Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Методы анализа КС-языков. Грамматики предшествования
|
|
В А-грамматике синтаксический анализ цепочки прост: начиная с первого символа цепочки, переходя из состояния в состояние, делается вывод о возможности получения очередного символа цепочки либо о переходе автомата в ошибочное состояние. Для вывода цепочки aaaa в грамматике S®aS|a необходимо выполнить следующую последовательность действий: aS®aaS®aaaS®aaaa, предварительно приведя грамматику к детерминированной форме. В КС-грамматиках используется дерево вывода и грамматики также могут быть неодназначными.
Большинство языков программирования можно описать с помощью контекстно-свободных грамматик. Но построить алгоритм анализа по таким грамматикам в общем случае не так просто и эти алгоритмы, как правило, неэффективны. Один из путей анализа цепочек КС-языка следует из теоремы о разрешимости таких языков. Напомним, что любой КС-язык можно описать с помощью КС-грамматики в удлиняющей форме, по которой любая цепочка заданного языка длины n выводится не более чем за n шагов. Для того чтобы определить принадлежность некоторой цепочки с длиной n данному языку, необходимо по заданной грамматике вывести все бесповторные цепочки, которые выводятся не более чем за n шагов, и сравнить их с исходной цепочкой. Если мы обнаружим совпадение, то исходная цепочка принадлежит языку, в противном случае – не принадлежит. Совершенно очевидно, что подобный потенциально осуществимый алгоритм не имеет практического смысла. Во-первых, необходимо строить вывод миллиардов цепочек, во-вторых, такой алгоритм может ответить только на вопрос принадлежности языку. Локализовать и идентифицировать ошибку, а тем более осуществить трансляцию в процессе синтаксического анализа текста он не способен.
Методы построения анализаторов по КС-грамматике делятся на две группы: нисходящие (анализ сверху вниз) и восходящие (анализ снизу вверх). Эти термины соответствуют способу построения синтаксических деревьев вывода.
Нисходящие методы выполняют анализ с начального выделенного нетерминала, или иначе от корня дерева вывода вниз, к концевым вершинам, пытаясь построить дерево вывода цепочки. Если дерево удалось построить, то цепочка принадлежит языку, в противном случае – не принадлежит. В общем случае все методы основаны на переборе всех возможных вариантов вывода, поэтому неэффективны, хотя и существуют алгоритмы нисходящего разбора с возвратами, ограничивающих число переборов вариантов при выводе цепочек.
Алгоритмы восходящего разбора начинаются с листьев дерева вывода (с входных символов, как и в автоматных грамматиках) и пытаются построить дерево разбора, восходя от листьев к корню. Среди этих алгоритмов наиболее эффективными являются алгоритмы, использующие при свертке отношения предшествования.
В цепочке КС-языка сложно выделить основу для свёртки. Впервые в 1966 г. Вебером был предложен метод свёртки, используя отношение предшествования. Согласно этому методу, между любыми символами, которые могут встретится на любом шаге вывода цепочки, определяется одно из трёх отношений предшествования:
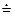 – отношение предшествования равенства,
– отношение предшествования равенства,
отношение предшествования меньше (раньше): < ×
и отношение предшествования больше (позже): × >
Между любыми двумя символами S1 и S2 устанавливается отношение , если они находятся рядом в одном правиле вывода.
S1< ·S2, если S1 уже выведено, а S2 – будет стоять рядом с S1 при применении некоторого правила на следующем шаге вывода.
S1·> S2 (S1 “позже” S2), если S2 выведено, а S1 будет стоять рядом с S2 на следующем шаге вывода.
Основа для свёртки – множество символов, находящихся между отношениями предшествования < · и ·>.
Наиболее эффективные методы свертки применимы для узкого класса КС-грамматик, называемых грамматиками предшествования, для которых выполняются следующие ограничения.
Грамматики предшествования – узкий класс КС-грамматик, в которых:
1) между любыми символами существует не более одного отношения предшествования;
2) не существует правил с одинаковыми правыми частями.
В классе грамматик предшествования существует несколько видов грамматик, различающихся правилами определения отношений предшествования между символами. Существуют грамматики простого и расширенного предшествования, в зависимости от того, за сколько шагов при выводе цепочек определяется отношение предшествования. Кроме этого отношения предшествования могут устанавливаться между различными символами. Далее будут рассмотрены грамматики простого предшествования по Вирту (отношения предшествования устанавливаются как между терминальными, так и между нетерминальными символами) и грамматики операторного предшествования Флойда (отношения предшествования устанавливаются только между терминальными символами).
|
|