Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Источники прерываний
|
|
Когда требуется прервать программу? Обычно, когда происходит какое-нибудь важное событие. Что является важным событием — необходимо определить самим, настроив разрешения прерываний от используемых модулей. Например, пришел байт на UART. Если его не обработать вовремя, то следующий пришедший байт затрет уже имеющийся, и, информация будет потеряна. Поэтому по приходу байта на UART необходимо «все бросить» и считать байт из приемного буфера. Итак, если в проекте используется UART, его необходимо настроить так, чтобы он генерировал прерывание по заполнению приемного буфера. Если это сделано — UART является источником прерывания. Кроме UART источниками прерываний обычно служат модули:
· АЦП
· Таймеры
· Внешние прерывания
· I2C
· SPI
· CAN
· EEPROM
· и т.д.
Можно сказать, что практически вся периферия может генерировать прерывания. Если периферия какого-либо микроконтроллера не может генерировать прерывания — это сильно ограничивает возможности микроконтроллера.
Кроме прочего, можно ошибочно подумать, что прерывания настраиваются только при запуске микроконтроллера. На самом деле это не так. Прерывания можно включать и отключать, или менять их приоритет в любом месте программы.
Каждый раз перед выполнением очередной команды CPU производит проверку наличия запроса прерывания INTR. При наличии запроса прерывания останавливается выполнение основной программы и происходит переход к обработке прерывания. Выясняется, разрешены ли прерывания (анализ состояния разряда IF регистра флагов). Если разрешены, то процессором выдается сигнал INTA в контроллер прерываний для получения номера вектора прерывания. В стеке сохраняется содержимое регистров и адрес текущей команды, чтобы был возможен возврат к выполнению основной программы. Затем выставляется запрет прерываний (IF=0). По номеру прерывания в таблице векторов определяется адрес обработчика прерывания. По этому адресу находится начало программы обработки прерывания. По окончании работы этой программы из стека извлекается содержимое регистра флагов и счетчика команд, происходит возврат к основной программе.
Контроллер необходим для слежения за соблюдением приоритетов прерываний, а также для присвоения номера каждому запросу.
Контроллер прерываний содержит регистр номера прерывания. При поступлении запроса на прерывание контроллер сравнивает приоритет текущего выполняемого кода и отбрасывает запрос на прерывание с меньшим или равным приоритетом. Старшая часть номера запроса может быть задана программно.
Каждая программа обработки прерывания завершается командой IRET, выполнение которой обеспечивает возврат к прерванной программе для продолжения ее выполнения.
Логическая схема обработки прерывания реализуется в виде программируемого контроллера прерываний (PIC), который располагается на кристалле вместе с CPU.
28. Прерывания. Векторы прерываний, приоритеты прерываний, маскирование прерываний.
Векторы прерываний
Для того чтобы связать адрес обработчика прерывания с номером прерывания, используется таблица векторов прерываний, занимающая первый килобайт оперативной памяти. Эта таблица находится в диапазоне адресов от 0000: 0000 до 0000: 03FFh и состоит из 256 элементов – дальних адресов обработчиков прерываний.
Элементы таблицы векторов прерываний называются векторами прерываний. В первом слове элемента таблицы записана компонента смещения, а во втором – сегментная компонента адреса обработчика прерывания.
Вектор прерывания с номером 0 находится по адресу 0000: 0000, с номером 1 - по адресу 0000: 0004 и т. д. В общем случае адрес вектора прерывания находится путем умножения номера прерывания на 4.
Инициализация таблицы выполняется частично системой базового ввода/вывода BIOS после тестирования аппаратуры и перед началом загрузки операционной системой, частично при загрузке MS-DOS. Операционная система MS-DOS может изменить некоторые вектора прерываний, установленные BIOS.
Таблица векторов прерываний
| Номер | Описание |
| 0h | Ошибка деления. Вызывается автоматически после выполнения команд DIV или IDIV, если в результате деления происходит переполнение (например, при делении на 0). Обычно при обработке этого прерывания MS-DOS выводит сообщение об ошибке и останавливает выполнение программы. При этом для процессора i8086 адрес возврата указывает на команду, следующую после команды деления, а для процессора i80286 и более поздних моделей - на первый байт команды, вызвавшей прерывание |
| 1h | Прерывание пошагового режима. Вырабатывается после выполнения каждой машинной команды, если в слове флагов установлен бит пошаговой трассировки TF. Используется для отладки программ. Это прерывание не вырабатывается после пересылки данных в сегментные регистры командами MOV и POP |
| 2h | Аппаратное немаскируемое прерывание. Это прерывание может использоваться по-разному в разных машинах. Обычно оно вырабатывается при ошибке четности в оперативной памяти и при запросе прерывания от сопроцессора |
| 3h | Прерывание для трассировки. Генерируется при выполнении однобайтовой машинной команды с кодом CCh и обычно используется отладчиками для установки точки прерывания |
| 4h | Переполнение. Генерируется машинной командой INTO, если установлен флаг переполнения OF. Если флаг не установлен, команда INTO выполняется как NOP. Это прерывание используется для обработки ошибок при выполнении арифметических операций |
| 5h | Печать копии экрана. Генерируется, если пользователь нажал клавишу < PrtSc>. В программах MS-DOS обычно используется для печати образа экрана. Для процессора i80286 и более старших моделей генерируется при выполнении машинной команды BOUND, если проверяемое значение вышло за пределы заданного диапазона |
| 6h | Неопределенный код операции или длина команды больше 10 байт |
| 7h | Особый случай отсутствия арифметического сопроцессора |
| 8h | IRQ0 – прерывание интервального таймера, возникает 18, 2 раза в секунду |
| 9h | IRQ1 – прерывание от клавиатуры. Генерируется, когда пользователь нажимает и отжимает клавиши. Используется для чтения данных из клавиатуры |
| Ah | IRQ2 – используется для каскадирования аппаратных прерываний |
| Bh | IRQ3 – прерывание асинхронного порта COM2 |
| Ch | IRQ4 – прерывание асинхронного порта COM1 |
| Dh | IRQ5 – прерывание от контроллера жесткого диска (только для компьютеров IBM PC/XT) |
| Eh | IRQ6 – прерывание генерируется контроллером НГМД после завершения операции ввода/вывода |
| Fh | IRQ7 – прерывание от параллельного адаптера. Генерируется, когда подключенный к адаптеру принтер готов к выполнению очередной операции. Обычно не используется |
| 10h | Обслуживание видеоадаптера |
| 11h | Определение конфигурации устройств в системе |
| 12h | Определение размера оперативной памяти |
| 13h | Обслуживание дисковой системы |
| 14h | Работа с асинхронным последовательным адаптером |
| 15h | Расширенный сервис |
| 16h | Обслуживание клавиатуры |
| 17h | Обслуживание принтера |
| 18h | Запуск BASIC в ПЗУ, если он есть |
| 19h | Перезагрузка операционной системы |
| 1Ah | Обслуживание часов |
| 1Bh | Обработчик прерывания, возникающего, если пользователь нажал комбинацию клавиш < Ctrl+Break> |
| 1Ch | Программное прерывание, вызывается 18, 2 раза в секунду обработчиком аппаратного прерывания таймера |
| 1Dh | Адрес видеотаблицы для контроллера видеоадаптера 6845 |
| 1Eh | Указатель на таблицу параметров дискеты |
| 1Fh | Указатель на графическую таблицу для символов с кодами ASCII 128-255 |
| 20h-5Fh | Используется MS-DOS или зарезервировано для MS-DOS |
| 60h-67h | Прерывания, зарезервированные для программ пользователя |
| 68h-6Fh | Не используются |
| 70h | IRQ8 – прерывание от часов реального времени |
| 71h | IRQ9 – прерывание от контроллера EGA |
| 72h | IRQ10 – зарезервировано |
| 73h | IRQ11 – зарезервировано |
| 74h | IRQ12 – зарезервировано |
| 75h | IRQ13 – прерывание от арифметического сопроцессора |
| 76h | IRQ14 – прерывание от контроллера жесткого диска |
| 77h | IRQ15 – зарезервировано |
| 78h - 7Fh | Не используются |
| 80h-85h | Зарезервировано для BASIC |
| 86h-F0h | Используются интерпретатором BASIC |
| F1h-FFh | Не используются |
Прерывания, обозначенные как IRQ0 – IRQ15 являются внешними аппаратными.
приоритеты прерываний
Помимо простой установки приоритета прерываний, NVIC реализует возможность группировки приоритетов.
Прерывания в группе с более высоким приоритетом могут прерывать обработчики прерываний группы с более низким приоритетом. прерывания из одной группы, но с разным приоритетом внутри группы не могут прерывать друг друга. Приоритет внутри группы определяет только порядок вызова обработчика, когда были активизированы оба события.
Значение приоритета прерывания задается в регистрах Interrupt Priority Registers (см. Cortex-M4 Generic User Guide). При этом, часть бит отвечает за приоритет группы, в которой находится прерывание, а часть — за приоритет внутри группы.
Настройка распределение бит на приоритет группы или приоритет внутри группы осуществляется с помощью регистра Application Interrupt and Reset Control Register (ВНИМАТЕЛЬНО!!! см. Cortex-M4 Generic User Guide).
Как вы, наверно, заметили, в Cortex-M4 Generic User Guide сказано, что настройка приоритетов и группировки приоритетов зависят от конкретной реализации implementation defined.
А вот дальше не очень приятная вещь. В Reference manual к МК STM32F407 про NVIC почти нет информации. Но есть ссылка на отдельный документ. Для того, чтобы разобраться с реализацией NVIC в STM32 придется прочитать еще один документ — STM32F3xxx and STM32F4xxx Cortex-M4 programming manual. Вообще говоря, я советую внимательно изучить данный документ и по всем другим вопросам, в нем работа ядра расписана более подробно, чем в документации от ARM.
маскирование прерываний.
Сигналы, вызывающие прерывания, формируются вне процессора или в самом процессоре, они могут возникать одновременно. Выбор одного из них для обработки осуществляется на основе приоритетов, приписанных каждому типу прерывания. Так, со всей очевидностью, прерывания от схем контроля процессора должны обладать наивысшим приоритетом (действительно, если аппаратура работает неправильно, то не имеет смысла продолжать обработку информации). Учет приоритета может быть встроен в технические средства, а также определяться операционной системой, то есть кроме аппаратно реализованных приоритетов прерывания большинство вычислительных машин и комплексов допускают программно-аппаратное управление порядком обработки сигналов прерывания. Второй способ, дополняя первый, позволяет применять различные дисциплины обслуживания прерываний.
Наличие сигнала прерывания не обязательно должно вызывать прерывание исполняющейся программы. Процессор может обладать средствами защиты от прерываний: отключение системы прерываний, маскирование (запрет) отдельных сигналов прерывания. Программное управление этими средствами (существуют специальные команды для управления работой системы прерываний) позволяет операционной системе регулировать обработку сигналов прерывания, заставляя процессор обрабатывать их сразу по приходу; откладывать обработку на некоторое время; полностью игнорировать прерывания. Обычно операция прерывания выполняется только после завершения выполнения текущей команды. Поскольку сигналы прерывания возникают в произвольные моменты времени, то на момент прерывания может существовать несколько сигналов прерывания, которые могут быть обработаны только последовательно. Чтобы обработать сигналы прерывания в разумном порядке, им (как уже отмечалось) присваиваются приоритеты. Сигнал с более высоким приоритетом обрабатывается в первую очередь, обработка остальных сигналов прерывания откладывается.
29. Прямой доступ к памяти
Прямой доступ к памяти (англ. Direct Memory Access, DMA) —режим обмена данными между устройствами или же между устройством и основной памятью (RAM) безучастия Центрального Процессора (ЦП). В результате скорость передачи увеличивается, так как данные непересылаются в ЦП и обратно.
Кроме того, данные пересылаются сразу для многих слов, расположенных по подряд идущим адресам, чтопозволяет использование т. н. «пакетного» (burst) режима работы шины — 1 цикл адреса и следующие заним многочисленные циклы данных. Аналогичная оптимизация работы ЦП с памятью крайне затруднена.
В оригинальной архитектуре IBM PC (шина ISA) был возможен лишь при наличии аппаратного DMA-контроллера (микросхема с индексом Intel 8237).
DMA-контроллер может получать доступ к системной шине независимо от центрального процессора.Контроллер содержит несколько регистров, доступных центральному процессору для чтения и записи.Регистры контроллера задают порт (который должен быть использован), направление переноса данных(чтение/запись), единицу переноса (побайтно/пословно), число байтов, которое следует перенести.
ЦП программирует контроллер DMA, устанавливая его регистры. Затем процессор даёт команду устройству(например, диску) прочитать данные во внутренний буфер. DMA-контроллер начинает работу, посылаяустройству запрос чтения (при этом устройство даже не знает, пришёл ли запрос от процессора или отконтроллера DMA). Адрес памяти уже находится на адресной шине, так что устройство знает, куда следуетпереслать следующее слово из своего внутреннего буфера. Когда запись закончена, устройство посылаетсигнал подтверждения контроллеру DMA. Затем контроллер увеличивает используемый адрес памяти иуменьшает значение своего счётчика байтов. После чего запрос чтения повторяется, пока значение счётчикане станет равно нулю. По завершении цикла копирования устройство инициирует прерывание процессора, означающее завершение переноса данных. Контроллер может быть многоканальным, способнымпараллельно выполнять несколько операций.
30. Суперскалярная обработка команд
Конвейеризация обеспечивает параллельную обработку команд. При использовании этой технологии конвейер содержит несколько команд, находящихся на разных ступенях выполнения. Пока первая команда производит операцию АЛУ, вторая декодируется, а третья выбирается из памяти. Команды поступают в конвейер в том порядке, в каком они располагаются в программе. При отсутствии конфликтов на каждом такте в конвейере завершается выполнение очередной команды и появляется новая команда. Таким образом, максимальная пропускная способность конвейера равна одной команде за такт.
С целью повышения производительности процессор может быть оборудован несколькими обрабатывающими устройствами, чтобы на каждом из них обрабатывалось параллельно несколько команд. При такой организации процессора на одном такте может быть запущено на выполнение нескольких команд. Процессоры такого типа называются суперскалярными. Суперскалярную архитектуру имеют многие современные высокопроизводительные процессоры.
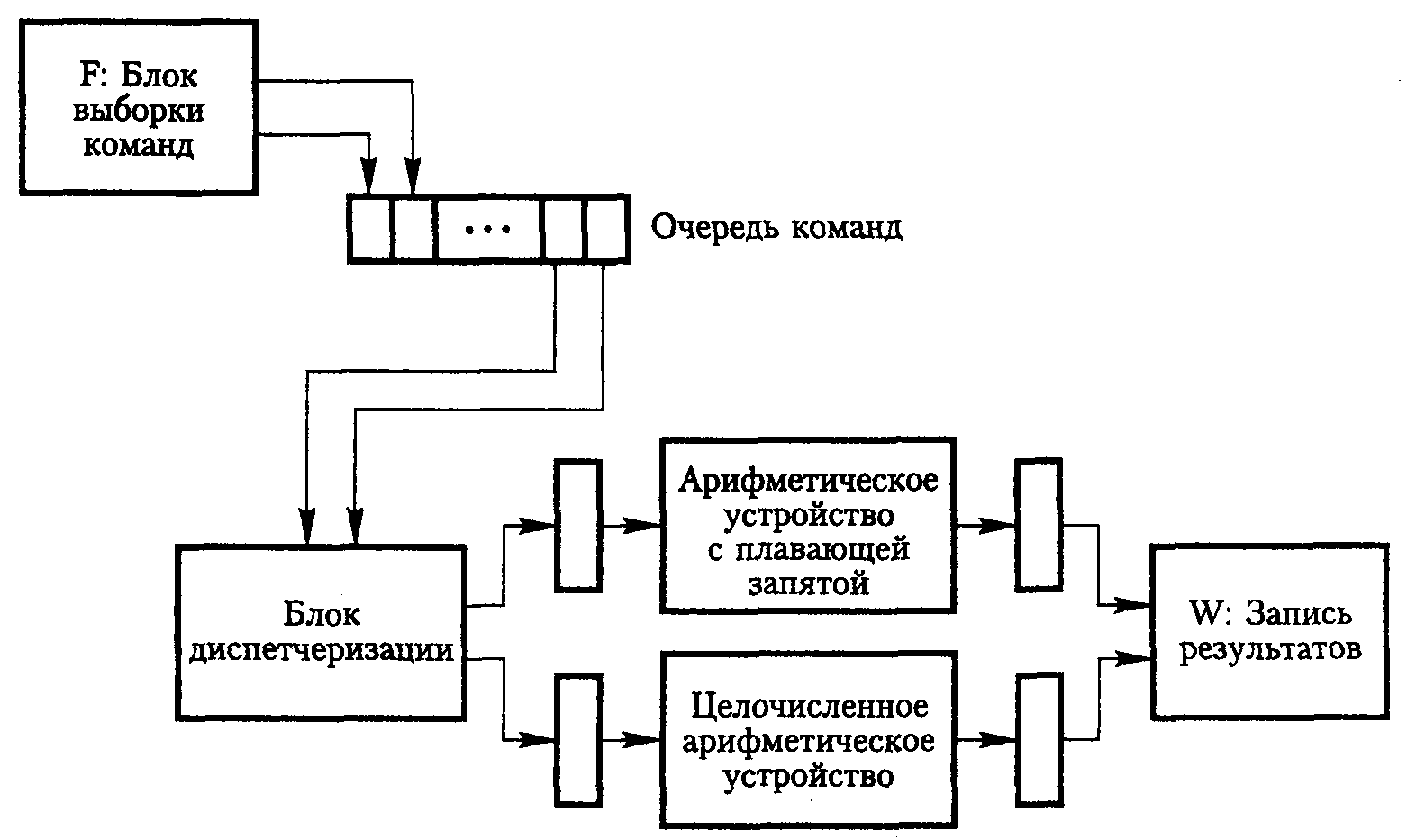
Чтобы поддерживать очередь команд заполненной, процессор должен иметь возможность выбирать из кэша несколько команд за раз. Это особенно важно для суперскалярного режима выполнения команд, которому требуется более широкое соединение с кэш-памятью и несколько блоков выполнения. В частности, целочисленным командам и командам с плавающей запятой в суперскалярном процессоре отведены раздельные блоки выполнения.
На рис. 9.9 приведен пример процессора с двумя блоками выполнения: для целочисленных операций и операций с плавающей запятой. Блок выборки команд способен считывать из кэша по две команды за раз и сохранять их в очереди. На каждом такте блок диспетчеризации извлекает из очереди и декодирует одну или две команды. Если одна из команд обрабатывает целочисленные значения, а другая — числа с плавающей запятой, при отсутствии конфликтов обе команды диспетчеризируются на одном такте.
В суперскалярном процессоре конфликты сильнее влияют на производительность, чем в обычном конвейерном процессоре. Компилятор предотвращает многие конфликты, оптимальным образом выбирая и переупорядочивая команды. Например, для процессора, показанного на рис. 9.9, он может обеспечить чередование операций с плавающей запятой и целочисленных операций. Это позволит блоку диспетчеризации поддерживать непрерывную работу целочисленного арифметического устройства и арифметического устройства с плавающей запятой. В общем случае предельное повышение производительности достигается за счет такого переупорядочения команд компилятором, при котором максимально используются возможности всех доступных устройств.
31.Сегментация памяти для семейства процессоров IA-32. Реальный и защищенный режим.
В разделе 5.1 кратко рассказывалось об использовании сегментных регистров в архитектуре IA-32 для формирования адресов памяти (см. рис. 5.1). Мы продолжим развивать эту тему. Для начала читателю полезно будет узнать, как сегментные регистры использовались в процессоре 8086. Более современные процессоры IA-32 способны функционировать в так называемом реальном режиме, где они могут выполнять машинный программный код процессора 8086.
|
|