в так называемый буфер декодированных, но еще не выполненных команд – Reservation Station (RS), который включает в себя 54 дополнительных регистра, которые не определены архитектурой набора команд.Там же содержится специальный физический регистровый файл, PRF (Physical Register File), который состоит из совокупности регистров, для хранения целочисленных данных, емкостью 160 отдельных 64-битных записей и совокупности регистров для хранения векторно-вещественных данных с плавающей запятой, емкостью 144 256-битных записей, т.е. регистров YMM c новыми векторными командами AVX (х86-64) целиком. В этом регистровом файле фиксируются результаты отслеживания и переименования микроопераций.
Кроме того, этот блок включает в себя буфер переупорядочения ROB (Re-Order Buffer), который служит для реализации алгоритма последовательности исполнения микрокоманд не в порядке их поступления, а таким образом, чтобы впоследствии можно было реализовать их наиболее эффективное выполнение в исполнительных блоках. После чего его задачей является последующее восстановлением их последовательности, которая задана программой. Буфер переупорядочения способен обрабатывать до 168 микроопераций одновременно.
Идея переименования и распределения дополнительных регистров, которые не определены архитектурой набора команд регистров, заключается в следующем. В архитектуре Х86 количество регистров общего назначения сравнительно невелико: доступно восемь регистров в 32-битном режиме, и 16 – в 64 битном. Представим, что исполняемая микрокоманда дожидается загрузки значений операндов в регистр из памяти. Это долгая операция, и хорошо бы на это время разрешить использовать этот регистр для другой команды, операнды которой находятся ближе (например, в кэш-памяти L1). Для этого временно переименовывается «ждущий» регистр и отслеживается история переименования. А «готовому к работе» регистру присваивается стандартное имя, чтобы снабженную операндами команду исполнить прямо сейчас. Когда придут данные из памяти, обращаются к истории переименования и возвращают изначальному регистру его законное, архитектурное, имя. Переименование регистров позволяет добиться исполнения команд вне очереди. Таким образом, техника переименования регистров позволяет сократить простои, а ведение истории переименования применяется для нивелирования конфликтов.
В микроархитектуре Sandy Bridge кластер Allocate/Rename/Retirement (Out-of-Order Cluster), был изменён существенно. В микропроцессорах предыдущей микроархитектуры Nehalem физические регистровые файлы PRF не применялись и каждая микрооперация имела копию операнда или операндов, которые ей требуются. Фактически это означает, что блоки кластера внеочередного исполнения команд должны быть достаточно большого размера, поскольку должны вмещать микрооперации вместе с необходимыми для них операндами. В микроархитектуре Nehalem операнды могли иметь размер 128 бит, но с введением расширения AVX (Advanced Vector Extension) размер операнда может составлять 256 бит, что требует увеличить в два раза размеры всех блоков кластера внеочередного исполнения команд.
Поэтому вместо этого в микроархитектуре Sandy Bridge используется физический регистровый файл (Physical Register File – PRF), в котором хранятся операнды микроопераций (Рис XI.5).
|
|