Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Генератори імпульсів струму електрогідравлічних випромінювачів
|
|
Генератор імпульсів струму (ГІТ) призначений для формування багаторазово повторюваних імпульсів струму, що відтворюють електрогідравлічний ефект. Принципові схеми ГІТ були запропоновані ще в 1950-х роках [4, 7, 9] та за минулі роки не зазнали істотних змін, проте значно вдосконалилися їх комплектуюче обладнання і рівень автоматизації. Сучасні ГІТ призначені для раб'оти в широкому діапазоні напруги (5-100 кВ), ємності конденсатора (0, 1 -10000 мкФ), збереженої енергії накопичувача (10-106 Дж), частоти проходження імпульсів (0, 1 -100 Гц).
Наведені параметри охоплюють велику частину режимів, в яких працюють електрогідравлічні установки різного призначення. Вибір схеми ГІТ визначається відповідно до призначення конкретних електрогідравлічних пристроїв. Кожна схема генератора включає в себе наступні основні блоки: блок живлення - трансформатор з випрямлячем; накопичувач енергії - конденсатор; комутуючі пристрій - формуючий (повітряний) проміжок; навантаження - робочий іскровий проміжок. Крім того, схеми ГІТ включають в себе струмообмежуючий елемент (це може бути опір, ємність, індуктивність або їх комбіновані поєднання). У схемах ГІТ може бути декілька формують і робочих іскрових проміжків і накопичувачів енергії. Харчування ГІТ здійснюється, як правило, від мережі змінного струму промислової частоти й напруги.
ГІТ працює таким чином. Електрична енергія через струмообмежувальним елемент і блок живлення надходить в накопичувач енергії - конденсатор. Запасена в конденсаторі енергія за допомогою комутуючого пристрою - повітряного формує проміжку - імпульсно передається на робочий проміжок в рідині (або іншому середовищі), на якому відбувається виділення електричної енергії накопичувача, в результаті чого виникає електрогідравлічний удар. При цьому форма і тривалість імпульсу струму, що проходить по розрядної ланцюга ГІТ, залежать як від параметрів зарядного контуру, так і від параметрів розрядного контуру, включаючи і робочий іскровий проміжок.
Якщо для одиночних імпульсів спеціальних ГІТ параметри ланцюга зарядного контуру (блоку живлення) не роблять істотного впливу на загальні енергетичні показники електрогідравлічних установок різного призначення, то в промислових ГІТ ККД зарядного контуру суттєво впливає на ККД електрогідравлічної установки.
Використання в схемах ГІТ реактивних токообмежуючих елементів обумовлено їх властивість накопичувати і потім віддавати енергію в електричний ланцюг, що в кінцевому рахунку підвищує ККД. Електричний ККД зарядного контуру простою і надійною в експлуатації схеми ГІТ з обмежуючим активним зарядним опором (рис. 3.1, а) дуже низький (30-35%), так як заряд конденсаторів здійснюється в ній пульсуючими напругою і струмом.
Введенням в схему спеціальних регуляторів напруги (магнітного підсилювача, дроселя насичення) можна домогтися лінійної зміни вольт-амперної характеристики заряду ємнісного накопичувача і тим самим створити умови, при яких втрати енергії в зарядної ланцюга будуть мінімальні, а загальний ККД ГІТ може бути доведений до 90% [4].
Для збільшення загальної потужності при використанні найпростішої схеми ГІТ крім можливого застосування більш потужного трансформатора доцільно іноді використовувати ГІТ, що має три однофазних трансформатора, первинні ланцюги яких з'єднані «звездой» або «треугольником» і живляться від трифазної мережі. Напруга з їх вторинних обмоток подається на окремі конденсатори, які працюють через обертовий формує проміжок на один загальний Робочий-іскровий проміжок.
При проектуванні та розробці ГІТ електрогідравлічних установок значний інтерес представляє використання резонансного режиму заряду ємнісного накопичувача від джерела змінного струму без випрямляча. Загальний електричний ККД резонансних схем дуже високий (до 95%), а при їх використанні відбувається автоматичне значне підвищення робочої напруги. Резонансні схеми доцільно використовувати при роботі на великих частотах (до 100 Гц,), але для цього потрібні спеціальні конденсатори, призначені для роботи на змінному струмі.
1.6 Реалізація систем розпізнавання мови
Системи мовного обміну між людиною і машиною можна поділити на три класи: з мовним відповіддю, розпізнавання диктора і розпізнавали мови.
Системи з мовним відповіддю призначаються для видачі інформації користувачеві у формі мовного повідомлення. Таким чином, системи з мовним відповіддю - це системи одностороннього зв'язку, т. Е. Від машини до людини. З іншого боку, системи другого і третього класів - це системи зв'язку від людини до машини. У системах розпізнавання диктора завдання полягає у верифікації диктора (т. Е. У вирішенні завдання про приналежність даного диктора до певної групи осіб) або ідентифікації диктора з деякого відомої множини. Таким чином, клас задач розпізнавання диктора розпадається на два підкласу: верифікації та ідентифікації мовця.
Останній клас задач розпізнавання мови також можна розділити на підкласи залежно від таких факторів, як розмір словника, кількість дикторів, умови проголошення слів і т. Д. Основне завдання розпізнає зводиться або до точного розпізнавання виголошеній на вході фрази (тобто система фонетичної або орфографічною друку сказаного тексту), або до «розуміння» виголошеній фрази (т. е. до правильної реакції на сказане диктором). Саме завдання розуміння, а не розпізнавання найбільш важлива для систем з досить великим словником безперервних мовних сигналів, у той час як завдання точного розпізнавання більш важлива для систем з обмеженням словником, малою кількістю дикторів, систем розпізнавання ізольованих слів.
Як і при розпізнаванні диктора, методи цифрової обробки застосовуються при розпізнаванні мовного сигналу для отримання опису розпізнаваного образу, яке потім порівнюється з збереженими в пам'яті еталонами. Завдання розпізнавання мовного сигналу полягає у визначенні того, яке слово, фраза або речення були вимовлені.
На відміну від областей машинного мовного відповіді і розпізнавання диктора, де завдання в загальному випадку досить визначена, область розпізнавання слів є однією з тих, де, перш ніж поставити завдання, потрібно ввести велике число припущень наприклад:
- Тип мовного сигналу (ізольовані слова, безперервна мова і т.д.);
- Число дикторів (система для одного диктора, кількох дикторів, необмеженого числа дикторів);
- Тип диктора (певний, випадковий, чоловік, жінка, дитина);
- Умови проголошення фраз (звукоізольовані приміщення, машинний зал, громадське місце);
- Система передачі (високоякісний мікрофон, вузькоспрямований мікрофон, телефон);
- Тип і число циклів навчання (без навчання, з обмеженим числом циклів навчання, з необмеженим числом циклів навчання);
- Розмір словника (малий обсяг 80-20 слів, середній обсяг 20-100 слів і великий обсяг - понад 100 слів);
- Формат вимовлених фраз (обмежений по тривалості текст, вільний мовної формат).
З наведеного переліку умов випливає, що при створенні систем розпізнавання мови реалізація деяких з умов може виявитися більш кращою.
Існує багато способів подання сигналу, які можна використовувати в системах розпізнавання мови, надання, застосовувані в системах, інваріантних до диктора, повинні бути достатньо стійкими. Вимірювання параметрів повинні бути простими й однозначними, а їх виміряні значення повинні найбільш повно відображати відмінності в звуках мови. Крім того, вимірювання повинні допускати досить просту інтерпретацію з позицій систем, інваріантних до диктора. У багатьох таких системах використані наступні параметри: середнє число переходів через нуль, енергія, коефіцієнти лінійного передбачення з використанням двополюсної моделі і похибка передбачення.
В даний час відсутні дикторонезалежної системи розпізнавання злитої мови як з необмеженим словником, так і обмеженим, а наявні системи (такі як Дракон диктат - програма для друку тексту з голосу) вимагають дуже багато часу і терпіння для того, щоб навчити їх задовільно розпізнавати роздільно вимовлені слова одного диктора. Серед інших розпізнають систем можна назвати Lotus Word Pro, MedSpeak, Голос Тип Спрощення кажучи, ViaVoice Курцвейл Голос. Він вимагають навчання системи розпізнають зазвичай від декількох десятків до сотень слів і використовуються для подачі команд голосом. Однак вони також є дікторозавісімимі. У цій же області залишається реалізація амбітних планів, наподобии прийнятого в 1986 в Японському національному проекті АТК (Advanced Research телекомунікації), який полягав у тому, щоб отримувати мова на одній мові і одночасно синтезувати її на іншому або твердження про реалізації ідеї людино-машинного спілкування, Тому дослідження в цій області є дуже актуальними.
В даний час, у зв'язку з бурхливим розвитком технологій комп'ютерної обробки звуку часто постає завдання автоматичного визначення ступеня схожості музичних композицій. Дана міра ступеня схожості називається метрикою. Якісний метричний алгоритм, який видає адекватний на слух результат незамінний при кодуванні звуку з втратами, при розробці алгоритмів відновлення високих частот, відфільтрованих при стисненні, і т.п. Алгоритм можна застосовувати як при розробці аудіо кодека для перевірки якості кодування звуку та порівняння з іншими аналогічними кодеками, так і в процесі кодування для кодування в режимі < постійної якості>.
Найбільш простий клас метрик порівняння якості звуку - це порівняння звукового сигналу за формою хвилі. У цій ситуації порівнюється значення сигналів для кожного моменту часу. Наприклад, можна порівнювати максимальне відхилення амплітуд сигналів.
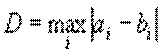 , де вектори a і b -
, де вектори a і b -
це значення амплітуди двох сигналів.
Така метрика буде вкрай чутлива по одиничним відмінностям в амплітудах сигналів.
Іншим критерієм оцінки може служити середньоквадратичне відхилення амп-літуд сигналів RMS (середньоквадратичне):
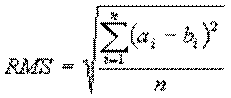
На практиці використовується модифікація даної міри, так звана PSNR (peak-to-peak signal-to-noise ratio).
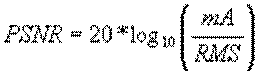 , де mA - максимально можлива амплітуда сигналу
, де mA - максимально можлива амплітуда сигналу
У порівнянні з RMS дана міра хороша тим, що обчислюється в логарифмічною шкалою за амплітудою (в децибелах). Це важливо, тому людське вухо сприймає сигнал також в логарифмічною шкалою за амплітудою і тому посилення амплітуди сигналу в двічі не означає для людини посилення гучності звуку в стільки ж разів.
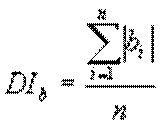
Одним з недоліків даної міри є висока чутливість до середнього відмінності сигналів за амплітудою, що може призвести до помилкового результату, у випадку, коли сигнали трохи відрізняються в середньому по амплітуді. Для контролю помилок такого роду можна використовувати дану метрику спільно з розрахунком середньо інтегрального значення для порівнюваних файлів:
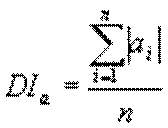 ;
; 
У сигналах, у яких співпадають середньо інтегральні значення, збігається і середня амплітуда, що означає можливість застосування PSNR як міри.
Залишається ще кілька проблем, які ускладнюють використання цієї міри. Ось найбільш важливі з них:
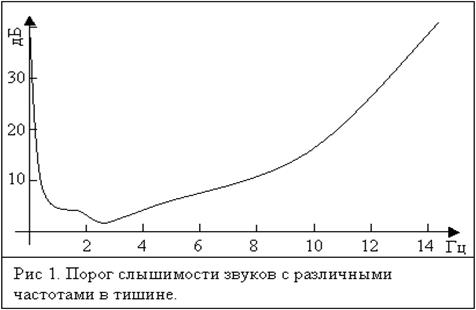
1. 1. Людське вухо має різну чутливість до спотворень в різних частинах частотного діапазону, так як має різну чутливість до звуку на різних частотах. (Рис.1) Спотворення на низьких і середніх частотах людина чує краще, ніж на високих. Це пов'язано з тим, що вухо в першу чергу пристосоване сприймати мову, основний діапазон частот якої лежить в області 50-5000Гц.
2. Людина однаково чує звуки, які можуть сильно відрізнятися за формою хвилі. Наприклад, білий шум буде чутися людині однаково, незалежно від того, якої форми буде сигнал, що містить білий шум.
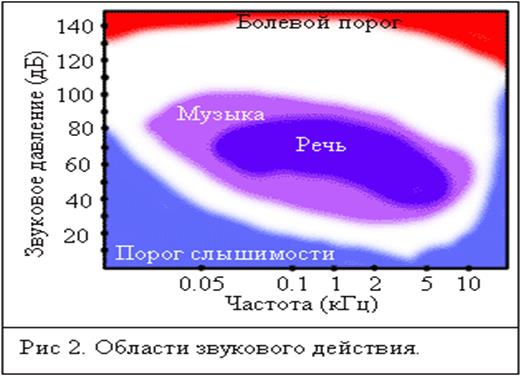
PSNR метрика не може враховувати різну чутливість вуха в різних частотних смугах, а при порівнянні двох різних сигналів з білим шумом швидше за все дасть висновок про те, що вони абсолютно різні.
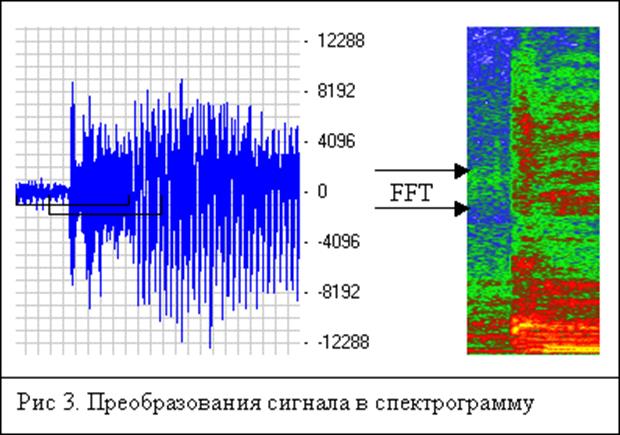
Якісно інший метод порівняння - порівняння спектрограм, побудованих по вхідному сигналу. Для отримання даної метрики вхідні сигнали спочатку послідовно покриваються невеликими інтервалами з деяким кроком по часу DT. У кожному з цих інтервалів сигнал розкладається в ряд Фур'є, після чого будуватися спектр (без урахування фаз частотних складових). Отримані спектри записуються в двовимірний масив (час, частота) - спектрограму (рис 3).
Амплітуди значень спектрограми в кожній конкретній області також представляються у логарифмічною шкалою.
Можна побудувати подібну PSNR-міру метрику для порівняння отриманих двовимірних масивів-спектрограм.
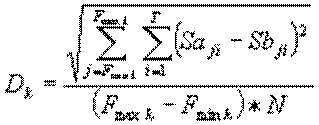
Переваги даної метрики над описаною вище буде полягати в тому, що можна порівнювати значення сигналу, згідно з даними про сприйняття людиною тієї чи іншої частотної складової. Тобто проводити порівняння за формулою:
 Sa, Sb - двовимірні масиви амплітуд спектрограм двох вхідних сигналів і б.
Sa, Sb - двовимірні масиви амплітуд спектрограм двох вхідних сигналів і б.
де коефіцієнт залежить від чутливості вуха в даній J-ой частотної по-лося, значення для якої виходять експериментально і аналогічні значенням на рис 1.
Функція, зображена на малюнку 1, може бути апроксимована наступним чином:
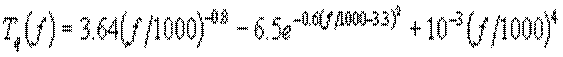
Для даного методу, як і для амплітудно-часової PSNR, так само необхідно, щоб сигнали містили однакову енергію, тобто середньоквадратичне відхилення в спектрах для всього звукового сигналу має бути мінімальним. У порівнянні зі звичайною PSNR метрикою в даній мірі практично вирішується проблема порівняння сигналів з різними амплітудами і враховується нерівномірна чутливість вуха до різних частотним складовим.
Для тестування якості стиснення звукових кодеків більш правильно застосовувати модифікацію даного методу: З спектрограми послідовно викарбовується кілька частотних смуг, і в них вважається середньоквадратичне відхилення.
Частотні смуги вибираються неоднаковою ширини, тому змістовної ін-формації для людського вуха в районі одного кілогерцах більше, ніж у
районі двадцяти кілогерц, отже і смуги в низькочастотної області беруться вже, ніж в високочастотної.
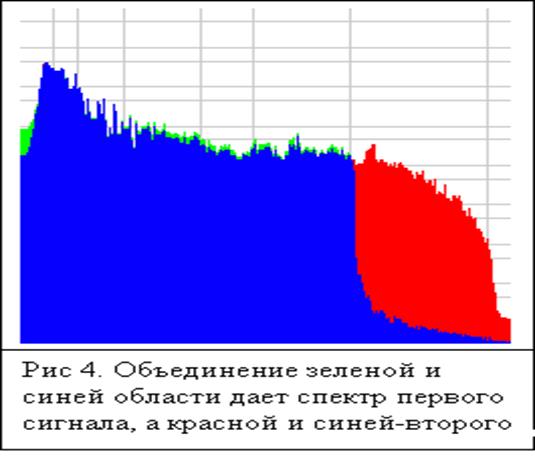
Перевага даного методу в тому, що можливо порівняння звукових сигна лов-, оброблених фільтром низьких частот для зменшення кількості кодируемой інформації. У цьому випадку такі сигнали можна порівнювати тільки по тих частотним смугам, які кодек зберігав. Також в даному випадку не обов'язково, щоб кодек правильно зберігав енергію у всьому частотному просторі. При коректному збереженні енергії сигналу в частотній смузі можна буде досить вірно порахувати середнє відміну звуку в цій смузі. На рис. 4 зображено неправильне збереження енергії як в среднечастотной області, так і в високочастотної. На середніх частотах другий сигнал має більшу потужність, ніж перший, а на високих частотах сигнал навпаки відфільтрований.
Одним з недоліків є мала дозвіл як за частотою, так і за часом.
У міжнародному стандарті ISO / R-226 (таблиця 1) прийняті за стандартні наступні значення порогів чутності (гучномовець розміщений у вільному полі на осі, слухачі віком 18: 30років):
| Частота, Гц | |||||||
| Рівень, дБ | 25, 5 | 11, 5 | 7, 0 | 9, 0 | 9, 5 | 13, 0 |
Однак для побудови якісної заходи, адекватної людському сприйняттю звуку, мало використовувати тільки знання про нерівномірну чутливості вуха до різних частотним складовим у звуці. Також необхідно брати до уваги такі факти, отримані експериментальним шляхом:
1. Динамічний діапазон сприйманих людиною звуків від самого ти-хого до найгучнішого становить порядку 96 дБ.
2. Людина в стані розрізняти зміна частоти на 0, 3% на частоті 1000 Гц.
3. Дві гармоніки, що знаходяться на близьких частотах можуть зливатися в одну.
4. Частотне маскування. Більш сильний звук маскує близькі за частотою тихі звукові складові.
Тимчасове маскування. Перед і після різкої звуковий атаки людина не здатна детально розрізняти звуки.
|
|