Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Лабораторная работа на тему
|
|
Институт технической кибернетики и информатики
Кафедра компьютерных систем
Отчет по педагогической практике
по лабораторным занятиям дисциплины
«Высокопроизводительные вычисления»
Подготовил: маг. гр. 4293
Классен Р.К.
Руководитель: Гибадуллин Р.Ф.
Казань 2015
Лабораторные занятия по дисциплине
«Высокопроизводительные вычисления»
Цели:
1. Обучающая: изучение архитектуры GPGPU, вопросов вычислений на GPGPU с помощью языка CUDA, библиотеки CUDAfy.NET. Рассмотрение примера программы, написанной на языке программирования C# с использованием библиотеки CUDAfy.NET.
2. Развивающая: развитие умений и навыков работ с вычислениями на GPU и библиотекой CUDAfy.NET.
3. Воспитывающая: выработка навыков проведения исследования.
Задача:
Освоение студентами принципов разработки специализированных программ для работы с GPGPU на языке программирования C# с использованием библиотеки CUDAfy.NET.
Метод проведения:
1. Разъяснение теоретических основ.
2. Проведение опроса по полученным и имеющимся теоретическим знаниям.
3. Показ и пояснение принципа работы с GPGPU при помощи библиотеки CUDAfy.NET.
4. Написание программы и проведение исследований.
5. Обсуждение полученных результатов.
По окончании 2-х лабораторных занятий с каждым проводится собеседование с выставлением оценки.
Так как занятия схожи по методике проведения, то ограничимся рассмотрением одной из них.
Лабораторная работа на тему
«Вычислениями на GPU с помощью библиотеки CUDAfy.NET»
Цель работы
Ознакомиться с библиотекой CUDAfy.NET и написать программы, которые будут использовать GPU для вычислений.
Вычисления на GPU
GPGPU (англ. General-purpose graphics processing units — «GPU общего назначения») — техника использования графического процессора видеокарты, который обычно имеет дело с вычислениями только для компьютерной графики, чтобы выполнять расчёты в приложениях для общих вычислений, которые обычно проводит центральный процессор. Это стало возможным благодаря добавлению программируемых шейдерных блоков и более высокой арифметической точности растровых конвейеров, что позволяет разработчикам ПО использовать потоковые процессоры для неграфических данных.
Различия CPU и GPU (рис. 1):
CPU:
• Память оптимизирована под минимальную латентность (система " кэшей”).
• Много транзисторов " управления” (предсказание ветвлений, планировщики и пр.).
• Архитектура оптимизирована для программ со сложным управлением (эффективная обработка ветвлений).
GPU:
• Память оптимизирована под максимальную пропускную способность (" иерархия памяти”).
• Большая часть транзисторов - для вычислений.
• Архитектура оптимизирована для программ с большим объемом вычислений (параллелизм по данным типа SIMD).
• Латентность скрывается вычислениями во время запросов к памяти.
Вместо системы " кэшей” и сложных АЛУ – множество упрощённых АЛУ, имеющих общую память на кристалле. Программист должен тщательно рассчитывать размещение алгоритма на исполняющих элементах и продумывать стратегии доступа к памяти.
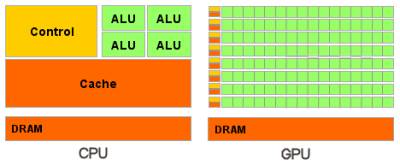
Рис. 1 – Различия архитектур CPU и GPU
CUDA
CUDA (англ. Compute Unified Device Architecture) — программно-аппаратная архитектура параллельных вычислений, которая позволяет существенно увеличить вычислительную производительность благодаря использованию графических процессоров фирмы Nvidia.
CUDA SDK позволяет программистам реализовывать на специальном упрощённом диалекте языка программирования Си алгоритмы, выполнимые на графических процессорах Nvidia, и включать специальные функции в текст программы на Си. Архитектура CUDA даёт разработчику возможность по своему усмотрению организовывать доступ к набору инструкций графического ускорителя и управлять его памятью.
Первоначальная версия CUDA SDK была представлена 15 февраля 2007 года. В основе интерфейса программирования приложений CUDA лежит язык Си с некоторыми расширениями. Для успешной трансляции кода на этом языке в состав CUDA SDK входит собственный Си-компилятор командной строки nvcc компании Nvidia. Компилятор nvcc создан на основе открытого компилятора Open64 и предназначен для трансляции host-кода (главного, управляющего кода) и device-кода (аппаратного кода) (файлов с расширением.cu) в объектные файлы, пригодные в процессе сборки конечной программы или библиотеки в любой среде программирования.
В архитектуре CUDA используется модель памяти грид, кластерное моделирование потоков и SIMD-инструкции. Применима не только для высокопроизводительных графических вычислений, но и для различных научных вычислений с использованием видеокарт Nvidia. Ученые и исследователи широко используют CUDA в различных областях, включая астрофизику, вычислительную биологию и химию, моделирование динамики жидкостей, электромагнитных взаимодействий, компьютерную томографию, сейсмический анализ и многое другое. CUDA — кроссплатформенное программное обеспечение для таких операционных систем как Linux, Mac OS X и Windows.
Пример программы на C с использованием CUDA:
__global__ void add(int *a, int *b, int *c) {
int index = threadIdx.x + blockIdx.x * blockDim.x;
c[index] = a[index] + b[index];
}
#define N (2048*2048)
#define THREADS_PER_BLOCK 512
int main(void) {
int *a, *b, *c; // host копии a, b, c
int *dev_a, *dev_b, *dev_c; // device копии of a, b, c
int size = N * sizeof(int);
//выделяем память на device для of a, b, c
cudaMalloc((void**)& dev_a, size);
cudaMalloc((void**)& dev_b, size);
cudaMalloc((void**)& dev_c, size);
a = (int*)malloc(size);
b = (int*)malloc(size);
c = (int*)malloc(size);
random_ints(a, N);
random_ints(b, N);
//копируем ввод на device
cudaMemcpy(dev_a, a, size, cudaMemcpyHostToDevice);
cudaMemcpy(dev_b, b, size, cudaMemcpyHostToDevice);
//запускаем на выполнение add() kernel с блоками и нитями
add< < < N/THREADS_PER_BLOCK, THREADS_PER_BLOCK > > > (dev_a, dev_b, dev_c);
// копируем результат работы device на host (копия c)
cudaMemcpy(c, dev_c, size, cudaMemcpyDeviceToHost);
free(a); free(b); free(c);
cudaFree(dev_a);
cudaFree(dev_b);
cudaFree(dev_c);
return 0;
}
CUDAfy.NET
CUDAfy.NET — набор библиотек и инструментов, которые позволяют программировать графические процессоры Nvidia на CUDA и устройства, поддерживающие OpenCL.
Пример программы на C# с использованием CUDAfy.NET
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using Cudafy;
using Cudafy.Host;
using Cudafy.Translator;
namespace cudafy_hello
{
class Program
{
private const int count = 1000000;
static void Main(string[] args)
{
int[] a = new int[count];
int[] b = new int[count];
int[] c = new int[count];
Random random = new Random();
for (int i = 0; i < count; i++)
{
a[i] = random.Next();
b[i] = random.Next();
}
CudafyModes.Target = eGPUType.Cuda;
CudafyModes.DeviceId = 0;
CudafyTranslator.Language = eLanguage.Cuda;
GPGPU gpu = CudafyHost.GetDevice(CudafyModes.Target, CudafyModes.DeviceId);
eArchitecture architecture = gpu.GetArchitecture();
CudafyModule cudafyModule = CudafyTranslator.Cudafy(architecture);
gpu.LoadModule(cudafyModule);
int gridSize = 128;
int blockSize = 1;
int[] dev_a = gpu.Allocate< int> (a);
int[] dev_b = gpu.Allocate< int> (b);
int[] dev_c = gpu.Allocate< int> (c);
gpu.CopyToDevice(a, dev_a);
gpu.CopyToDevice(b, dev_b);
gpu.Launch(gridSize, blockSize, " GpuAdd", dev_a, dev_b, dev_c);
gpu.CopyFromDevice(dev_c, c);
bool success = true;
for (int i = 0; i < count; i++)
{
if (a[i] + b[i]! = c[i])
{
Console.WriteLine(" {0}+{1}! ={2}", a[i], b[i], c[i]);
break;
}
}
if (success)
{
Console.WriteLine(" It works! ");
}
Console.ReadKey();
}
[Cudafy]
public static void GpuAdd(GThread thread, int[] a, int[] b, int[] c)
{
int tId = thread.blockIdx.x;
while (tId< count)
{
c[tId] = a[tId] + b[tId];
tId += thread.gridDim.x;
}
}
}
}
Задание на лабораторную работу
1. Подготовьтесь к выполнению лабораторной работы как показано на видео.
2. Напишите программу перемножения матриц для CPU и GPU. Для реализации программы на GPU обратитесь к видео, проекту из видео и документации по CUDAfy.NET. Если вы забыли, как перемножать матрицы, то обратитесь к документу Материалы/Перемножение матриц/ Умножение матриц — Википедия.htm.
3. Сравните производительность работы программы на CPU и на GPU. Занесите результаты в таблицу вида:
| № теста | Размерность матрицы 1 | Размерность матрицы 2 | Время работы на CPU, мс | Время работы на GPU, мс |
| 128x128 | 128x64 | 3.122 | 0.012 |
Нужно провести как минимум 5 тестов с различными матрицами, построить график и объяснить полученные результаты.
4. Узнайте характеристики вашей видеокарты с помощью CUDAfy.NET. Как получить доступ к этим данным сказано в разделе 3.4 Enum GPU в файле CUDAfy_User_Manual_1_22.pdf
Контрольные вопросы
1. Что такое GPGPU?
2. Какие задачи решаются с применением GPGPU?
3. В чем преимущество применения GPGPU по сравнению CPU.
4. Почему GPGPU быстрее CPU.
5. Как осуществляется загрузка данных в GPGPU?
6. Какой код выполняется в GPGPU?
7. Как происходит доступ к GPGPU из кода C#?
8. Как размерность данных влияет на производительность?
Литература
1. CUDA // Википедия. [2015—2015]. Дата обновления: 23.03.2015. URL: https://ru.wikipedia.org/? oldid=69499033.
2. GPGPU // Википедия. [2014—2015]. Дата обновления: 20.05.2014. URL: https://ru.wikipedia.org/? oldid=63180791.
3. CUDAfy.NET User Guide // Hybrid DSP URL: https://www.hybriddsp.com/cudafy/CUDAfy_User_Manual_1_22.pdf
Заключение
При проведении лабораторных занятий было выявлено, что в группе два человека, имеют более высокий уровень знаний по сравнению с остальными. Эти студенты проявляли более высокий интерес к предложенному материалу и задавали вопросы по теме. Также было несколько студентов, проявляющие низкий интерес к обучению в целом. Основной состав группы был дисциплинирован, студенты работали ровно настолько, сколько от них требовали. Также можно отметить, что при обширном разъяснении теоретического материала, разъяснении целей работы и ее связи с возможной практической деятельностью студенты проявляли большую заинтересованность в получении знаний.
|
|