Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Регрессионные модели прогнозирования
|
|
РАЗДЕЛ 2. МОДЕЛИ И МЕТОДЫ ЭКОНОМИЧЕСКОГО ПРОГНОЗИРОВАНИЯ
Регрессионные модели прогнозирования
В экономических исследованиях часто изучаются связи между случайными и неслучайными величинами. Такие связи называют регрессионными, а метод их изучения - регрессионным анализом.
Математически задача формулируется следующим образом. Требуется найти аналитическое выражение зависимости экономического явления (например, производительности труда) от определяющих его факторов; т.е. ищется функция y=f(x1, x2,..., xn), отражающая зависимость, по которой можно найти приближенное значение зависимого показателя y. В качестве функции в регрессионном анализе принимается случайная переменная, а аргументами являются неслучайные переменные.
Примерами возможного применения регрессионного анализа в экономике являются исследование влияния на производительность труда и себестоимость таких факторов, как величина основных производственных фондов, заработная плата и др.; влияние безработицы на изменение заработной платы на рынках труда (кривые Филипса); зависимость структуры расходов от уровня доходов (кривые Энгеля); функции потребления и спроса и многие другие.
При выборе вида регрессионной зависимости руководствуются следующим: он должен согласовываться с профессионально-логическими соображениями относительно природы и характера исследуемых связей; по возможности используют простые зависимости, не требующие сложных расчетов, легко экономически интерпретируемые и практически применимые.
Практика регрессионного анализа говорит о том, что уравнение линейной регрессии часто достаточно хорошо выражает зависимость между показателями даже тогда, когда на самом деле они оказываются более сложными. Это объясняется тем, что в пределах исследуемых величин самые сложные зависимости могут носить приближенно линейный характер.
В общей форме прямолинейное уравнение регрессии имеет вид
y=a0+b1*x1+b2*x2+........+bm*xm, (5.1)
где y - результативный признак, исследуемая переменная;
xi - обозначение фактора (независимая переменная);
m - общее число факторов;
a0 - постоянный (свободный) член уравнения;
bi - коэффициент регрессии при факторе.
Увеличение результативного признака y при изменении фактора xi на единицу равно коэффициенту регрессии bi (с положительным знаком); уменьшение - (с отрицательным знаком).
Уравнение регрессии можно изобразить графически (рис. 5.1).
 у
у
 |


 Отрезок «b» показывает
Отрезок «b» показывает
b приращение «y» при



 увеличении значения «х»
увеличении значения «х»
на единицу.
 |
а0
х
 1 2 3
1 2 3
Рисунок 5.1 - График простой парной линейной регрессии y=a0+bx
Очевидная экономическая интерпретация результатов линейной регрессии одна из основных причин ее применения в исследовании и прогнозировании экономических процессов. В зависимости от числа факторов, влияющих на результативный показатель, различают парную и множественную регрессии.
Кратко изложим основные положения по разработке и использованию в прогнозировании множественных линейных регрессионных моделей (парная регрессия может быть рассмотрена как частный случай множественной). Экономические явления определяются, как правило, большим числом совокупно действующих факторов. В связи с этим часто возникает задача исследования зависимости одной переменной Y от нескольких объясняющих переменных X1, Х2, …Хn. Эта задача решается с помощью множественного регрессионного анализа. Построение уравнения множественной регрессии начинается с решения вопроса о спецификации модели, включающего отбор факторов и выбор вида уравнения регрессии. Факторы, включаемые во множественную регрессию, должны отвечать следующим требованиям: они должны быть количественно измеримы (качественным факторам необходимо придать количественную определенность); между факторами не должно быть высокой корреляционной, а тем более функциональной зависимости, т.е. наличия мультиколлинеарности.
Включение в модель мультиколлинеарных факторов может привести к следующим последствиям: затрудняется интерпретация параметров множественной регрессии как характеристик действия факторов в «чистом виде», поскольку факторы связаны между собой; параметры линейной регрессии теряют экономический смысл; оценки параметров ненадежны, имеют большие стандартные ошибки и меняются с изменением объема наблюдений.
Пусть 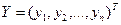 - матрица – столбец значений зависимой переменной размера n (значок «Т» означает транспонирование);
- матрица – столбец значений зависимой переменной размера n (значок «Т» означает транспонирование);
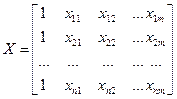 - матрица объясняющих переменных;
- матрица объясняющих переменных;
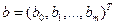 - матрица – столбец (вектор) параметров размера m+1;
- матрица – столбец (вектор) параметров размера m+1;
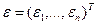 - матрица – столбец (вектор) остатков размера n.
- матрица – столбец (вектор) остатков размера n.
Тогда в матричной форме модель множественной линейной регрессии запишется следующим образом:
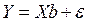 (5.2)
(5.2)
При оценке параметров уравнения регрессии (вектора b) применяется метод наименьших квадратов (МНК). При этом делаются определенные предпосылки.
1. В модели (5.2) ε – случайный вектор, Х - неслучайная (детерминированная) матрица.
2. Математическое ожидание величины остатков равно нулю. М(ε) = 0n.
3. Дисперсия остатков ε i постоянна для любого i (условие гомоскедастичности), остатки ε i и ε j при i≠ j не коррелированны: 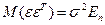 .
.
4. ε – нормально распределенный случайный вектор.
5. r(X)=m+1< n. Столбцы матрицы Х должны быть линейно независимыми (ранг матрицы Х максимальный, а число наблюдений n превосходит ранг матрицы).
Модель (5.2), в которой зависимая переменная, остатки и объясняющие переменные удовлетворяют предпосылкам 1-5 (предпосылки перечислены выше) называется классической нормальной линейной моделью множественной регрессии (КНЛММР). Если не выполняется только предпосылка 4, то модель называется классической линейной моделью множественной регрессии (КЛММР).
Согласно методу наименьших квадратов неизвестные параметры выбираются таким образом, чтобы сумма квадратов отклонений фактических значений от значений, найденных по уравнению регрессии, была минимальной:
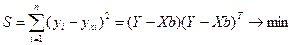 (5.3)
(5.3)
Решением этой задачи является вектор 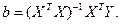
Оценка качества регрессионного уравнения осуществляется по совокупности критериев, проверяющих адекватность модели фактическим условиям и статистической достоверности регрессии.
Одной из наиболее эффективных оценок адекватности модели является коэффициент детерминации R2, определяемый по формуле (5.4):
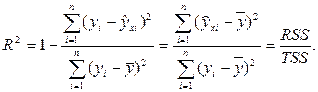 , (5.4)
, (5.4)
где yi – фактическое значение результирующего признака;
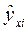 - значение результирующего признака, рассчитанное по полученной модели регрессии;
- значение результирующего признака, рассчитанное по полученной модели регрессии;
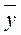 - среднее значение признака;
- среднее значение признака;
RSS – объясненная сумма квадратов;
TSS – общая сумма квадратов.
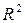 характеризует долю вариации зависимой переменной, обусловленной регрессией или изменчивостью объясняющих переменных. Чем ближе R2 к единице, тем лучше построенная регрессионная модель описывает зависимость между объясняющими и зависимой переменной. В случае
характеризует долю вариации зависимой переменной, обусловленной регрессией или изменчивостью объясняющих переменных. Чем ближе R2 к единице, тем лучше построенная регрессионная модель описывает зависимость между объясняющими и зависимой переменной. В случае  изучаемую связь можно трактовать как функциональную (а не статистическую), что требует дополнительных качественных и количественных сведений и изменений в процессе исследования.
изучаемую связь можно трактовать как функциональную (а не статистическую), что требует дополнительных качественных и количественных сведений и изменений в процессе исследования.
Следует иметь в виду, что при включении в модель новой объясняющей переменной, коэффициент детерминации увеличивается, хотя это и не обязательно означает улучшение качества регрессионной модели. В этой связи лучше использовать скорректированный (поправленный) коэффициент детерминации R2, пересчитываемый по формуле:
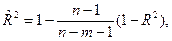 (5.5)
(5.5)
где n – число наблюдений,
m – число параметров при переменных х.
Таким образом, скорректированный коэффициент детерминации может уменьшаться при добавлении в модель новой объясняющей переменной, не оказывающей существенного влияния на результативный признак.
Средняя относительная ошибка аппроксимации рассчитывается по формуле:
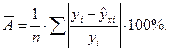 (5.6)
(5.6)
Большинство авторов рекомендуют считать модель регрессии адекватной, если средняя относительная ошибка аппроксимации не превышает 12%.
Проверку значимости вида регрессионной зависимости можно осуществлять с применением дисперсионного анализа. Основной идеей этого анализа является разложение общей суммы квадратов отклонений результативной переменной y от среднего значения y на «объясненную» и «остаточную»:
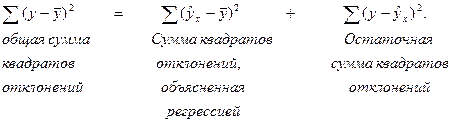 (5.7)
(5.7)
Для приведения дисперсий к сопоставимому виду, определяют дисперсии на одну степень свободы. Результаты вычислений заносят в специальную таблицу дисперсионного анализа (табл. 5.1). В данной таблице n – число наблюдений, m – число параметров при переменных х. Сравнивая полученные оценки объясненной и остаточной дисперсии на одну степень свободы, определяют значение F- критерия Фишера, используемого для оценки значимости уравнения регрессии:
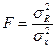 . (5.8)
. (5.8)
С помощью F – критерия проверяется нулевая гипотеза о равенстве дисперсий H0: σ R2=σ x2. Если нулевая гипотеза справедлива, то объясненная и остаточная дисперсии не отличаются друг от друга.
Таблица 5.1 - Результаты дисперсионного анализа
| Компоненты дисперсии | Сумма квадратов | Число степеней свободы | Оценка дисперсии на одну степень свободы |
| Общая | 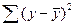
| n-1 | 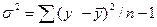
|
| Объясненная | 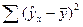
| n | 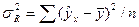
|
| Остаточная | 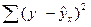
| n-m-1 | 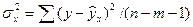
|
Для того, чтобы уравнение регрессии было значимо в целом (гипотеза Н0 была опровергнута) необходимо, чтобы объясненная дисперсия превышала остаточную в несколько раз. Критическое значение F – критерия определяется по таблице Фишера – Снедекора (приложение 1). Fтабл – максимально возможное значение критерия под влиянием случайных факторов при степенях свободы k1 = m, k2 = n–m –1 (для линейной регрессии m = 1) и уровне значимости α. Уровень значимости α – вероятность отвергнуть правильную гипотезу при условии, что она верна. Обычно величина α принимается равной 0, 05 или 0, 01. Расчетное значение сравнивается с табличным: если оно превышает табличное (Fрасч> Fтабл), то гипотеза Н0 отвергается, и уравнение регрессии признается значимым. Если Fрасч< Fтабл, то уравнение регрессии считается статистически незначимым. Нулевая гипотеза Н0 не может быть отклонена.
Расчетное значение F- критерия связано с коэффициентом детерминации R2 следующим соотношением:
 (5.9)
(5.9)
где m –число параметров при переменных х;
n – число наблюдений.
Для оценки статистической значимости коэффициентов регрессии и коэффициента корреляции r (r= 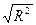 ) применяется t- критерий Стьюдента.
) применяется t- критерий Стьюдента.
Оценка значимости коэффициентов регрессии сводится к проверке гипотезы о равенстве нулю коэффициента регрессии при соответствующем факторном признаке, т.е. гипотезы:
Н0: bi=0 (5.10)
Проверка нулевой статистической гипотезы проводится с помощью t – критерия Стьюдента:
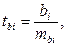 (5.11)
(5.11)
где bi – коэффициент регрессии при хi,
mbi – средняя квадратическая ошибка коэффициента регрессии bi.
Средняя квадратическая ошибка коэффициента регрессии может быть определена по формуле:
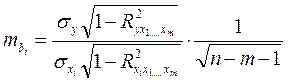 (5.12)
(5.12)
где 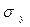 - среднее квадратическое отклонение для признака у;
- среднее квадратическое отклонение для признака у;
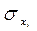 - среднее квадратическое отклонение для признака хi;
- среднее квадратическое отклонение для признака хi;
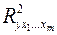 - коэффициент детерминации для уравнения множественной регрессии;
- коэффициент детерминации для уравнения множественной регрессии;
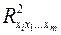 - коэффициент детерминации для зависимости фактора хi со всеми другими факторами уравнения множественной регрессии;
- коэффициент детерминации для зависимости фактора хi со всеми другими факторами уравнения множественной регрессии;
n-m- 1 - число степеней свободы для остаточной суммы квадратов отклонений.
Использование формулы (5.12) для расчета средней квадратической ошибки коэффициента регрессии предполагает расчет по матрице межфакторной корреляции соответствующих коэффициентов детерминации. Поэтому иногда рекомендуется использовать для определения средней квадратической ошибки коэффициента регрессии mbiчастные критерии Фишера.
Расчетное значение критерия Стьюдента сравнивается с табличным tтабл при заданном уровне значимости 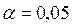 (для экономических процессов и явлений) и числе степеней свободы, равном n-2. Если расчетное значение превышает табличное, то гипотезу о несущественности коэффициента регрессии bi можно отклонить.
(для экономических процессов и явлений) и числе степеней свободы, равном n-2. Если расчетное значение превышает табличное, то гипотезу о несущественности коэффициента регрессии bi можно отклонить.
В линейной модели множественной регрессии 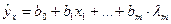 коэффициенты регрессии bi характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
коэффициенты регрессии bi характеризуют среднее изменение результата с изменением соответствующего фактора на единицу при неизменном значении других факторов, закрепленных на среднем уровне.
Значимость коэффициента корреляции r проверяется также на основе t -критерия Стьюдента (приложение 2). При этом выдвигается и проверяется гипотеза о равенстве коэффициента корреляции нулю (Н0: r = 0). При проверке этой гипотезы используется t- статистика:
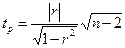 . (5.13)
. (5.13)
При выполнении Н0 t -статистика имеет распределение Стьюдента с входными параметрами: α =0, 05; k=n-2. Если расчетное значение больше табличного, то гипотеза Н0 отвергается.
На практике часто бывает необходимо сравнить влияние на зависимую переменную различных объясняющих переменных, когда последние выражаются разными единицами измерения. В этом случае используют стандартизованные коэффициенты регрессии β i и коэффициенты эластичности Эi (i=1, 2, …, m).
Уравнение регрессии в стандартизованной форме обычно представляют в виде (5.14):
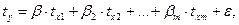 (5.14)
(5.14)
где 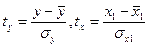 - стандартизованные переменные.
- стандартизованные переменные.
Заменив значения «у» на ty, а значения «х» на 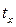 получаем нормированные или стандартизованные переменные. В результате такого нормирования средние значения всех стандартизованных переменных равны нулю, а дисперсии равны единице, т.е.
получаем нормированные или стандартизованные переменные. В результате такого нормирования средние значения всех стандартизованных переменных равны нулю, а дисперсии равны единице, т.е. 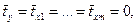
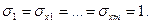
Коэффициенты обычной («чистой») регрессии связаны со стандартизованными коэффициентами следующим соотношением:
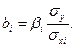 (5.15)
(5.15)
Стандартизованные коэффициенты могут принимать значения от -1 до +1 и показывают, на сколько стандартных отклонений (сигм) изменится в среднем результат, если соответствующий фактор хi изменится на одно стандартное отклонение (одну сигму) при неизменном среднем уровне других факторов. Данные коэффициенты сохраняют свою величину при изменении масштаба шкалы. Сравнивая стандартизованные коэффициенты друг с другом, можно ранжировать факторы по силе их воздействия на результат.
В экономических исследованиях широкое применение находит такой показатель, как коэффициент эластичности, вычисляемый по формуле (5.16):
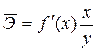 , (5.16)
, (5.16)
где 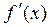 - производная, характеризующая соотношение приростов результата и фактора для соответствующей формы связи.
- производная, характеризующая соотношение приростов результата и фактора для соответствующей формы связи.
Средние коэффициенты эластичности для линейной регрессии вычисляются по формуле (5.17):
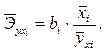 (5.17)
(5.17)
Коэффициент эластичности показывает, на сколько процентов (от средней) изменится в среднем Y при увеличении только фактора Xi на 1%.
При эконометрическом моделировании реальных экономических процессов предпосылки МНК нередко оказываются нарушенными: дисперсии остатков модели не одинаковы (гетероскедастичность остатков), или наблюдается корреляция между остатками в разные моменты времени (автокоррелированные остатки).
Проверить модель на гетероскедастичность можно с помощью следующих тестов: ранговой корреляции Спирмена; Голдфельда-Квандта; Уайта; Глейзера. В случае выявления гетероскедастичности остатков для оценки параметров регрессии используется обобщенный метод наименьших квадратов (ОМНК). Технология ОМНК подробно описана во многих учебниках по эконометрике.
Влияние результатов предыдущих наблюдений на результаты последующих приводит к тому, что случайные величины (ошибки) ε i в регрессионной модели становятся зависимыми. Такие модели называются моделями с наличием автокорреляции. Как правило, если автокорреляция присутствует, то наибольшее влияние на последующее наблюдение оказывает результат предыдущего наблюдения. Наличие автокорреляции между соседними уровнями ряда можно определить с помощью теста Дарбина-Уотсона. Расчетное значение критерия Дарбина-Уотсона определяется по следующей формуле:
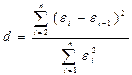 , (5.18)
, (5.18)
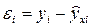 . (5.19)
. (5.19)
Т.е. величина 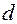 есть отношение суммы квадратов разностей последовательных значений остатков к остаточной сумме квадратов по модели регрессии.
есть отношение суммы квадратов разностей последовательных значений остатков к остаточной сумме квадратов по модели регрессии.
Значения критерия находятся в интервале от 0 до 4. По таблицам критических точек распределения Дарбина-Уотсона для заданного уровня значимости 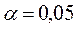 , числа наблюдений (n) и количества объясняющих переменных (m) находят пороговые значения dн (нижняя граница) и dв (верхняя граница) (приложение 3).
, числа наблюдений (n) и количества объясняющих переменных (m) находят пороговые значения dн (нижняя граница) и dв (верхняя граница) (приложение 3).
Если расчетное значение (табл. 5.2):
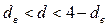 , то гипотеза об отсутствии автокорреляции не отвергается (принимается);
, то гипотеза об отсутствии автокорреляции не отвергается (принимается);
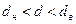 или
или 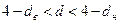 , то вопрос об отвержении или принятии гипотезы остается открытым (расчетное значение попадает в зону неопределенности);
, то вопрос об отвержении или принятии гипотезы остается открытым (расчетное значение попадает в зону неопределенности);
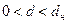 , то принимается альтернативная гипотеза о наличии положительной автокорреляции;
, то принимается альтернативная гипотеза о наличии положительной автокорреляции;
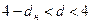 , то принимается альтернативная гипотеза о наличии отрицательной автокорреляции.
, то принимается альтернативная гипотеза о наличии отрицательной автокорреляции.
Таблица 5.2 - Промежутки внутри интервала [0 - 4]
|
|
| 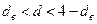
|
|
|
| принимается альтернативная гипотеза о наличии положительнойавтокорреляции | вопрос об отвержении или принятии гипотезы остается открытым (расчетное значение попадает в зону неопределенности) | гипотеза об отсутствии автокорреляции не отвергается (принимается) | вопрос об отвержении или принятии гипотезы остается открытым (расчетное значение попадает в зону неопределенности) | принимается альтернативная гипотеза о наличии отрицательной автокорреляции |
Недостаток теста Дарбина-Уотсона заключается прежде всего в том, что он содержит зоны неопределенности. Во-вторых, он позволяет выявить наличие автокорреляции только между соседними уровнями, тогда как автокорреляция может существовать и между более отдаленными наблюдениями. Поэтому наряду с тестом Дарбина-Уотсона для проверки наличия автокорреляции используются тест серий (Бреуша-Годфри), Q -тест Льюинга-Бокса и другие. Наиболее распространенным приемом устранения автокорреляции во временных рядах является построение авторегрессионных моделей.
|
|