Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Архитектура многопроцессорных ВС
|
|
Один из первых в мире компьютеров EDSAC (1949 г.) выполнял около 100 арифметических операций в секунду. Производительность самых мощных современных компьютеров составляет несколько десятков триллионов (1012) операций в секунду. Чем же объясняется такой колоссальный рост производительности?
Несомненно, одной из причин является совершенствование элементной базы. Смена электронных ламп транзисторами, появление интегральных схем, разработка кремниевых чипов – каждое из этих событий производило революцию в компьютерной технике. Современные технологии создания чипов позволяют работать с элементами размеров порядка десятых долей микрона (10-6 м). Регулярное уменьшение размеров чипов обеспечивает эволюционный рост тактовой частоты работы процессоров. Так, EDSAC имел время такта 2 микросекунды (10-6 сек), а современный компьютер Hewlett- Packard V2600 выполняет один такт за 1.8 наносекунды (10-9 сек). То есть HP V2600 выполняет одну процессорную команду в 1000 раз быстрее. В то же время его производительность составляет 77 миллиардов операций в секунду, и это в семьсот миллионов раз больше, чем у EDSAC. Такой рост производительности не может объясняться только лишь изменением элементной базы.
Вторая по счету, но первая по значению причина заключается в использовании новых решений в архитектуре компьютера.
В вычислительной науке используются три термина, связанные с устройством электронно-вычислительной машины. Архитектура компьютера – это описание компонент компьютера и их взаимодействия. Организация компьютера – это описание конкретной реализации архитектуры, ее воплощения “в железе”. Компьютеры CRAY, например, имеют сходную архитектуру. С точки зрения программиста, у них одинаковое число внутренних регистров, используемых для временного хранения данных, одинаковый набор машинных команд, одинаковый формат представления данных. Организация же компьютеров Cray разных моделей может существенно различаться: у них может быть разное число процессоров, разный размер оперативной памяти, разное быстродействие и т.д. Третий термин – это схема компьютера, детальное описание его электронных компонент, их соединений, устройств питания, охлаждения и других. Программисту довольно часто требуется знание архитектуры компьютера, реже его организации и никогда – схемы компьютера.
Революцию в компьютерных архитектурах произвел принцип параллельной обработки данных, воплощающий идею одновременного (параллельного) выполнения нескольких действий. Параллельная обработка данных имеет две разновидности: конвейерность и собственно параллельность.
- Параллельная обработка. Если некое устройство выполняет одну операцию за единицу времени, то тысячу операций оно выполнит за тысячу единиц. Если предположить, что есть пять таких же независимых устройств, способных работать одновременно, то ту же тысячу операций система из пяти устройств может выполнить уже не за тысячу, а за двести единиц времени. Аналогично система из N устройств ту же работу выполнит за 1000/N единиц времени. Однако это идеальное ускорение удается получить лишь в очень специальных ситуациях, когда подзадачи полностью независимы (например, задачи перебора, взламывание паролей). Чтобы стало понятней, рассмотрим пример из жизни. Если один человек вскапывает один квадратный метр земли за две минуты, то это не означает, что двенадцать человек вскопают его за десять секунд: они будут мешать друг другу и работа только замедлится. Что же касается вычислений, то есть такие алгоритмы, которые при распараллеливании не только не дают ускорения, но даже замедляются.
- Конвейерная обработка. Что необходимо для сложения двух вещественных чисел, представленных в форме с плавающей запятой? Целое множество мелких операций таких, как сравнение порядков, выравнивание порядков, сложение мантисс, нормализация и т.п. Процессоры первых компьютеров выполняли все эти “микрооперации” для каждой пары аргументов последовательно одна за другой до тех пор, пока не доходили до окончательного результата, и лишь после этого переходили к обработке следующей пары слагаемых.
Идея конвейерной обработки заключается в выделении отдельных этапов выполнения общей операции, причем каждый этап, выполнив свою работу, передавал бы результат следующему, одновременно принимая новую порцию входных данных. Получаем очевидный выигрыш в скорости обработки за счет совмещения прежде разнесенных во времени операций.
По-видимому, самой ранней и наиболее известной является классификация архитектур вычислительных систем, предложенная в 1966 году М. Флинном [? ]. Классификация базируется на понятии потока, под которым понимается последовательность элементов, команд или данных, обрабатываемая процессором. На основе числа потоков команд и потоков данных Флинн выделяет четыре класса архитектур: SISD, MISD, SIMD, MIMD.
SISD (single instruction stream / single data stream) – одиночный поток команд и одиночный поток данных. К этому классу относятся, прежде всего, классические последовательные машины, или иначе, машины Фон-Неймановского типа.
В таких машинах есть только один поток команд, все команды обрабатываются последовательно друг за другом, и каждая команда инициирует одну операцию с одним потоком данных.
SIMD (single instruction stream / multiple data stream) – одиночный поток команд и множественный поток данных. В архитектурах подобного рода сохраняется один поток команд, включающий, в отличие от предыдущего класса, векторные команды. Это позволяет выполнять одну арифметическую операцию сразу над многими данными – элементами вектора.
Способ выполнения векторных операций не оговаривается, поэтому обработка элементов вектора может производиться либо процессорной матрицей, как в ILLIAC IV, либо с помощью конвейера, как, например, в машине CRAY-1.
MISD (multiple instruction stream / single data stream) – множественный поток команд и одиночный поток данных. Определение подразумевает наличие в архитектуре многих процессоров, обрабатывающих один и тот же поток данных. Однако ни Флинн, ни другие специалисты в области архитектуры компьютеров до сих пор не смогли представить убедительный пример реально существующей вычислительной системы, построенной на данном принципе.
Ряд исследователей относят конвейерные машины к данному классу, однако это не нашло окончательного признания в научном сообществе. Будем считать, что пока данный класс пуст.
MIMD (multiple instruction stream / multiple data stream) – множественный поток команд и множественный поток данных.
Этот класс предполагает, что в вычислительной системе есть несколько устройств обработки команд, объединенных в единый комплекс и работающих каждое со своим потоком команд и данных.
Предложенная схема классификации вплоть до настоящего времени является самой применяемой при начальной характеристике того или иного компьютера. Если говорится, что компьютер принадлежит классу SIMD или MIMD, то сразу становится понятным базовый принцип его работы, и в некоторых случаях этого бывает достаточно. Однако видны и явные недостатки. В частности, некоторые заслуживающие внимания архитектуры, например, dataflow и векторно-конвейерные машины, четко не вписываются в данную классификацию. Другой недостаток – это чрезмерная заполненность класса MIMD. Необходимо средство, более избирательно систематизирующее архитектуры, которые по Флинну попадают в один класс, но совершенно различны по числу процессоров, природе и топологии связи между ними, по способу организации памяти и, конечно же, по технологии программирования.
В настоящее время существуют различные методы классификации архитектур параллельных вычислительных систем. Одна из возможных классификаций состоит в разделении параллельных вычислительных систем по типу памяти.
Векторно-конвейерные компьютеры. Конвейерные функциональные устройства и набор векторных команд – это две особенности таких машин. В отличие от традиционного подхода, векторные команды оперируют целыми массивами независимых данных, что позволяет эффективно загружать доступные конвейеры, т.е. команда вида A=B+C может означать сложение двух массивов, а не двух чисел.
Массивно-параллельные компьютеры (MPP системы). Массивно-параллельные компьютеры с распределенной памятью. Идея построения компьютеров этого класса тривиальна: возьмем серийные микропроцессоры, снабдим каждый своей локальной памятью, соединим посредством некоторой коммуникационной среды – вот и все (рис. 1.2). Достоинств у такой архитектуры масса: если нужна высокая производительность, то можно добавить еще процессоров; если ограничены финансы или заранее известна требуемая вычислительная мощность, то легко подобрать оптимальную конфигурацию и т.п.
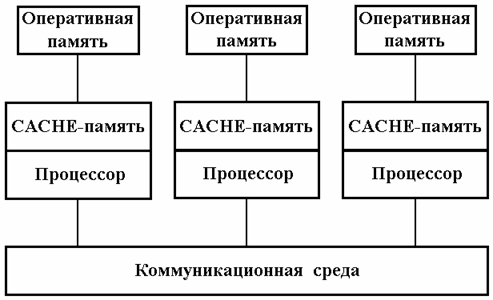
Рис. 1.2: Схема архитектуры MPP системы
Однако есть и решающий “минус”, сводящий многие “плюсы” на нет. Дело в том, что межпроцессорное взаимодействие в компьютерах этого класса идет намного медленнее, чем происходит локальная обработка данных самими процессорами. Именно поэтому написать эффективную программу для таких компьютеров очень сложно, а для некоторых алгоритмов – иногда просто невозможно.
К этому же классу можно отнести и сети компьютеров, которые все чаще рассматривают как дешевую альтернативу крайне дорогим суперкомпьютерам.
Компьютеры с общей памятью (SMP системы). Вся оперативная память таких компьютеров разделяется несколькими одинаковыми процессорами (рис. 1.3). Это снимает проблемы предыдущего класса, но добавляет новые – число процессоров, имеющих доступ к общей памяти, по чисто техническим причинам нельзя сделать большим.
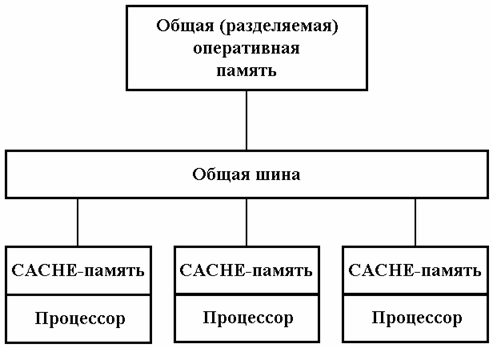
Рис. 1.3: Схема архитектуры SMP системы
Наличие общей памяти значительно упрощает взаимодействие процессоров между собой, однако за этой кажущейся простотой скрываются большие проблемы, присущие системам этого типа. Помимо хорошо известной проблемы конфликтов при обращении к общей шине памяти возникла и новая проблема, связанная с иерархической структурой организации памяти современных компьютеров. Дело в том, что самым узким местом в современных компьютерах является оперативная память, скорость работы которой значительно отстала от скорости работы процессора. В настоящее время эта скорость примерно в 20 раз ниже требуемой для 100% согласованности со скоростью работы процессора, и разрыв все время увеличивается. Для того, чтобы сгладить разрыв в скорости работы процессора и основной памяти, каждый процессор снабжается скоростной буферной памятью (кэш-памятью), работающей со скоростью процессора. В связи с этим в многопроцессорных системах, построенных на базе таких микропроцессоров, нарушается принцип равноправного доступа к любой точке памяти. Для его сохранения приходится организовывать аппаратную поддержку когерентности кэш-памяти, что приводит к большим накладным расходам и сильно ограничивает возможности по наращиванию производительности таких систем путем простого увеличения числа процессоров.
В чистом виде SMP системы состоят, как правило, не более чем из 32 процессоров, а для дальнейшего наращивания используется NUMA-технология, которая в настоящее время позволяет создавать системы, включающие до 256 процессоров с общей производительностью порядка 150 млрд. операций в секунду. Системы этого типа производятся многими компьютерными фирмами как многопроцессорные серверы с числом процессоров от 2 до 64 и прочно удерживают лидерство в классе малых суперкомпьютеров с производительностью до 60 млрд. операций в секунду.
Системы с неоднородным доступом к памяти (NUMA). NUMA-архитектуры представляют собой нечто среднее между SMP и MPP. В таких системах память физически распределена, но логически общедоступна. Система состоит из однородных базовых модулей (плат), состоящих из небольшого числа процессоров и блока памяти. Модули объединены с помощью высокоскоростного коммутатора. Поддерживается единое адресное пространство, аппаратно поддерживается доступ к удаленной памяти, т.е. к памяти других модулей. При этом доступ к локальной памяти в несколько раз быстрее, чем к удаленной.
Компьютерные кластеры. Кластерные технологии стали логическим продолжением развития идей, заложенных в архитектуре MPP систем. Если процессорный модуль в MPP системе представляет собой законченную вычислительную систему, то следующий шаг напрашивался сам собой: почему бы в качестве таких вычислительных узлов не использовать обычные серийно выпускаемые компьютеры. Развитие коммуникационных технологий, а именно появление высокоскоростного сетевого оборудования и специального программного обеспечения такого, как MPI, реализующего механизм передачи сообщений над стандартными сетевыми протоколами, сделало кластерные технологии общедоступными. Сегодня не составляет большого труда создать небольшую кластерную систему, объединив вычислительные мощности компьютеров отдельной лаборатории или учебного класса.
Привлекательной чертой кластерных технологий является то, что они позволяют для достижения необходимой производительности объединять в единые вычислительные системы компьютеры самого разного типа, начиная от персональных компьютеров и заканчивая мощными суперкомпьютерами. С одной стороны, эти технологии используются как дешевая альтернатива суперкомпьютерам.
Кластер – это связанный набор полноценных компьютеров, используемый в качестве единого ресурса. Существует два подхода при создании кластерных систем:
- объединение в единую систему полнофункциональных компьютеров, которые могут работать, в том числе, и как самостоятельные единицы, например, компьютеры учебного класса или рабочие станции лаборатории;
- целенаправленное создание мощного вычислительного ресурса, в котором роль вычислительных узлов играют промышленно выпускаемые компьютеры, и тогда нет необходимости снабжать такие компьютеры графическими картами, мониторами, дисковыми накопителями и другим периферийным оборудованием, что значительно удешевляет стоимость системы.
В последнем случае системные блоки компьютеров, как правило, компактно размещаются в специальных стойках, а для управления системой и для запуска задач выделяется один или несколько полнофункциональных компьютеров, которые называют хост-компьютерами. Преимущества кластерной системы перед набором независимых компьютеров очевидны. Во-первых, система пакетной обработки заданий позволяет послать задание на обработку кластеру в целом, а не какому-нибудь отдельному компьютеру, что позволяет обеспечить более равномерную загрузку компьютеров. Во-вторых, появляется возможность совместного использования вычислительных ресурсов нескольких компьютеров для решения одной задачи.
Для создания кластера используются компьютеры, которые могут представлять собой как простые однопроцессорные системы, так и обладать сложной архитектурой SMP и даже NUMA.
|
|