Главная страница Случайная страница
Разделы сайта
АвтомобилиАстрономияБиологияГеографияДом и садДругие языкиДругоеИнформатикаИсторияКультураЛитератураЛогикаМатематикаМедицинаМеталлургияМеханикаОбразованиеОхрана трудаПедагогикаПолитикаПравоПсихологияРелигияРиторикаСоциологияСпортСтроительствоТехнологияТуризмФизикаФилософияФинансыХимияЧерчениеЭкологияЭкономикаЭлектроника
Системы представления знаний.
|
|
В настоящее время существуют множественные формы моделей представления знаний. В общем случае, знания – метаданные, представленные определенным образом. Их различают:
1. Логический подход к представлению знаний;
2. Продукционный подход к представлению знаний;
3. Представление знаний в виде семантических сетей;
4. Фреймовый подход к представлению знаний;
Различные способы представлений определяют собственные методы обработки знаний. Вместе с тем, у всех способов представления, существует глобальное общее свойство, а именно, представление и обработка знаний является некоторой недетерминированной поисковой процедурой. При этом наблюдается некоторое несоответствие между формой представления знаний и методами их обработки. В основу всех методов обработки закладывается некоторая абстрактная система, которую обобщенно будем называть “машина вывода”. Вывод – это элементарное действие, выполняемое над определенным образом представленными знаниями. Машина вывода определенным образом реализует поисковую процедуру и получает:
1. решение задачи;
2. новые знания;
Под новым знанием, условились понимать, путь решения задачи или новый фрагмент знания, обладающего устойчивыми свойствами.
При продукционном подходе, знания представляются в виде совокупности продукций. Другое её название – продукционная база знаний, а S выступает в качестве обрабатываемых данных. Совокупность продукций превращается в вычислительную модель путем добавления к продукциям некоторой поисковой стратегии.
Формализуем понятие “машина вывода”. Машина вывода – некоторая абстрактная система, уточняющая состав и способ взаимодействия модулей обработки S при помощи системы продукций.
M={V, S, K, W} – состав машины вывода, где
V–модуль выбора активных продукций и активных данных;
S–модуль сопоставления выбранных продукций с данными, результатом сопоставления является множество применимых продукций;
K–модуль разрешения конфликтов. Результатом работы данного модуля, является выбор единственной приоритетной продукции. Единичный выбор при разрешении конфликта определяется альтернативным пониманием продукций, входящих в конфликтное множество;
W – модуль выполнения продукций, приводящий к модификации S;
Рассмотрим цикл работы машины вывода:
Цикл работы машины вывода состоит в последовательном выполнении определенных этапов:
1. выборки;
2. сопоставления;
3. разрешения конфликтов;
4. выполнения.

Определяющим этапом является этап разрешения конфликта.
Наиболее ответственным является этап разрешения конфликта. Так как определение приоритетной продукции в общем случае или неоднозначная или алгоритмически не решаемая задача.
С учетом того, что пространственный граф вывода не совпадает с временным графом вывода, этап разрешения конфликта должен некоторым образом учитывать коэффициенты ветвления.
Рассмотрим структуру модифицированной машины вывода, ориентированной на вычисление всех коэффициентов ветвления.
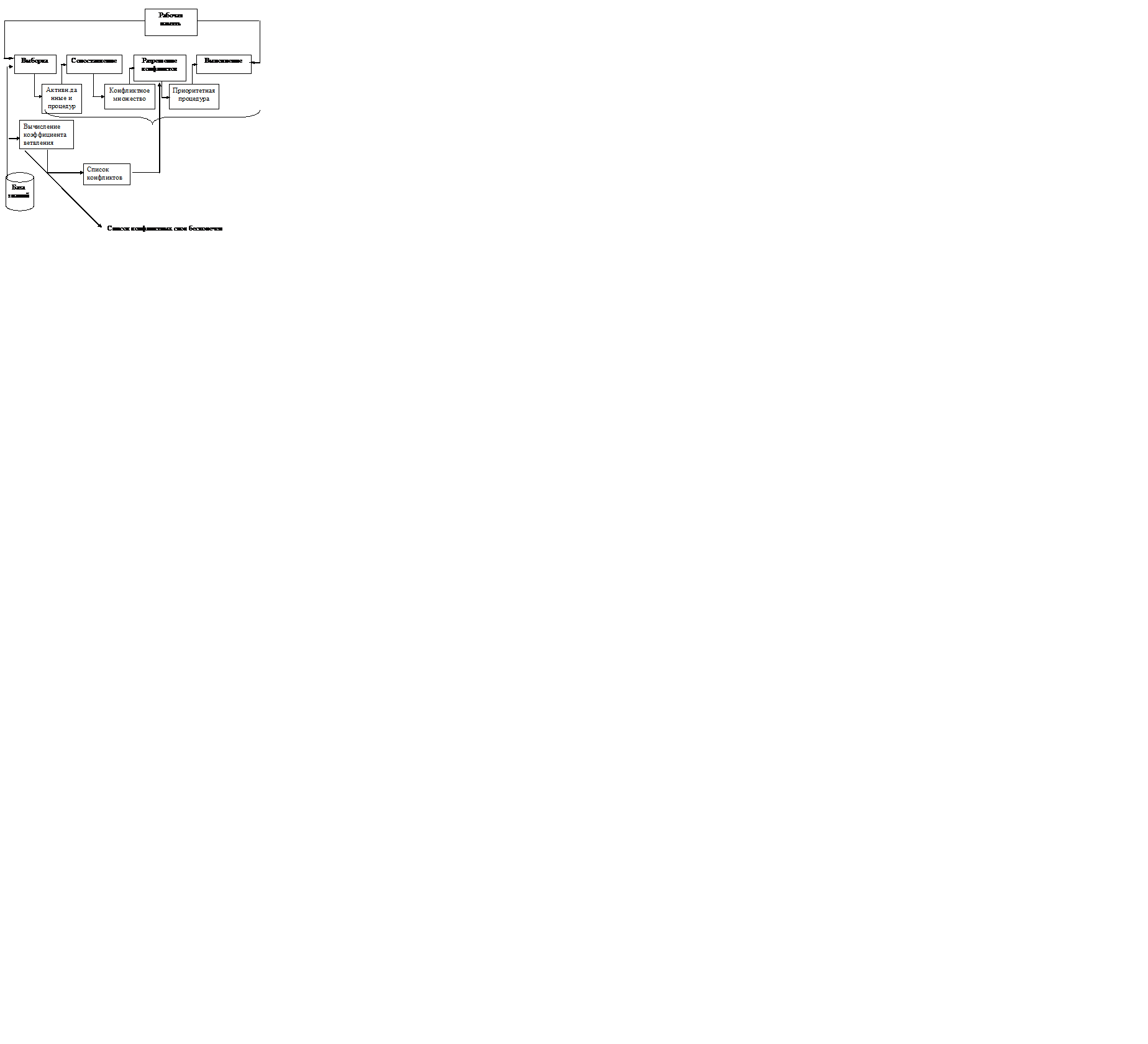
Вычисления коэффициента ветвления реализуется однократно. Он не зависит от входных данных и определяется только структурой продукции. Результатом данного этапа является список конфликтных слов, каждый из которых определяет мощность индивидуального конфликтного множества.
Этап вычисления коэффициентов ветвления может потерпеть неудачу. Это значит, что существует счет не бесконечное множество конфликтных слов и как следствие – невозможность определения максимального коэффициента ветвления.
Под конфликтным, понимается слово, получаемое объединением двух образцов с общей частью, покажем вариант построения конфликтных слов следующими четырьмя схемами:
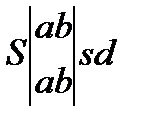
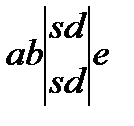
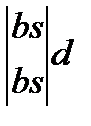
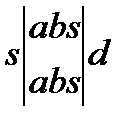
K1=Sabsd K2=absde K3=absd K4=Sabsd
Конфликтное слово формируется путем обнаружения общей части от двух слов (ядра) и дополнение ядра левой и правой частями от исходных слов. Данные 4-х ситуаций описывают все возможные ситуации выявления конфликтных слов. Таким образом, в основе построения конфликтных слов заложены алгоритмы обнаружения пересечения.
Аналитически, условие построения конфликтных слов записывается в виде следующей дизъюнкции:
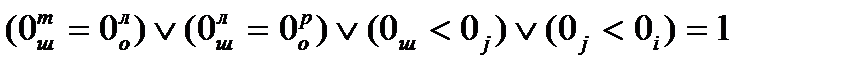
0i, 0j – образцы i-ой и j-ой продукции, индексы n, K, обозначают начало и окончание образцов. Конфликтные слова формируются последовательно попарно. При этом после парного сравнения образцов проверяется ситуация пересечения уже построенных конфликтных слов.
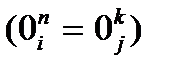 &
& 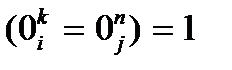
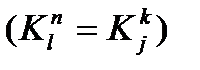 &
& 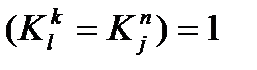
Для конфликтных слов K1, K2 полученная цепочка одинаковая, проявляется не парный, а тройной конфликт. Конфликтное множество формируется путем объединения множеств от K1, K2.
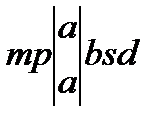 K3=mpabsd (1, 4)
K3=mpabsd (1, 4)
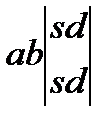 K4=absd (1, 5)
K4=absd (1, 5)
Цепочки 1 и 6 не имеют общего ядра и следовательно не формируют конфликтного слова.
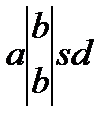 K5=absd(2, 3)
K5=absd(2, 3)
Построенное конфликтное слово к5 является номером цепочек 2 и 3, которые были выявлены ранее. Поэтому слово к5 исключается из списка конфликтных слов.
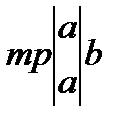 K6=mpab(2, 4)
K6=mpab(2, 4)
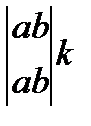 K7=abk(2, 7)
K7=abk(2, 7)
Если список конфликтных слов конечен, то на его основе формируется расширенный список конфликтных слов, каждый элемент списка имеет специальную структуру:
| Kij | N |
где Kij- - i – ое конфликтное слово, построенное на j – ом уровне, N – номера конфликтующих продукций
Кроме конфликтных слов, в списке добавляются образцы продукций, а также элементы списка имеют структуру:
| 0i | j |
, где 0i – образец, i - номер продукции
Расширенный список конфликтных слов упорядочивается по длине его элементов
L={Kmax, Kmin, 0max, …., 0min}
Пусть задано продукционное исчисление B, в котором все продукции являются активными:

Определим список конфликтных слов и на его основе синтезируем расширенный список вхождений L’
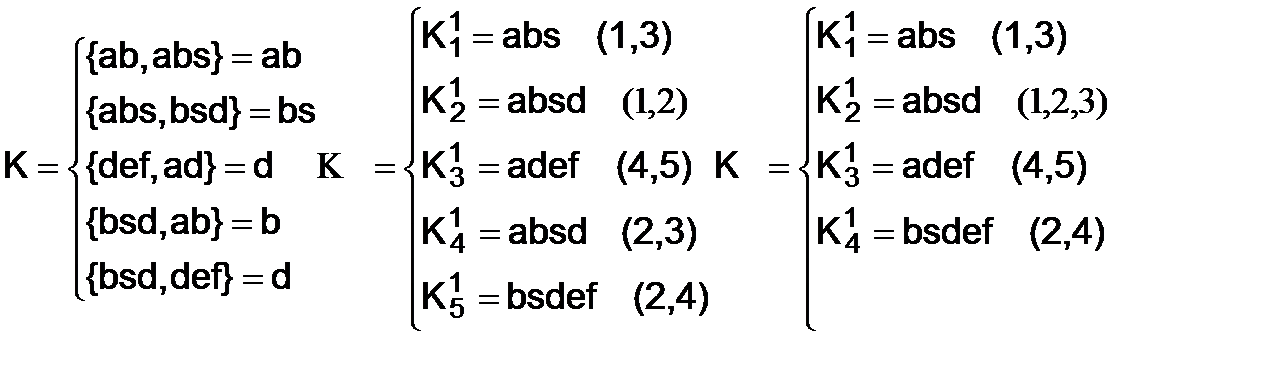
Анализ конфликтных слов 1-ого уровня в соответствии с (1а) выявляет ситуации их попарного пересечения, что обуславливает добавление конфликтных слов 2-ого уровня.

L’= 
Разработка стратегии ИЛИ- параллельных продукционных выводов
Под стратегией ИЛИ- параллельных продукционных выводов условимся понимать следующие способы инициализации продукций:
1. неконфликтующая продукция однократно применима к обрабатываемому слову с позиции минимального вхождения образца;
2. конфликтующие продукции равноправно применимы к обрабатываемому слову по его копиям;
3. отсутствие вхождений всех образцов в обрабатываемое слово является признаком прекращения процесса вывода.
Равноправное срабатывание конфликтующих продукций достигается за счет введения неединичного множества исполнителей продукций по одному на каждую копию S. Количество исполнителей определяется по максимальному количеству конфликтующих продукций в L’, т.е. однозначно определяется составом продукций исчисления. Поэтому термин «недетерминированность» для ИЛИ-вывода условимся уточнять как «равноправная многозначность». Следствием данных способов инициализации продукций является последовательное срабатывание неконфликтующих продукций с позиций минимального вхождения их образцов.
Пусть для продукционного исчисления B, в котором все продукции являются активными:

определен расширенный список L’ вхождений
L’=
и пусть обрабатываемое слово имеет вид S=absdbs#adefdefabs, где # - метасимвол, не принадлежащий рабочему алфавиту Â и трактуемый как разделитель. Следовательно, S=S1#S2, где S1=absdbs, S2=adefdefabs.
Особенность ИЛИ-параллельного вывода определяется последовательной обработкой нескольких входных слов, объединенных метасимволом # в обрабатываемое слово S. Последовательная обработка объясняется трактовкой обрабатываемого слова S как конструктивного объекта, т.е. объекта имеющего единую внутренную систему координат /7/ с общим началом для всех входных слов Si, объединенных в S.
Рассмотрим ИЛИ-параллельный вывод над первым словом S1.

Рассмотрим ИЛИ-параллельный вывод над вторым словом S2
| t0 t1 t2 t3 t4 t5 t6 t7 t8 t9 t10 t11 t12 t13 |

Практическая ценность ИЛИ-параллельного вывода определяется тем, что ярус ИЛИ-дерева является срезом альтернативных путей вывода, что обуславливает уменьшение длительности генерации дерева в целом. Во-вторых, определение максимальной ширины яруса ИЛИ-дерева, равной максимальному количеству конфликтующих продукций, не входит в цикл работы модифицированной машины вывода, что обуславливает универсальность ИЛИ-параллельной стратегии вывода.
Лекция 15
АРБИТРЫ И ПРОЦЕСС АРБИТРАЖА
Работа современных операционных систем опирается на многозадачный (многопоточный) режим планирования, диспетчеризации и выполнения задач или процессов в соответствии с определенными стратегиями обслуживания. Одновременное выполнение нескольких задача или нескольких потоков ограничивается невозможностью одновременного их обращения к неразделяемым ресурсам (процессор, память, система прерываний, каналы прямого доступа к памяти, системные библиотеки и т.д.). В связи с этим на аппаратно-программном уровне возникает необходимость в динамическом управлении доступом к неразделяемым ресурсам со стороны одновременно выполняющихся задач или потоков. Для разрешения возникающих конфликтов за общий неразделяемый ресурс вводится специальный системный процесс арбитража и диспетчеризации, который может иметь аппаратную или программную реализации. В первом случае устройство-арбитр осуществляет обработку асинхронно поступающих запросов от устройств, во втором случае программа-арбитр, входящая в состав системного ПО, осуществляет диспетчеризацию обращений от системных или прикладных программ.
Арбитр – это самостоятельный функциональный узел (рис.1), который обрабатывает k-битовый вектор запросов от устройств и посылает им kразрядный вектор подтверждений с единственной логической единицей, соответствующей приоритетному каналу.

Рис. 1 Представление арбитра как «черного» ящика
Одним из возможных путей повышения гибкости арбитра является периодическая программная перестройка его приоритетной структуры. Операционная система, например, через каждую миллисекунду меняет местами приоритеты каналов по определенному алгоритму. Поэтому низкоприоритетные каналы периодически становятся высокоприоритетными, и наоборот. При хаотическом «перемешивании» приоритетов каналов все они оказываются в равных условиях. При целенаправленном перемешивании приоритетность в целом сохраняется, но эффекта «грубого оттеснения» нет..
Среди арбитров наибольший интерес представляют арбитры с изменяемым законом приоритетов запросов. Изменяемый закон необходим для предоставления доступа к общему ресурсу всем нуждающимся задачам или устройствам.
Отличительная особенность программируемых решетчатых арбитров заключается в том, что закон арбитража зависит не только от количества запросов, но и от структурного соотношения между ними.
На рис. 2, рис.3, рис. 4 представлены схемы программируемых арбитров, реализующих 128 различных приоритетных соотношений в 8-разрядном векторе запросов в зависимости от 28-разрядного кода управляющего регистра приоритетов Q. Каждому элементарной ячейке арбитра соответствует один разряд Qi программно-доступного регистра приоритетов (на рис.2, 3, 4 не показан). При отсутствии конфликтов элементарная ячейка транслирует сигналы а и b на выходы e и d без изменения. При конфликте элементарная ячейка «руководствуется указаниями» бита управляющего разряда Qi. Доказано, что любой конфликтной ситуации на входах арбитра независимо от кода в регистре приоритетов на выходы пройдет только один сигнал. Перестройка структуры приоритетов достигается изменением кода в управляющем регистре Q.
Рис.2 Структура программируемого арбитра №1
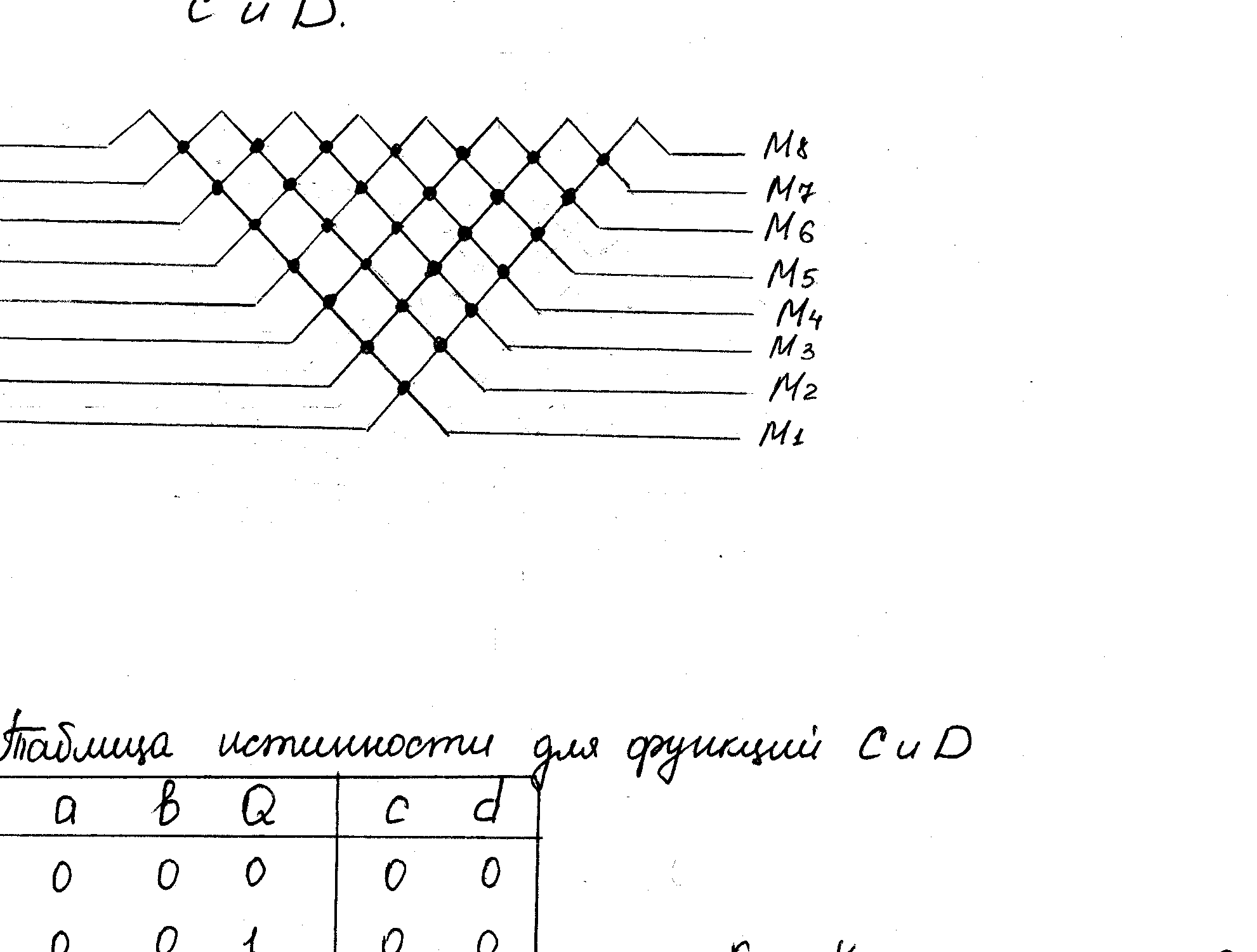
Рис.3 Структура программируемого арбитра №2
Рис.4 Структура программируемого арбитра №3
Взаимоотношения между любой парой конкурирующих запросов однозначно определяются битом Qi управляющего регистра в соответствии таблицей работы, имеющей два варианта формирования выходов c-d, c’-d’ (табл.) элементарной ячейки (рис.5).
Рис.5 Схема элементарной конфликтной ячейки
Таблица
| a | b | Q | c | d | c’ | d’ |
Арбитр устраняет любые конфликты при любом коде в регистре, однако в зависимости от кода он может быть настроен либо на один из жестких, либо на один из гибких режимов.
Пусть, например, требуется обеспечить следующую приоритетность запросов для арбитра на рис. 2
К3-> К2-> К8-> К6-> К7-> К1-> К5-> К4.
Стрелка в такой записи направлена от более приоритетного входа к менее приоритетному. Для обеспечения указанного режима код в управляющем регистре должен настроить узловые схемы следующим образом:
КЗ-> К2, К3-> К8, К3-> К6, К3-> К7, КЗ-> К1, КЗ-> К5, К3-> К4*,
К2-> К8, К2-> К6, К2-> К7, К2-> К1, К2-> К5, К2-> К4,
К8-> К6, К8-> К7, К8-> К1, К8-> К5, К8-> К4,
К6-> К7, К6-> К1, К6-> К5, К6-> К4,
К7-> К1, К7-> К5, K7-> K4,
К1-> К5, К1-> К4,
К5-> К4.
Каждое из этих условий задается значением соответствующего бита в управляющем 28-разрядном регистре. Аналогично можно задать любой жесткий приоритетный порядок между каналами. Число таких режимов равно числу перестановок между номерами каналов Р8=40 320. Однако это число не исчерпывает все возможные режимы работы устройства. Действительно, поскольку число управляющих бит в арбитре в данном примере составляет С8 = 28, то возможны 228=268 435 456 вариантов настройки, которые, за исключением уже рассмотренных, характеризуются гибким распределением приоритетов между каналами.
Смысл гибких режимов состоит в том, что приоритет между каналами определяется не только кодом в управляющем регистре, но также зависит от числа поступивших запросов и их распределения по входам арбитра. Если в предыдущем примере изменить значение только одного бита в управляющем коде, а именно бита, определяющего взаимоотношения между входами КЗ и К4, то условие К3-> К4, помеченное ранее знаком *, изменится на противоположное. К4-> КЗ («шестерка бьет туза»). Такое изменение приводит к получению одного из гибких режимов.
Предположим, что задана исходная система приоритетов, но К4-> КЗ. Пусть запросы ступили на все входы К1—К8 и только на входы К1—К4. Для первого вектора запросов на рис.6 а) полужирными линиями показаны траектории распространения запросных сигналов через арбитр. Из рисунка сигнала видно, что при взаимодействии запросов по входам К4 и К5 побеждает К5, так как соответствующая узловая схема решетчатой структуры настроена на приоритетную передачу сигнала, поступившего на вход К5. Для вектора запросов, имеющих логические единицы на входах К1—К4, приоритетным будем запрос К3, что отражено на рис.6 б)
а) при запросах К1-К8 б) при запросах К1-К4
Рис.6 Траектории распространения запросов в арбитре.
Другая особенность решетчатых программируемых арбитров состоит в том, схемы являются двунаправленными, что позволяет рассматривать 6 различных вариантов структур арбитров.
Комплементарным способом изучения работы программируемого арбитра является определение по заданному значению управляющего регистра Q системы приоритетов, складывающейся в арбитре.
Рассмотрим структуры четырехвходовых арбитров, для которых заданы значения Q1=111111 и Q2=100000 соответственно (рис.7).

Рис. 7 Программируемый арбитр с управляющим регистром
Установление приоритетов между запросами осуществляется следующим образом. Для запросов З2 и З3 в левом арбитре Q1=1, поэтому приоритет отдается З3, то есть З3 ® З2. Для запросов З1 и З3 в левом арбитре Q1=1, поэтому приоритет отдается З3, то есть З3 ® З1 и т.д. В целом для левого арбитра устанавливается система приоритетов 34®33®32®31, а для правого арбитра –система приоритетов 31®33®32®34
|
|