Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Эффективность радиолокационного распознавания
|
|
Критерием эффективности распознавания является повышение показателей эффективности использующих его систем за счет привлечения информации распознавания. Эффективность этих систем зависит обычно от: 1) отношения дальности выдачи информации распознавания к дальности обнаружения целей соответствующего класса; 2) матрицы условных вероятностей распознавания при различных условиях наблюдения; 3) матрицы стоимостей ущерба принятия неправильных решений.
Матрица условных вероятностей распознавания для М-элементвого алфавита классов имеет вид
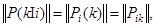
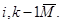 (1.11)
(1.11)
Здесь  =
= 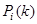 =
= 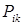 – условная вероятность принятия решения о классе цели k при условии ее принадлежности классу i.
– условная вероятность принятия решения о классе цели k при условии ее принадлежности классу i.
Матрица стоимостей ошибок распознавания 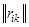 позволяет ввести средний риск как среднюю стоимость ущерба
позволяет ввести средний риск как среднюю стоимость ущерба
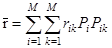 (1.12)
(1.12)
учитывая неравнозначность отдельных ошибок с позиций потребителя информации и априорные вероятности Рi появление целей различных классов. Для упрощенна оптимизации распознавания матрицу стоимостей сводят иногда к единичной (простая матрица стоимостей) или к диагональной (полупростая матрица стоимостей), полагая соответственно rii = -1 или rii = - ri. Знак минус связан с заменой " штрафов" за ошибки " премиями" за правильные решения. Учет неравнозначности различных правильных решений в последнем случае сохраняется. Выражение (1.12) переходит при этом в
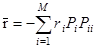
 (1.13)
(1.13)
Полупростая матрица стоимостей используется в разд. 2.2. Ориентировочной, но удобной характеристикой эффективности распознавания является полная вероятность ошибки распознавания при равновероятном появлении объектов различных классов
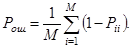 (1.14)
(1.14)
Ее использование поясняется в разд. 4.4.4.
2. АЛГОРИТМЫ РАСПОЗНАВАНИЯ ПО СОВОКУПНОСТИ ПРИЗНАКОВ
2.1. ОБЩИЕ СВЕДЕНИЯ
Варианты рассматриваемых алгоритмов различаются:
· этапностью принятия решений;
· степенью и характером учета статистики признаков, помех, сигналов.
По этапности различают алгоритмы одноэтапного я многоэтапного принятия решений. Одноэтапное принятие решений предусматривает обязательную выдачу оценки 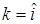 класса i известного алфавита с приемлемой достоверностью. К многоэтапности принятия решений могут вести следующие соображения:
класса i известного алфавита с приемлемой достоверностью. К многоэтапности принятия решений могут вести следующие соображения:
· целесообразность отказа от выдачи решения на первом этапе до дополни2-тельного набора признаков (последовательные алгоритмы типа Вальда);
· целесообразность принятия загрубленного решения до дополнительного набора признаков;
· необходимость обобщения предварительных решений, полученных в различные моменты времени или от различных РЛС.
По степени учета статистических закономерностей различают лингвистические и статистические алгоритмы. Похарактеру учета статистических закономерностей из статистических алгоритмов выделяют параметрические (байесовские и небайесовские), непараметрические и нейрокомпьютерные алгоритмы.
Лингвистические алгоритмы [3, 9, 14, 17, 49] не учитывают статистики признаков. Вводимые признаки описывают качественно, часто двоичными цифрами 0, 1. Описание признаков на языке алгебры логики - лингвистическое (языковое, кодовое, синтаксическое) служит при этом основой распознавания.
Байесовские параметрические алгоритмы (разд. 2.2), в отличие от параметрических небайесовских, учитывают не только статистику параметров помех, флюктуаций сигналов и признаков, но и определенные гипотезы об априорных вероятностях Рi различных элементов алфавита классов [8. -11, 12]. Структура алгоритмов и работающих по ним устройств обработки сигналов определяется тогда из математического расчета. Статистика признаков сигналов, негауссовская в общем случае, устанавливается путем натурного эксперимента, математического или физического моделирования. Введение этой статистики можно трактовать как обучение распознаванию, адаптацию к конкретным условиям распознавания.
Непараметрические алгоритмы (разд. 2.3) синтезируются эвристически без явного принятия предположений о конкретных статистических распределениях [8-12, 50, 51]. Их можно рассматривать в ряде случаев как эвристическое упрощение параметрических байесовских.
Нейрокомпьютерные алгоритмы (раз. 2.4) отличаются заранее заданной универсальной структурой с большим числом неизвестных параметров, уточняемых в процессе адаптации (обучения) [52-56]. Возрастание вычислительных затрат как издержку универсализации компенсируют ростом производительности вычислительных средств.
В последнее время к решению задач распознавания привлекают теорию игр и другие математические методы [22, 23].
|
|