Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Стадии и этапы создания АС 2 страница
|
|
· системы общего назначения, не зависящие от конкретных областей применения и типов передаваемой информации;
· системы межабонентского обмена сообщениями, т.е. системы, которые для взаимодействия персональных пользователей объединяют возможности обработки сообщений общего назначения, систем телематики и систем физической доставки сообщений, формируя единую среду обмена сообщениями;
· системы обмена электронными данными, например, системы, поддерживающие построение распределенных приложений, компоненты которых могут обмениваться между собой производственными данными, используя сервис, предоставляемый MTS.
3.4 Многоуровневая модель системы стандартов ИТ
Современная система стандартов ИТ чрезвычайно обширна и развивается быстрыми темпами. Количество стандартизованных документов исчисляется четырехзначными числами. Поэтому для эффективной работы с такой массой документов необходимо использовать методы классификации и систематизации стандартов и профилей [2].
С целью систематизации стандартов ИТ используется многоуровневая модель пространства спецификаций ИТ (базовых стандартов и профилей ИТ) []. Следует отметить, что стандартизованными спецификациями могут быть документы различных видов, в том числе и документы, регламентирующие работу организаций стандартизации. В дальнейшем нас будут интересовать спецификации, непосредственно связанные с описанием свойств ИТ, а также технологическими процессами их создания и использования.
В рассматриваемой ниже модели пространства стандартов и профилей ИТ выделены следующие уровни иерархической упорядоченности спецификаций.
1.Концептуальный уровень или уровень метазнаний, состоящий из архитектурных спецификаций, к которым в первую очередь относятся эталонные модели. Архитектурные спецификации предназначены для структуризации семантики конкретных областей ИТ.
2.Функциональный уровень или уровень базовых спецификаций (базовых стандартов и PAS), предназначенный для определения индивидуальных функций или наборов функций, указанных в архитектурных спецификациях.
3.Уровень предметных или локальных профилей ИТ, охватывающий, например, OSI-профили, API-профили, т. е. профили, разрабатываемые на основе использования базовых спецификаций, относящихся к предметной области, описанной одной эталонной моделью (возможно вместе с профилями представления и форматов данных, т. е. с Fпрофилями).
4.Уровень OSE-профилей, т. е. спецификаций поведения открытых систем на их границах (интерфейсах), агрегирующих базовые спецификации и/или профили, относящиеся к различным эталонным моделям.
5.Уровень OSE-профилей открытых платформ (систем), содержащий спецификации, предназначенные для описания поведения систем на всех их интерфейсах, т. е. их полного описания.
6.Уровень OSE-профилей прикладных технологий, представляющих собой полные спецификации функций и окружений прикладных технологий обработки данных (например, банковских систем, распре деленных офисных приложений и т. п.), построенных на принципах открытости. Как правило, такие профили включают две части, одну, связанную с описанием окружения нижележащей платформы, другую - с описанием собственно интерфейсов приложения.
7.Уровень стратегических профилей, содержащий профили, рассматриваемые в данном случае не как спецификации одной технологии, а как наборы стандартов, определяющих техническую политику в области телекоммуникации или открытых технологий крупной организации или даже государства.
| 1 Стратегические профили (GOSIP, IGOSS и пр.) |
| 2 Профили прикладных технологий |
| 3 Полные 0 S Е -профили (профили платформ, систем) |
| 4 OSE-профили |
| 5 Локальные профили (OSI-профили, API-профили) |
| 6 Базовые спецификации |
| 7 Архитектурные спецификации (эталонные модели) |
Рисунок 3.4. Иерархическая структура пространства спецификаций ИТ
Примерами стратегических профилей являются: GOSIP (Government's Open Systems Interconnection Profile), IGOSS (Industry/Government Open Systems Specifications), APP (Application Portability Profile).
На данной схеме сверху вниз (в порядке нарастания номеров) происходит селекция, т.е. дробление функциональности, а снизу вверх – агрегирование, т.е. объединение функциональности.
Как видно из анализа рассмотренной иерархической модели, она определяет некоторую вертикальную структуризацию пространства стандартов и профилей ИТ. Нижние два уровня этой модели образуют концептуальный и функциональный базисы области ИТ соответственно. Более высокие уровни соответствуют профилям различной композиционной сложности. Определенная выше иерархическая классификационная модель пространства спецификаций ИТ иллюстрируется на рисунке 3.4.
Заметим, что в процессе практической реализации концепции Глобальной информационной инфраструктуры (GII) важная роль отводится разработке и стандартизации сценариев, определяющих взаимосвязь технологий, участвующих в реализации сервисов GII. В случае предложенной классификации спецификаций ИТ такие стандартизованные функционально соответствовали бы профилям уровней 4-6 как средствам комплексирования разнородных ИТ.
Рассмотрим назначение и содержание уровней представленной модели.
3.4.1 Архитектурные спецификации
Ядром методологического базиса ИТ служат архитектурные спецификации, к которым, прежде всего, относятся эталонные модели. Каждая эталонная модель вводит концептуальный контекст и определяет структуру множества базовых спецификаций, соответствующих конкретному разделу ИТ. В этом смысле эталонные модели могут рассматриваться как метазнания области ИТ.
Наиболее известными эталонными моделями являются следующие.
1.Базовая эталонная модель взаимосвязи открытых систем (Basic Reference Model for Open Systems Interconnection - OSI RM).
2.Эталонная модель окружений открытых систем POSIX (Portable Operating System Interface for Computer Environments - OSE RM).
3.Эталонная модель для открытой распределенной обработки (Reference Model for Open Distributed Processing - ODP RM).
4.Эталонная модель управления данными (Reference Model for Data Management - DM RM).
5.Эталонная модель компьютерной графики (Reference Model of Computer Graphics - CG RM).
6.Эталонная модель открытого электронного обмена данными (Open-edi reference model - Open-EDI RM).
Модели, имеющие фундаментальное значение и которые также можно было бы отнести к уровню архитектурных спецификаций, разработаны в таких областях, как, например, конформность и методы тестирования конформности (conformance and conformance test methods), управление сетевыми ресурсами, управление качеством продуктов, управление безопасностью ИТ, эргономика компьютерных продуктов.
Следует заметить, что метод архитектурных спецификаций, основанный на построении эталонных моделей, используется для систематизации стандартов не только при стандартизации отдельных разделов ИТ, но и при разработке стандартов сложных технологий. Примером этому может служить разработка стандартов сетевых технологий ISDN и ATM. Разработанные для этих технологий эталонные модели будем называть специальными. В дальнейшем нас будут интересовать, прежде всего, эталонные модели общего назначения и те из них, которые имеют непосредственное отношение к формированию концепции открытых систем.
Как отмечалось, эталонные модели разрабатываются для структуризации достаточно крупных самостоятельных разделов области ИТ. Поэтому можно считать, что такие эталонные модели как бы осуществляют ортогонализацию пространства ИТ, определяя размерность этого пространства.
3.4.2 Базовые спецификации
Базовые спецификации, включающие стандарты ИТ и общедоступные спецификации (PAS), представляют собой основные строительные блоки, из которых конструируются профили ИТ. Хотя PAS не являются, строго говоря, международными стандартами, организацией ISO разработана специальная процедура быстрого баллотирования PAS в качестве международных стандартов, что открывает возможность использования PAS в качестве элементов стандартизованных профилей ИТ наравне с международными стандартами.
Разработка системного подхода к проектированию профилей приводит к целесообразности дальнейшей классификации базовых спецификаций. Для этого может оказаться полезной идея ортогонализации пространства спецификаций в соответствии с набором архитектурных спецификаций, соответствующих достаточно самостоятельным разделам ИТ.
Полагаясь на анализ текущего состояния системы стандартов ИТ, а также на опыт работы в области стандартизации, предложим один из возможных способов классификации базовых спецификаций, выделив следующий набор базисных разделов пространства спецификаций ИТ, при этом для каждого раздела будем указывать в скобках соответствующие ему архитектурные спецификации.
1. Базовые функции операционных систем (архитектурные специификации - RM OSE POSIX).
2. Функции взаимосвязи открытых систем (архитектурные специификации RM OSI).
3. Функции управления базами данных (архитектурные спецификации RM DM).
4. Функции пользовательского интерфейса и машинной графики (архитектурные спецификации RM CG).
5. Открытая распределенная обработка (архитектурные спецификации RM ODP).
6. Структуры данных и документов, форматы данных (архитектурные спецификации - ISO/IEC 8613-1).
7. Программная инженерия и управление качеством продуктов (архитектурные спецификации - ISO 12207, ISO 9000-9004), эргономика компьютерных продуктов (архитектурные спецификации - ISO 9241).
8. Административное управление (архитектурные спецификации ISO/IEC 7498-4, ISO/IEC 10040, ISO/IEC DIS 13244).
9. Управление безопасностью ИТ (архитектурные спецификации ISO/IEC 7498-2, ISO/IEC DTR 10181-1, ISO/IEC TR 13335, ISO/IEC 17799).
10. Тестирование конформности ИТ (архитектурные спецификации ISO/IEC 9646-1: 1994ЯТи-ТХ.29О, ISO/IEC DIS 13210).
При разработке профилей ИТ удобно использовать специальные каталоги базовых спецификаций. Такими каталогами могут быть стратегические профили или структурированные списки базовых спецификаций ИТ, составленные собственно разработчиками профилей. Рассмотренная выше классификация базисных разделов спецификаций ИТ может оказаться полезной при построении такого рода каталогов и списков.
3.4.3 Профили ИТ
При построении прикладных технологий и систем, как правило, приходится использовать некоторый набор базовых стандартов, выбирая для каждого стандарта необходимые в конкретном контексте функциональные возможности (опции) и значения параметров. Средством комплексирования наборов стандартов и их взаимного согласования с целью спецификации прикладной технологии или функции служит понятие профиля. Данное понятие и метод профилирования стандартов считаются фундаментальными и используются в процессах стандартизации различных областей деятельности, в том числе областей, не связанных с ИТ.
Как можно было видеть из предыдущего материала, существуют различные типы профилей. В частности, различаются профили, агрегирующие функциональность однородных спецификаций, т. е. спецификаций, относящихся к одному типу интерфейсов систем, от профилей, объединяющих стандарты разнородных интерфейсов. Также может быть полезным классификация профилей по степени полноты описания систем ИТ. Именно эти отличия используются в классификации профилей, представленной на рис. 3.2. Более полно концепция профиля, свойства профилей и принципы их разработки рассматриваются в последующих главах.
3.4.4 Стратегические профили
Экономическая целесообразность внедрения в практику концепции открытых систем привела к необходимости разработки профилей, играющих роль нормативно-методических документов на государственном уровне или на уровне отдельных отраслей и организаций. Такие профили мы назвали стратегическими. В системе стандартов POSIX такие профили называются профилями организаций (Organization specific profiles).
Примерами стратегических профилей, как уже отмечалось, являются: GOSIP - Government's Open Systems Interconnection Profile), IGOSS (Industry/ Government Open Systems Specifications), APP (Application Portability Profile).
Спецификации GOSIP (правительственные профили взаимосвязи открытых систем) определяют техническую политику в области сетевых технологий на уровне государств и ориентированы на применение в госбюджетных организациях. Наибольшая активность в разработке правительственных профилей приходилась на конец 80-х - начало 90-х годов. В США за разработку и сопровождение спецификаций GOSIP несет ответственность Национальный институт стандартизации и технологий NIST, который периодически обновляет версии GOSIP. Свои правительственные профили имеют многие развитые страны, в том числе: США, Великобритания, Франция, Япония, Австралия, Швеция и др.
Разработка IGOSS представляет собой попытку взаимного согласования стратегических профилей правительства США, Канады, разработчиков проекта электротехнической промышленности UCA (Utility Communication Architecture), а также пользователей стандартов MAP и ТОР (разработанных корпорациями General Motors и Boing в соответ-
ствии с моделью RM OSI). Версии IGOSS переиздавались примерно каждые два года.
Для более полной методологической поддержки целей открытости американским институтом стандартов NIST разработан и периодически обновляется профиль переносимости приложений АРР, основным предметом рассмотрения которого является функциональная среда открытых систем. В АРР такая среда формируется на основе спецификаций POSIX, GOSIP, TCP/IP, а также других спецификаций, обеспечивающих функциональные возможности, необходимые для удовлетворения разнообразных потребностей в области открытых систем. Спецификации АРР ориентированы на менеджеров и руководителей проектов, которые несут ответственность за приобретение, развитие и эксплуатацию информационных систем, поддерживаемых неоднородными аппаратными, программными и коммуникационными платформами.
Глава 4 Элементы теории информации и кодирования
4.1 Определение количества информации
В классической теории информации известно, по крайней мере, два определения количества информации [9, 10]. Оба определения очень близки между собой, принципиальное различие между ними появляется лишь при попытке ввести смысловое содержание информации. Первое определение (по Шеннону) рассматривает процесс передачи и переработки информации с вероятностной точки зрения, второе (по Хартли) использует комбинаторный подход.
Исходная гипотеза при определении количества информации по Шеннону – чем больше неопределенности в принятом сообщении, тем больше информации в нем содержится. Поэтому количество информации J определяют следующим образом:
 . (4.1)
. (4.1)
Здесь  - вероятность некоторого события после поступления информации в систему,
- вероятность некоторого события после поступления информации в систему,
 - вероятность того же события до поступления информации в систему.
- вероятность того же события до поступления информации в систему.
Если шумы отсутствуют, то можно считать, что вероятность данного события после поступления сообщения на вход системы  равна единице, тогда
равна единице, тогда
 . (4.2)
. (4.2)
Для измерения количества информации введена специальная единица измерения, которая называется бит (bit = binary digit). Количество информации J в битах равно правой части приведенных выше определений.
Пример
При наличии двух равновероятных событий в отсутствии шумов при  =1/2 количество переданной информации равно
=1/2 количество переданной информации равно
 бит.
бит.
Если же до поступления информации вероятность оценивалась величиной  =1/8, то количество переданной информации будет больше:
=1/8, то количество переданной информации будет больше:
 бит.
бит.
Возможны и другие определения количества информации. Рассмотрим комбинаторное определение информации, предложенное Хартли.
Сообщение, как правило, набирается или составляется из символов или элементов: буквенного алфавита, цифр, слов или фраз, названий цвета, предметов и так далее. Обозначим общее число символов в алфавите через т. Например, если сообщение формируется из двух независимо и равновероятно появляющихся символов, то нетрудно видеть, что число возможных комбинаций равно  . Действительно, зафиксировав один из двух символов сообщения
. Действительно, зафиксировав один из двух символов сообщения  и комбинируя его со всеми возможными т символами алфавита, получим
и комбинируя его со всеми возможными т символами алфавита, получим 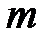 различных сообщений. После этого фиксируем следующий символ алфавита и снова его комбинируем со всеми символами алфавита, получим еще т сообщений. С учетом предыдущего имеем 2т сообщений. Продолжив этот процесс до тех пор пока будет зафиксирован последний из т символов алфавита, получим всего mm = т2 сообщений. В общем случае, если сообщение содержит п элементов (п — длина сообщения), число возможных сообщений
различных сообщений. После этого фиксируем следующий символ алфавита и снова его комбинируем со всеми символами алфавита, получим еще т сообщений. С учетом предыдущего имеем 2т сообщений. Продолжив этот процесс до тех пор пока будет зафиксирован последний из т символов алфавита, получим всего mm = т2 сообщений. В общем случае, если сообщение содержит п элементов (п — длина сообщения), число возможных сообщений
 .
.
Пример. Предположим, имеется набор из трех букв А, В, С, а сообщение формируется из двух.
Согласно приведенной выше формуле, число возможных сообщений будет АА, ВА, СА, АВ, ВВ, СВ, АС, ВС, СС, т. е. N =  = 9.
= 9.
Однако нетрудно видеть, что это выражение неудобно брать в качестве меры количества информации, так как, во-первых, если все множество или ансамбль возможных сообщений состоит из одного сообщения (N = 1), то информация в нем должна отсутствовать, во-вторых, если есть два независимых источника сообщений, каждый из которых имеет в своем ансамбле  и
и  сообщений, то общее число возможных сообщений от этих двух источников
сообщений, то общее число возможных сообщений от этих двух источников

т.е. является произведением, тогда как количества информации должны складываться, и общее количество должно быть прямо пропорционально числу символов в сообщении. Поэтому за количество информации берут двоичный логарифм числа возможных сообщений
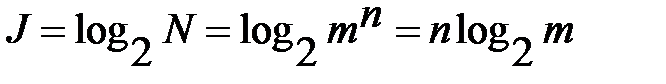 . (4.3)
. (4.3)
По существу, при выводе этого соотношения считалось, что появление символов в сообщении равновероятно и они статистически независимы. Чаще бывает наоборот. Так, в русском языке одни буквы встречаются чаще, другие — реже, после согласных, как правило, следуют гласные. Очевидно, в этом случае информации будет меньше.
Как правило, при приеме по телеграфу после первых слов можно с достаточной точностью предсказать следующие слова. Поэтому говорят о взаимосвязи элементов в сообщении. Связь понимается в вероятностном смысле, т. е. существует условная вероятность появления (при данном алфавите) символа А вслед символу В:
 .
.
Так, в русском тексте после гласной не может следовать мягкий знак или подряд четыре гласные буквы, т.е. условная вероятность таких комбинаций равна нулю. Если понятно, какие символы последуют дальше, сообщение представляет мало интереса и содержит меньше информации, чем оно содержало бы, если бы взаимная связь его элементов не была очевидна. В качестве примера взаимных связей можно привести прямой порядок слов в предложении, согласно которому после подлежащего должно следовать сказуемое: если принимается сообщение «Зима пришла», то достаточно принять «Зима при...», и получение следующих символов уже не добавит информации. Это свойство сообщений характеризуется величиной, называемой избыточностью.
Количество информации может уменьшаться также из-за того, что в силу особенностей языка различные символы с разной вероятностью появляются в тексте сообщения. Так, на 1000 букв приходится количество повторений, приведенное в таблице 4.1.
Таблица4.1
Частота повторения некоторых букв в английском и русском языке
| Английский язык | Русский язык | ||
| Буква | Частота повторения | Буква | Частота повторения |
| E | О | ||
| T | Е | ||
| A | А | ||
| O | И | ||
| N | Т | ||
| R | Н | ||
| I | С |
Так, буква E в английском языке встречается чаще буквы I, и этопозволяет предсказывать, предопределять сообщение. Таким образом, неравновероятное, неравномерное появление символов в сообщении (если, конечно, оно заранее известно) уменьшает количество сведений, количество информации в принимаемом сообщении.
Современный развитый язык насчитывает в своем составе до 100 тыс. слов. Однако не все они одинаково часто употребляются. В среднем достаточно знать несколько тысяч слов, чтобы изъясняться. Слова в языке также обладают разной вероятностью появления. Очевидно, что неравномерное распределение вероятностей появления отдельных слов в языке (максимум одних и минимум других) также уменьшает количество информации, так как можно предсказать появление тех или иных слов в сообщении.
Так же как в рассмотренной ранее теории случайных процессов, в теории информации к вероятности возможны два подхода – усреднение по времени и усреднение по множеству реализаций (сообщений). В первом случае рассматриваются бесконечно длинные (а практически просто длинные) сообщения. В процессе наблюдения во времени за длинным сообщением исследуется статистика появления отдельных символов или их комбинаций. Во втором случае рассматривается множество (теоретически бесконечно большое) конечных сообщений, и статистические характеристики определяются путем усреднения по ансамблю сообщений. При этом всегда предполагается, что число сообщений (или символов) такое большое, что применим закон больших чисел.
Приведем простейший вывод выражения для количества информации, предполагая отсутствие связей элементов. Пусть имеется алфавит, состоящий из  элементов (символов)
элементов (символов)
 .
.
Вероятности появления этих элементов в сообщении соответственно равны  . Составим из этих элементов сообщение, содержащее
. Составим из этих элементов сообщение, содержащее  элементов. Среди них будет
элементов. Среди них будет  элементов
элементов  элементов
элементов  элементов
элементов  . Вероятность появления каждой комбинации из
. Вероятность появления каждой комбинации из  элементов выразится произведением вероятностей отдельных элементов, так как предполагается, что появление каждого элемента есть независимое событие. С учетом повторяющихся элементов вероятность некоторого сообщения
элементов выразится произведением вероятностей отдельных элементов, так как предполагается, что появление каждого элемента есть независимое событие. С учетом повторяющихся элементов вероятность некоторого сообщения
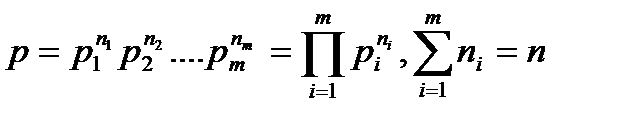 , (4.4)
, (4.4)
вероятность появления  -го символа
-го символа
 .
.
Общее число  возможных сообщений (все перестановки) равно
возможных сообщений (все перестановки) равно
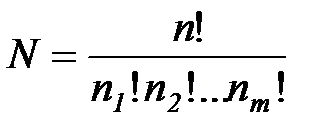 .
.
Можно считать, что все сообщения равновероятны. Поэтому
 ,
,
откуда число всевозможных сообщений

 Логарифмируя, получаем количество информации в сообщении длиной
Логарифмируя, получаем количество информации в сообщении длиной  при неравной вероятности его элементов:
при неравной вероятности его элементов:
 . (4.5)
. (4.5)
Пример. Имеются символы  . В этом случае
. В этом случае  Пусть число символов в каждом сообщении будет соответственно
Пусть число символов в каждом сообщении будет соответственно  . Возможные сообщения будут выглядеть следующим образом:
. Возможные сообщения будут выглядеть следующим образом:  Общее число сообщений
Общее число сообщений
 .
.
Отсюда при длине сообщения  количество информации будет равно
количество информации будет равно
 бит.
бит.
Из последней формулы нетрудно получить формулу, выведенную ранее для случая равновероятных событий, надо только положить все  .
.
В самом деле
 .
.
Если вероятность какого-нибудь элемента равна единице, а остальных нулю, то количество информации равно нулю, так как очевидно, что никакой информации сообщение не имеет: в этом случае заранее известно, что будет передан символ, вероятность которого равна единице. Наоборот, в случае  ситуация наиболее неопределенная и сообщение содержит максимальное количество информации.
ситуация наиболее неопределенная и сообщение содержит максимальное количество информации.
Рассмотрим теперь понятие энтропии. Количество информации на один символ сообщения носит название энтропии
 , так как
, так как
 . (4.6)
. (4.6)
Энтропия характеризует данный ансамбль сообщений с заданным алфавитом и является мерой неопределенности, которая имеется в ансамбле сообщений. Действительно, длина сообщения  имеет в известном смысле второстепенный характер: можно посылать длинные или короткие телеграммы, сочинять длинные или короткие стихотворные произведения, писать маленькие или большие полотна. Главное — определить, узнать статистические свойства данного ансамбля сообщений независимо от длины сообщения. Например, интересно узнать статистические особенности ансамбля стихотворных произведений Лермонтова, музыкальных произведений Бетховена. Одним из таких параметров, которые характеризуют свойства ансамбля сообщений, и является энтропия.
имеет в известном смысле второстепенный характер: можно посылать длинные или короткие телеграммы, сочинять длинные или короткие стихотворные произведения, писать маленькие или большие полотна. Главное — определить, узнать статистические свойства данного ансамбля сообщений независимо от длины сообщения. Например, интересно узнать статистические особенности ансамбля стихотворных произведений Лермонтова, музыкальных произведений Бетховена. Одним из таких параметров, которые характеризуют свойства ансамбля сообщений, и является энтропия.
Можно говорить об энтропии не на отдельный символ, а на  символов, где
символов, где  для всех сообщений. В этом случае, очевидно, что понятия энтропии и количества информации совпадают. Чем больше энтропия, тем больше информации несет в себе сообщение.
для всех сообщений. В этом случае, очевидно, что понятия энтропии и количества информации совпадают. Чем больше энтропия, тем больше информации несет в себе сообщение.
4.2 Понятие о кодировании
Кодирование – это представление символов из одного алфавита символами из другого алфавита, более удобными для передачи. Сообщения передаются в виде сигналов, имеющих определенную форму и последовательность. В телеграфе сообщение обычно передается при помощи алфавитов, цифр или алфавита и цифр вместе. Сигналы следуют в определенной последовательности. Например, в коде Морзе каждой букве и цифре соответствует некоторая последовательность кратких (точки) и длинных (тире) посылок тока, разделяемых кратковременными паузами по длительности такими же, как и точки. Пробел между буквами при этом изображается выключением тока на три единицы времени, а пробел между словами — на шесть единиц времени. Если обозначить тире 1, а точки 0, то образец этого кода виден в таблице.
|
|